 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKModels: Unlocking AI for Business Applications
Sep 08, 2024As artificial intelligence (AI) continues to rapidly advance, there is a growing demand to integrate AI capabilities into existing business applications. However, a significant gap exists between the rapid progress in AI and how slowly AI is being embedded into business environments. Deploying well-performing lab models into production settings, especially in on-premise environments, often entails specialized expertise and imposes a heavy burden of model management, creating significant barriers to implementing AI models in real-world applications. KModels leverages proven libraries and platforms (Kubeflow Pipelines, KServe) to streamline AI adoption by supporting both AI developers and consumers. It allows model developers to focus solely on model development and share models as transportable units (Templates), abstracting away complex production deployment concerns. KModels enables AI consumers to eliminate the need for a dedicated data scientist, as the templates encapsulate most data science considerations while providing business-oriented control. This paper presents the architecture of KModels and the key decisions that shape it. We outline KModels' main components as well as its interfaces. Furthermore, we explain how KModels is highly suited for on-premise deployment but can also be used in cloud environments. The efficacy of KModels is demonstrated through the successful deployment of three AI models within an existing Work Order Management system. These models operate in a client's data center and are trained on local data, without data scientist intervention. One model improved the accuracy of Failure Code specification for work orders from 46% to 83%, showcasing the substantial benefit of accessible and localized AI solutions.
A Transformer-based Framework for Multivariate Time Series Representation Learning
Oct 08, 2020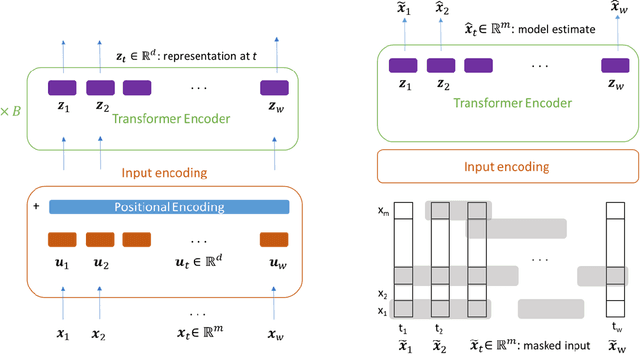
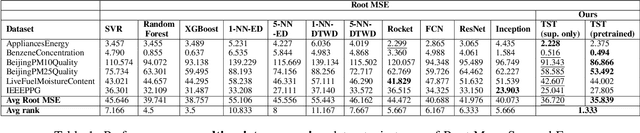
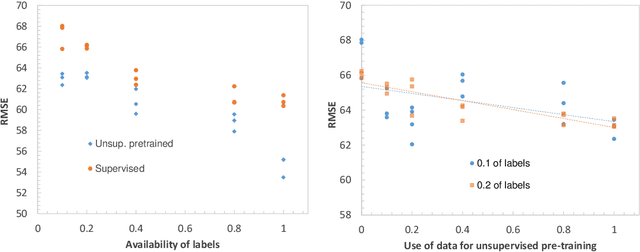
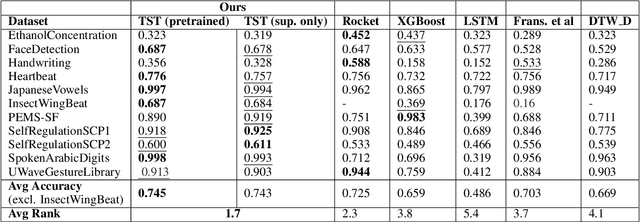
In this work we propose for the first time a transformer-based framework for unsupervised representation learning of multivariate time series. Pre-trained models can be potentially used for downstream tasks such as regression and classification, forecasting and missing value imputation. By evaluating our models on several benchmark datasets for multivariate time series regression and classification, we show that not only does our modeling approach represent the most successful method employing unsupervised learning of multivariate time series presented to date, but also that it exceeds the current state-of-the-art performance of supervised methods; it does so even when the number of training samples is very limited, while offering computational efficiency. Finally, we demonstrate that unsupervised pre-training of our transformer models offers a substantial performance benefit over fully supervised learning, even without leveraging additional unlabeled data, i.e., by reusing the same data samples through the unsupervised objective.