 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA System and Benchmark for LLM-based Q&A on Heterogeneous Data
Sep 10, 2024In many industrial settings, users wish to ask questions whose answers may be found in structured data sources such as a spreadsheets, databases, APIs, or combinations thereof. Often, the user doesn't know how to identify or access the right data source. This problem is compounded even further if multiple (and potentially siloed) data sources must be assembled to derive the answer. Recently, various Text-to-SQL applications that leverage Large Language Models (LLMs) have addressed some of these problems by enabling users to ask questions in natural language. However, these applications remain impractical in realistic industrial settings because they fail to cope with the data source heterogeneity that typifies such environments. In this paper, we address heterogeneity by introducing the siwarex platform, which enables seamless natural language access to both databases and APIs. To demonstrate the effectiveness of siwarex, we extend the popular Spider dataset and benchmark by replacing some of its tables by data retrieval APIs. We find that siwarex does a good job of coping with data source heterogeneity. Our modified Spider benchmark will soon be available to the research community
PresAIse, A Prescriptive AI Solution for Enterprises
Feb 13, 2024Prescriptive AI represents a transformative shift in decision-making, offering causal insights and actionable recommendations. Despite its huge potential, enterprise adoption often faces several challenges. The first challenge is caused by the limitations of observational data for accurate causal inference which is typically a prerequisite for good decision-making. The second pertains to the interpretability of recommendations, which is crucial for enterprise decision-making settings. The third challenge is the silos between data scientists and business users, hindering effective collaboration. This paper outlines an initiative from IBM Research, aiming to address some of these challenges by offering a suite of prescriptive AI solutions. Leveraging insights from various research papers, the solution suite includes scalable causal inference methods, interpretable decision-making approaches, and the integration of large language models (LLMs) to bridge communication gaps via a conversation agent. A proof-of-concept, PresAIse, demonstrates the solutions' potential by enabling non-ML experts to interact with prescriptive AI models via a natural language interface, democratizing advanced analytics for strategic decision-making.
Constrained Prescriptive Trees via Column Generation
Jul 20, 2022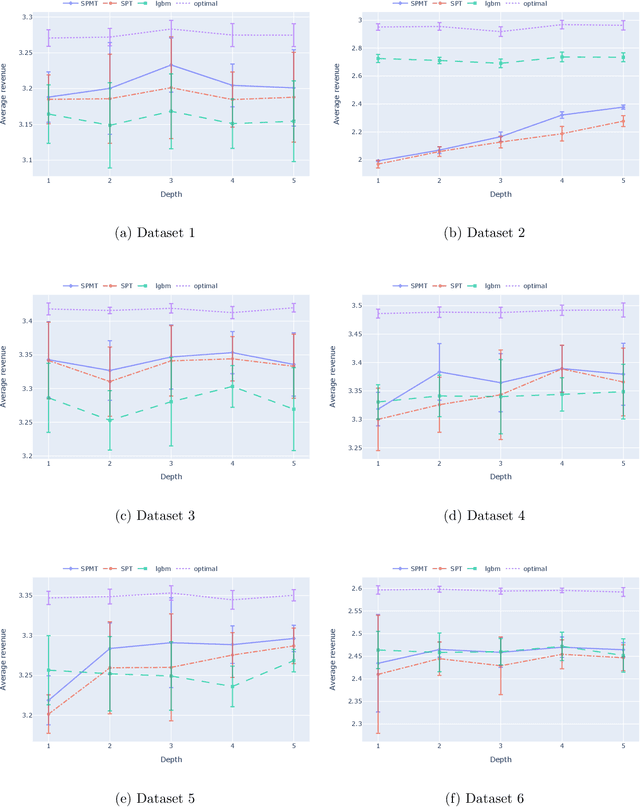

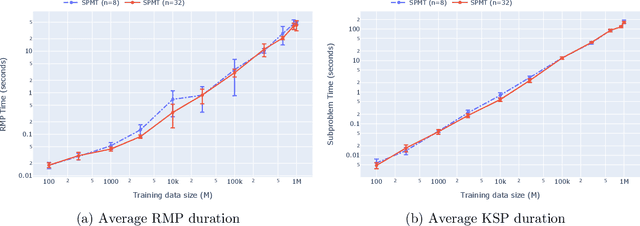
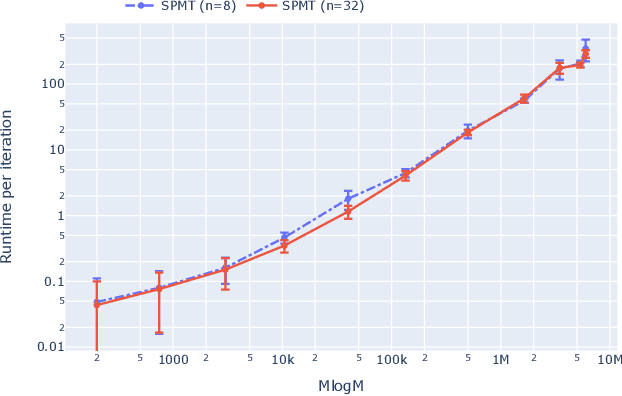
With the abundance of available data, many enterprises seek to implement data-driven prescriptive analytics to help them make informed decisions. These prescriptive policies need to satisfy operational constraints, and proactively eliminate rule conflicts, both of which are ubiquitous in practice. It is also desirable for them to be simple and interpretable, so they can be easily verified and implemented. Existing approaches from the literature center around constructing variants of prescriptive decision trees to generate interpretable policies. However, none of the existing methods are able to handle constraints. In this paper, we propose a scalable method that solves the constrained prescriptive policy generation problem. We introduce a novel path-based mixed-integer program (MIP) formulation which identifies a (near) optimal policy efficiently via column generation. The policy generated can be represented as a multiway-split tree which is more interpretable and informative than a binary-split tree due to its shorter rules. We demonstrate the efficacy of our method with extensive experiments on both synthetic and real datasets.