 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-Optical Segmentation via Diffractive Neural Networks for Autonomous Driving
Feb 07, 2026Semantic segmentation and lane detection are crucial tasks in autonomous driving systems. Conventional approaches predominantly rely on deep neural networks (DNNs), which incur high energy costs due to extensive analog-to-digital conversions and large-scale image computations required for low-latency, real-time responses. Diffractive optical neural networks (DONNs) have shown promising advantages over conventional DNNs on digital or optoelectronic computing platforms in energy efficiency. By performing all-optical image processing via light diffraction at the speed of light, DONNs save computation energy costs while reducing the overhead associated with analog-to-digital conversions by all-optical encoding and computing. In this work, we propose a novel all-optical computing framework for RGB image segmentation and lane detection in autonomous driving applications. Our experimental results demonstrate the effectiveness of the DONN system for image segmentation on the CityScapes dataset. Additionally, we conduct case studies on lane detection using a customized indoor track dataset and simulated driving scenarios in CARLA, where we further evaluate the model's generalizability under diverse environmental conditions.
From Essence to Defense: Adaptive Semantic-aware Watermarking for Embedding-as-a-Service Copyright Protection
Dec 18, 2025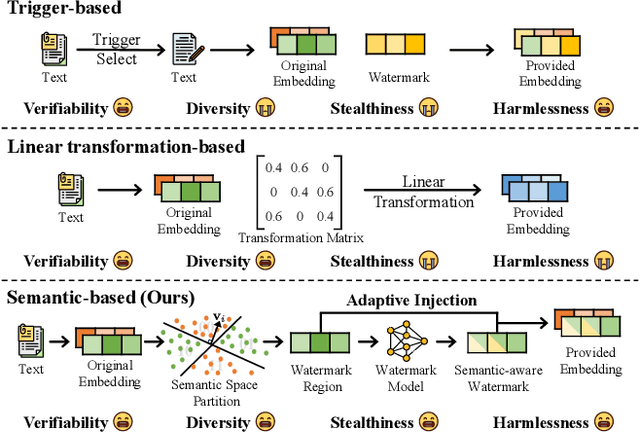



Benefiting from the superior capabilities of large language models in natural language understanding and generation, Embeddings-as-a-Service (EaaS) has emerged as a successful commercial paradigm on the web platform. However, prior studies have revealed that EaaS is vulnerable to imitation attacks. Existing methods protect the intellectual property of EaaS through watermarking techniques, but they all ignore the most important properties of embedding: semantics, resulting in limited harmlessness and stealthiness. To this end, we propose SemMark, a novel semantic-based watermarking paradigm for EaaS copyright protection. SemMark employs locality-sensitive hashing to partition the semantic space and inject semantic-aware watermarks into specific regions, ensuring that the watermark signals remain imperceptible and diverse. In addition, we introduce the adaptive watermark weight mechanism based on the local outlier factor to preserve the original embedding distribution. Furthermore, we propose Detect-Sampling and Dimensionality-Reduction attacks and construct four scenarios to evaluate the watermarking method. Extensive experiments are conducted on four popular NLP datasets, and SemMark achieves superior verifiability, diversity, stealthiness, and harmlessness.
DualGuard: Dual-stream Large Language Model Watermarking Defense against Paraphrase and Spoofing Attack
Dec 18, 2025With the rapid development of cloud-based services, large language models (LLMs) have become increasingly accessible through various web platforms. However, this accessibility has also led to growing risks of model abuse. LLM watermarking has emerged as an effective approach to mitigate such misuse and protect intellectual property. Existing watermarking algorithms, however, primarily focus on defending against paraphrase attacks while overlooking piggyback spoofing attacks, which can inject harmful content, compromise watermark reliability, and undermine trust in attribution. To address this limitation, we propose DualGuard, the first watermarking algorithm capable of defending against both paraphrase and spoofing attacks. DualGuard employs the adaptive dual-stream watermarking mechanism, in which two complementary watermark signals are dynamically injected based on the semantic content. This design enables DualGuard not only to detect but also to trace spoofing attacks, thereby ensuring reliable and trustworthy watermark detection. Extensive experiments conducted across multiple datasets and language models demonstrate that DualGuard achieves excellent detectability, robustness, traceability, and text quality, effectively advancing the state of LLM watermarking for real-world applications.
