 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Differentiable Neural Forced Alignment via Soft Dynamic Programming
Jun 24, 2026Recent advances in sequence modeling have significantly improved ASR systems, bringing them close to human-level recognition accuracy and enhancing robustness across diverse acoustic conditions and languages. In contrast, Forced Alignment has not experienced comparable progress, and traditional HMM-GMM frameworks remain widely adopted and highly competitive. To address this gap, we propose an end-to-end, fully differentiable neural architecture specifically designed for phoneme alignment. The model consists of an encoder that processes the input signal and a decoder that produces alignment decisions. The encoder is structured into two complementary branches: one dedicated to phoneme identity verification and the other to phoneme boundary detection. The decoder is implemented as a trainable module based on differentiable soft dynamic programming. The entire system is optimized end-to-end using a novel contrastive loss that encourages clear separation between steady-state phoneme regions and transition boundaries. The proposed approach outperforms the current state of the art in phoneme alignment on hand-annotated English benchmarks, achieves strong word-level generalization results, and demonstrates generalization on unseen languages.
Set to Be Fair: Demographic Parity Constraints for Set-Valued Classification
Oct 06, 2025



Set-valued classification is used in multiclass settings where confusion between classes can occur and lead to misleading predictions. However, its application may amplify discriminatory bias motivating the development of set-valued approaches under fairness constraints. In this paper, we address the problem of set-valued classification under demographic parity and expected size constraints. We propose two complementary strategies: an oracle-based method that minimizes classification risk while satisfying both constraints, and a computationally efficient proxy that prioritizes constraint satisfaction. For both strategies, we derive closed-form expressions for the (optimal) fair set-valued classifiers and use these to build plug-in, data-driven procedures for empirical predictions. We establish distribution-free convergence rates for violations of the size and fairness constraints for both methods, and under mild assumptions we also provide excess-risk bounds for the oracle-based approach. Empirical results demonstrate the effectiveness of both strategies and highlight the efficiency of our proxy method.
KModels: Unlocking AI for Business Applications
Sep 08, 2024
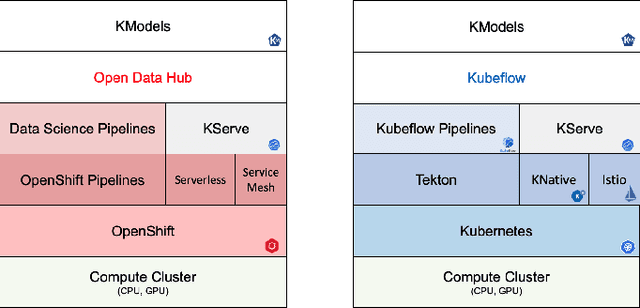


As artificial intelligence (AI) continues to rapidly advance, there is a growing demand to integrate AI capabilities into existing business applications. However, a significant gap exists between the rapid progress in AI and how slowly AI is being embedded into business environments. Deploying well-performing lab models into production settings, especially in on-premise environments, often entails specialized expertise and imposes a heavy burden of model management, creating significant barriers to implementing AI models in real-world applications. KModels leverages proven libraries and platforms (Kubeflow Pipelines, KServe) to streamline AI adoption by supporting both AI developers and consumers. It allows model developers to focus solely on model development and share models as transportable units (Templates), abstracting away complex production deployment concerns. KModels enables AI consumers to eliminate the need for a dedicated data scientist, as the templates encapsulate most data science considerations while providing business-oriented control. This paper presents the architecture of KModels and the key decisions that shape it. We outline KModels' main components as well as its interfaces. Furthermore, we explain how KModels is highly suited for on-premise deployment but can also be used in cloud environments. The efficacy of KModels is demonstrated through the successful deployment of three AI models within an existing Work Order Management system. These models operate in a client's data center and are trained on local data, without data scientist intervention. One model improved the accuracy of Failure Code specification for work orders from 46% to 83%, showcasing the substantial benefit of accessible and localized AI solutions.
HebDB: a Weakly Supervised Dataset for Hebrew Speech Processing
Jul 10, 2024We present HebDB, a weakly supervised dataset for spoken language processing in the Hebrew language. HebDB offers roughly 2500 hours of natural and spontaneous speech recordings in the Hebrew language, consisting of a large variety of speakers and topics. We provide raw recordings together with a pre-processed, weakly supervised, and filtered version. The goal of HebDB is to further enhance research and development of spoken language processing tools for the Hebrew language. Hence, we additionally provide two baseline systems for Automatic Speech Recognition (ASR): (i) a self-supervised model; and (ii) a fully supervised model. We present the performance of these two methods optimized on HebDB and compare them to current multi-lingual ASR alternatives. Results suggest the proposed method reaches better results than the evaluated baselines considering similar model sizes. Dataset, code, and models are publicly available under https://pages.cs.huji.ac.il/adiyoss-lab/HebDB/.
Tradition or Innovation: A Comparison of Modern ASR Methods for Forced Alignment
Jun 27, 2024



Forced alignment (FA) plays a key role in speech research through the automatic time alignment of speech signals with corresponding text transcriptions. Despite the move towards end-to-end architectures for speech technology, FA is still dominantly achieved through a classic GMM-HMM acoustic model. This work directly compares alignment performance from leading automatic speech recognition (ASR) methods, WhisperX and Massively Multilingual Speech Recognition (MMS), against a Kaldi-based GMM-HMM system, the Montreal Forced Aligner (MFA). Performance was assessed on the manually aligned TIMIT and Buckeye datasets, with comparisons conducted only on words correctly recognized by WhisperX and MMS. The MFA outperformed both WhisperX and MMS, revealing a shortcoming of modern ASR systems. These findings highlight the need for advancements in forced alignment and emphasize the importance of integrating traditional expertise with modern innovation to foster progress. Index Terms: forced alignment, phoneme alignment, word alignment