 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving the Inverse Alignment Problem for Efficient RLHF
Dec 13, 2024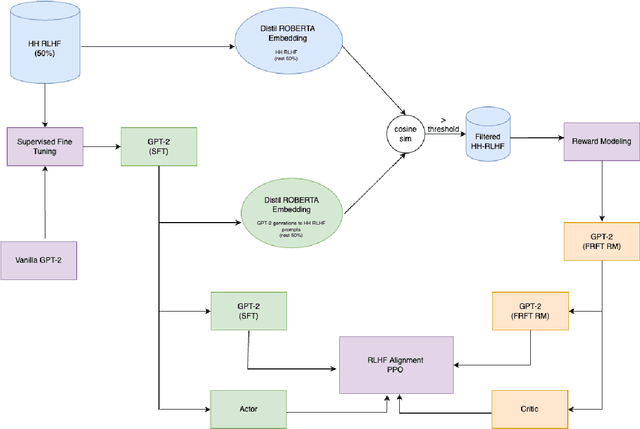


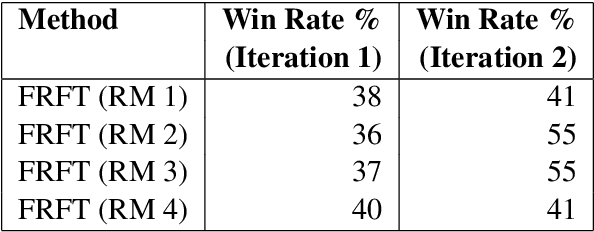
Collecting high-quality preference datasets for reinforcement learning from human feedback (RLHF) is resource-intensive and challenging. As a result, researchers often train reward models on extensive offline datasets which aggregate diverse generation sources and scoring/alignment policies. We hypothesize that this aggregation has an averaging effect on reward model scores, which limits signal and impairs the alignment process. Inspired by the field of inverse RL, we define the 'inverse alignment problem' in language model training, where our objective is to optimize the critic's reward for a fixed actor and a fixed offline preference dataset. We hypothesize that solving the inverse alignment problem will improve reward model quality by providing clearer feedback on the policy's current behavior. To that end, we investigate whether repeatedly fine-tuning a reward model on subsets of the offline preference dataset aligned with a periodically frozen policy during RLHF improves upon vanilla RLHF. Our empirical results demonstrate that this approach facilitates superior alignment and faster convergence compared to using an unaligned or out-of-distribution reward model relative to the LLM policy.
PAFFA: Premeditated Actions For Fast Agents
Dec 10, 2024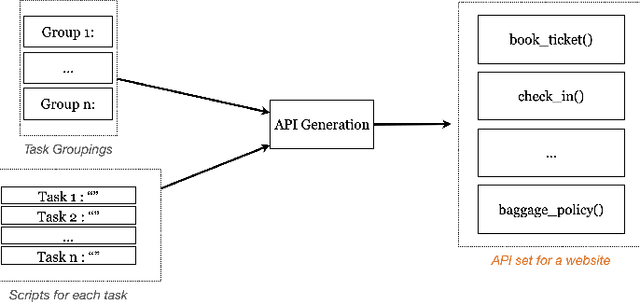
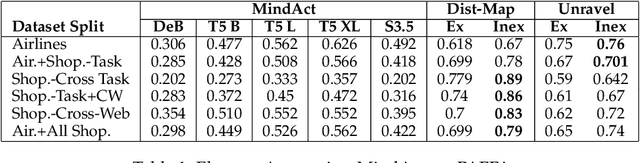
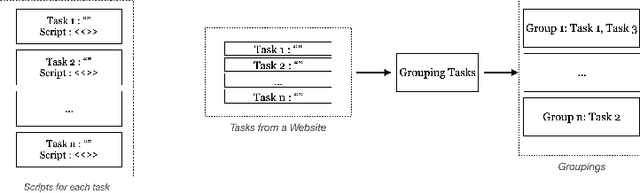
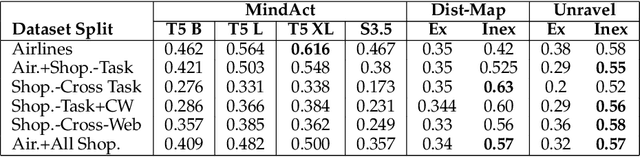
Modern AI assistants have made significant progress in natural language understanding and API/tool integration, with emerging efforts to incorporate diverse interfaces (such as Web interfaces) for enhanced scalability and functionality. However, current approaches that heavily rely on repeated LLM-driven HTML parsing are computationally expensive and error-prone, particularly when handling dynamic web interfaces and multi-step tasks. To overcome these challenges, we introduce PAFFA (Premeditated Actions For Fast Agents), a framework designed to enhance web interaction capabilities through an Action API Library of reusable, verified browser interaction functions. By pre-computing interaction patterns and employing two core methodologies - "Dist-Map" for task-agnostic element distillation and "Unravel" for incremental page-wise exploration - PAFFA reduces inference calls by 87% while maintaining robust performance even as website structures evolve. This framework accelerates multi-page task execution and offers a scalable solution to advance autonomous web agent research.