PerSphere: A Comprehensive Framework for Multi-Faceted Perspective Retrieval and Summarization
Dec 17, 2024



As online platforms and recommendation algorithms evolve, people are increasingly trapped in echo chambers, leading to biased understandings of various issues. To combat this issue, we have introduced PerSphere, a benchmark designed to facilitate multi-faceted perspective retrieval and summarization, thus breaking free from these information silos. For each query within PerSphere, there are two opposing claims, each supported by distinct, non-overlapping perspectives drawn from one or more documents. Our goal is to accurately summarize these documents, aligning the summaries with the respective claims and their underlying perspectives. This task is structured as a two-step end-to-end pipeline that includes comprehensive document retrieval and multi-faceted summarization. Furthermore, we propose a set of metrics to evaluate the comprehensiveness of the retrieval and summarization content. Experimental results on various counterparts for the pipeline show that recent models struggle with such a complex task. Analysis shows that the main challenge lies in long context and perspective extraction, and we propose a simple but effective multi-agent summarization system, offering a promising solution to enhance performance on PerSphere.
PAFFA: Premeditated Actions For Fast Agents
Dec 10, 2024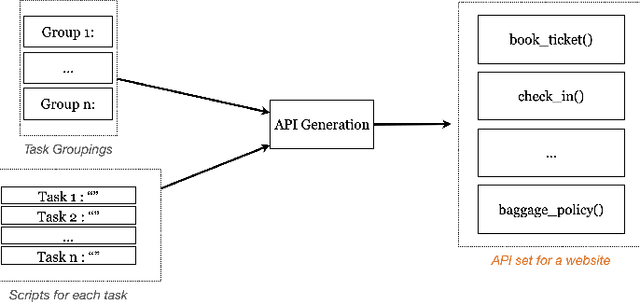
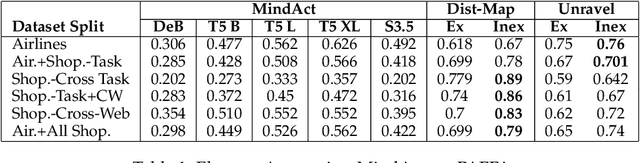
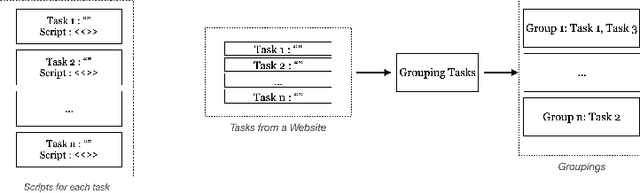
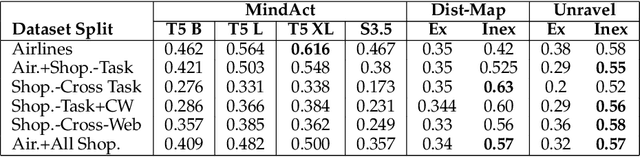
Modern AI assistants have made significant progress in natural language understanding and API/tool integration, with emerging efforts to incorporate diverse interfaces (such as Web interfaces) for enhanced scalability and functionality. However, current approaches that heavily rely on repeated LLM-driven HTML parsing are computationally expensive and error-prone, particularly when handling dynamic web interfaces and multi-step tasks. To overcome these challenges, we introduce PAFFA (Premeditated Actions For Fast Agents), a framework designed to enhance web interaction capabilities through an Action API Library of reusable, verified browser interaction functions. By pre-computing interaction patterns and employing two core methodologies - "Dist-Map" for task-agnostic element distillation and "Unravel" for incremental page-wise exploration - PAFFA reduces inference calls by 87% while maintaining robust performance even as website structures evolve. This framework accelerates multi-page task execution and offers a scalable solution to advance autonomous web agent research.
