 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRAL: Symbolic LLM Planning via Grounded and Reflective Search
Dec 29, 2025Large Language Models (LLMs) often falter at complex planning tasks that require exploration and self-correction, as their linear reasoning process struggles to recover from early mistakes. While search algorithms like Monte Carlo Tree Search (MCTS) can explore alternatives, they are often ineffective when guided by sparse rewards and fail to leverage the rich semantic capabilities of LLMs. We introduce SPIRAL (Symbolic LLM Planning via Grounded and Reflective Search), a novel framework that embeds a cognitive architecture of three specialized LLM agents into an MCTS loop. SPIRAL's key contribution is its integrated planning pipeline where a Planner proposes creative next steps, a Simulator grounds the search by predicting realistic outcomes, and a Critic provides dense reward signals through reflection. This synergy transforms MCTS from a brute-force search into a guided, self-correcting reasoning process. On the DailyLifeAPIs and HuggingFace datasets, SPIRAL consistently outperforms the default Chain-of-Thought planning method and other state-of-the-art agents. More importantly, it substantially surpasses other state-of-the-art agents; for example, SPIRAL achieves 83.6% overall accuracy on DailyLifeAPIs, an improvement of over 16 percentage points against the next-best search framework, while also demonstrating superior token efficiency. Our work demonstrates that structuring LLM reasoning as a guided, reflective, and grounded search process yields more robust and efficient autonomous planners. The source code, full appendices, and all experimental data are available for reproducibility at the official project repository.
LLM Assisted Anomaly Detection Service for Site Reliability Engineers: Enhancing Cloud Infrastructure Resilience
Jan 28, 2025This paper introduces a scalable Anomaly Detection Service with a generalizable API tailored for industrial time-series data, designed to assist Site Reliability Engineers (SREs) in managing cloud infrastructure. The service enables efficient anomaly detection in complex data streams, supporting proactive identification and resolution of issues. Furthermore, it presents an innovative approach to anomaly modeling in cloud infrastructure by utilizing Large Language Models (LLMs) to understand key components, their failure modes, and behaviors. A suite of algorithms for detecting anomalies is offered in univariate and multivariate time series data, including regression-based, mixture-model-based, and semi-supervised approaches. We provide insights into the usage patterns of the service, with over 500 users and 200,000 API calls in a year. The service has been successfully applied in various industrial settings, including IoT-based AI applications. We have also evaluated our system on public anomaly benchmarks to show its effectiveness. By leveraging it, SREs can proactively identify potential issues before they escalate, reducing downtime and improving response times to incidents, ultimately enhancing the overall customer experience. We plan to extend the system to include time series foundation models, enabling zero-shot anomaly detection capabilities.
A System and Benchmark for LLM-based Q&A on Heterogeneous Data
Sep 10, 2024In many industrial settings, users wish to ask questions whose answers may be found in structured data sources such as a spreadsheets, databases, APIs, or combinations thereof. Often, the user doesn't know how to identify or access the right data source. This problem is compounded even further if multiple (and potentially siloed) data sources must be assembled to derive the answer. Recently, various Text-to-SQL applications that leverage Large Language Models (LLMs) have addressed some of these problems by enabling users to ask questions in natural language. However, these applications remain impractical in realistic industrial settings because they fail to cope with the data source heterogeneity that typifies such environments. In this paper, we address heterogeneity by introducing the siwarex platform, which enables seamless natural language access to both databases and APIs. To demonstrate the effectiveness of siwarex, we extend the popular Spider dataset and benchmark by replacing some of its tables by data retrieval APIs. We find that siwarex does a good job of coping with data source heterogeneity. Our modified Spider benchmark will soon be available to the research community
A Transformer-based Framework for Multivariate Time Series Representation Learning
Oct 08, 2020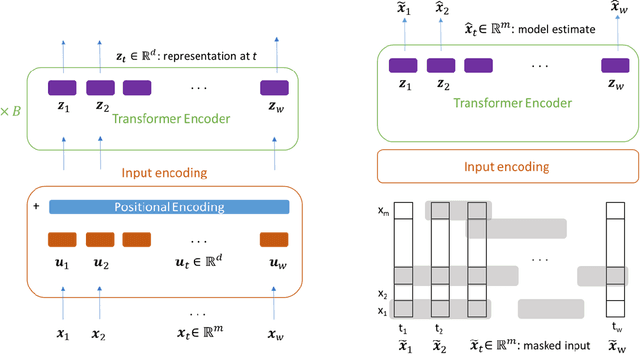
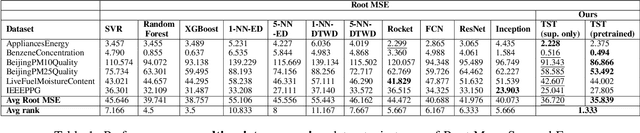
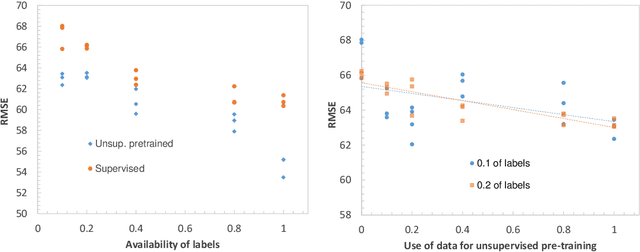
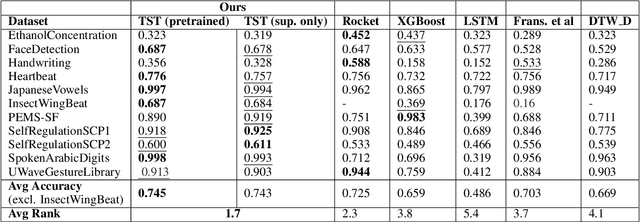
In this work we propose for the first time a transformer-based framework for unsupervised representation learning of multivariate time series. Pre-trained models can be potentially used for downstream tasks such as regression and classification, forecasting and missing value imputation. By evaluating our models on several benchmark datasets for multivariate time series regression and classification, we show that not only does our modeling approach represent the most successful method employing unsupervised learning of multivariate time series presented to date, but also that it exceeds the current state-of-the-art performance of supervised methods; it does so even when the number of training samples is very limited, while offering computational efficiency. Finally, we demonstrate that unsupervised pre-training of our transformer models offers a substantial performance benefit over fully supervised learning, even without leveraging additional unlabeled data, i.e., by reusing the same data samples through the unsupervised objective.