Task Calibration: Calibrating Large Language Models on Inference Tasks
Oct 24, 2024Large language models (LLMs) have exhibited impressive zero-shot performance on inference tasks. However, LLMs may suffer from spurious correlations between input texts and output labels, which limits LLMs' ability to reason based purely on general language understanding. In other words, LLMs may make predictions primarily based on premise or hypothesis, rather than both components. To address this problem that may lead to unexpected performance degradation, we propose task calibration (TC), a zero-shot and inference-only calibration method inspired by mutual information which recovers LLM performance through task reformulation. TC encourages LLMs to reason based on both premise and hypothesis, while mitigating the models' over-reliance on individual premise or hypothesis for inference. Experimental results show that TC achieves a substantial improvement on 13 inference tasks in the zero-shot setup. We further validate the effectiveness of TC in few-shot setups and various natural language understanding tasks. Further analysis indicates that TC is also robust to prompt templates and has the potential to be integrated with other calibration methods.
A System and Benchmark for LLM-based Q&A on Heterogeneous Data
Sep 10, 2024In many industrial settings, users wish to ask questions whose answers may be found in structured data sources such as a spreadsheets, databases, APIs, or combinations thereof. Often, the user doesn't know how to identify or access the right data source. This problem is compounded even further if multiple (and potentially siloed) data sources must be assembled to derive the answer. Recently, various Text-to-SQL applications that leverage Large Language Models (LLMs) have addressed some of these problems by enabling users to ask questions in natural language. However, these applications remain impractical in realistic industrial settings because they fail to cope with the data source heterogeneity that typifies such environments. In this paper, we address heterogeneity by introducing the siwarex platform, which enables seamless natural language access to both databases and APIs. To demonstrate the effectiveness of siwarex, we extend the popular Spider dataset and benchmark by replacing some of its tables by data retrieval APIs. We find that siwarex does a good job of coping with data source heterogeneity. Our modified Spider benchmark will soon be available to the research community
KModels: Unlocking AI for Business Applications
Sep 08, 2024
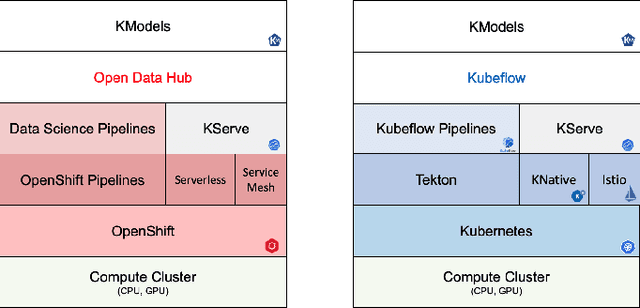


As artificial intelligence (AI) continues to rapidly advance, there is a growing demand to integrate AI capabilities into existing business applications. However, a significant gap exists between the rapid progress in AI and how slowly AI is being embedded into business environments. Deploying well-performing lab models into production settings, especially in on-premise environments, often entails specialized expertise and imposes a heavy burden of model management, creating significant barriers to implementing AI models in real-world applications. KModels leverages proven libraries and platforms (Kubeflow Pipelines, KServe) to streamline AI adoption by supporting both AI developers and consumers. It allows model developers to focus solely on model development and share models as transportable units (Templates), abstracting away complex production deployment concerns. KModels enables AI consumers to eliminate the need for a dedicated data scientist, as the templates encapsulate most data science considerations while providing business-oriented control. This paper presents the architecture of KModels and the key decisions that shape it. We outline KModels' main components as well as its interfaces. Furthermore, we explain how KModels is highly suited for on-premise deployment but can also be used in cloud environments. The efficacy of KModels is demonstrated through the successful deployment of three AI models within an existing Work Order Management system. These models operate in a client's data center and are trained on local data, without data scientist intervention. One model improved the accuracy of Failure Code specification for work orders from 46% to 83%, showcasing the substantial benefit of accessible and localized AI solutions.
Multi-Treatment Multi-Task Uplift Modeling for Enhancing User Growth
Aug 23, 2024



As a key component in boosting online user growth, uplift modeling aims to measure individual user responses (e.g., whether to play the game) to various treatments, such as gaming bonuses, thereby enhancing business outcomes. However, previous research typically considers a single-task, single-treatment setting, where only one treatment exists and the overall treatment effect is measured by a single type of user response. In this paper, we propose a Multi-Treatment Multi-Task (MTMT) uplift network to estimate treatment effects in a multi-task scenario. We identify the multi-treatment problem as a causal inference problem with a tiered response, comprising a base effect (from offering a treatment) and an incremental effect (from offering a specific type of treatment), where the base effect can be numerically much larger than the incremental effect. Specifically, MTMT separately encodes user features and treatments. The user feature encoder uses a multi-gate mixture of experts (MMOE) network to encode relevant user features, explicitly learning inter-task relations. The resultant embeddings are used to measure natural responses per task. Furthermore, we introduce a treatment-user feature interaction module to model correlations between each treatment and user feature. Consequently, we separately measure the base and incremental treatment effect for each task based on the produced treatment-aware representations. Experimental results based on an offline public dataset and an online proprietary dataset demonstrate the effectiveness of MTMT in single/multi-treatment and single/multi-task settings. Additionally, MTMT has been deployed in our gaming platform to improve user experience.
MapTune: Advancing ASIC Technology Mapping via Reinforcement Learning Guided Library Tuning
Jul 25, 2024
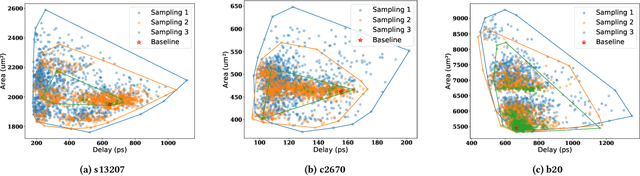
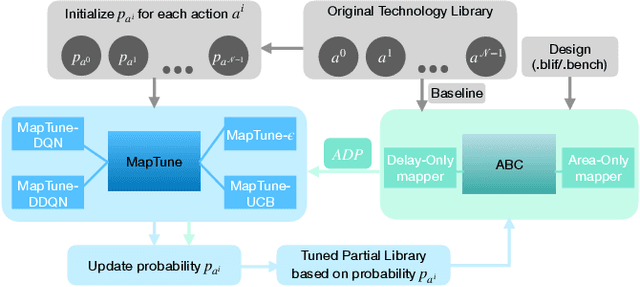
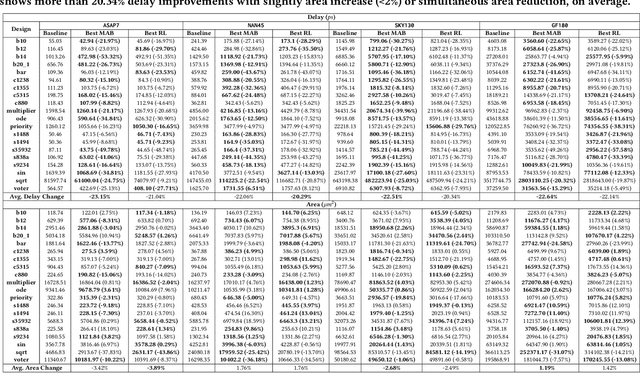
Technology mapping involves mapping logical circuits to a library of cells. Traditionally, the full technology library is used, leading to a large search space and potential overhead. Motivated by randomly sampled technology mapping case studies, we propose MapTune framework that addresses this challenge by utilizing reinforcement learning to make design-specific choices during cell selection. By learning from the environment, MapTune refines the cell selection process, resulting in a reduced search space and potentially improved mapping quality. The effectiveness of MapTune is evaluated on a wide range of benchmarks, different technology libraries and technology mappers. The experimental results demonstrate that MapTune achieves higher mapping accuracy and reducing delay/area across diverse circuit designs, technology libraries and mappers. The paper also discusses the Pareto-Optimal exploration and confirms the perpetual delay-area trade-off. Conducted on benchmark suites ISCAS 85/89, ITC/ISCAS 99, VTR8.0 and EPFL benchmarks, the post-technology mapping and post-sizing quality-of-results (QoR) have been significantly improved, with average Area-Delay Product (ADP) improvement of 22.54\% among all different exploration settings in MapTune. The improvements are consistently remained for four different technologies (7nm, 45nm, 130nm, and 180 nm) and two different mappers.