 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarelessWhisper: Turning Whisper into a Causal Streaming Model
Aug 17, 2025Automatic Speech Recognition (ASR) has seen remarkable progress, with models like OpenAI Whisper and NVIDIA Canary achieving state-of-the-art (SOTA) performance in offline transcription. However, these models are not designed for streaming (online or real-time) transcription, due to limitations in their architecture and training methodology. We propose a method to turn the transformer encoder-decoder model into a low-latency streaming model that is careless about future context. We present an analysis explaining why it is not straightforward to convert an encoder-decoder transformer to a low-latency streaming model. Our proposed method modifies the existing (non-causal) encoder to a causal encoder by fine-tuning both the encoder and decoder using Low-Rank Adaptation (LoRA) and a weakly aligned dataset. We then propose an updated inference mechanism that utilizes the fine-tune causal encoder and decoder to yield greedy and beam-search decoding, and is shown to be locally optimal. Experiments on low-latency chunk sizes (less than 300 msec) show that our fine-tuned model outperforms existing non-fine-tuned streaming approaches in most cases, while using a lower complexity. Additionally, we observe that our training process yields better alignment, enabling a simple method for extracting word-level timestamps. We release our training and inference code, along with the fine-tuned models, to support further research and development in streaming ASR.
How Does a Deep Neural Network Look at Lexical Stress?
Aug 10, 2025Despite their success in speech processing, neural networks often operate as black boxes, prompting the question: what informs their decisions, and how can we interpret them? This work examines this issue in the context of lexical stress. A dataset of English disyllabic words was automatically constructed from read and spontaneous speech. Several Convolutional Neural Network (CNN) architectures were trained to predict stress position from a spectrographic representation of disyllabic words lacking minimal stress pairs (e.g., initial stress WAllet, final stress exTEND), achieving up to 92% accuracy on held-out test data. Layerwise Relevance Propagation (LRP), a technique for CNN interpretability analysis, revealed that predictions for held-out minimal pairs (PROtest vs. proTEST ) were most strongly influenced by information in stressed versus unstressed syllables, particularly the spectral properties of stressed vowels. However, the classifiers also attended to information throughout the word. A feature-specific relevance analysis is proposed, and its results suggest that our best-performing classifier is strongly influenced by the stressed vowel's first and second formants, with some evidence that its pitch and third formant also contribute. These results reveal deep learning's ability to acquire distributed cues to stress from naturally occurring data, extending traditional phonetic work based around highly controlled stimuli.
Keyword Spotting with Hyper-Matched Filters for Small Footprint Devices
Aug 06, 2025


Open-vocabulary keyword spotting (KWS) refers to the task of detecting words or terms within speech recordings, regardless of whether they were included in the training data. This paper introduces an open-vocabulary keyword spotting model with state-of-the-art detection accuracy for small-footprint devices. The model is composed of a speech encoder, a target keyword encoder, and a detection network. The speech encoder is either a tiny Whisper or a tiny Conformer. The target keyword encoder is implemented as a hyper-network that takes the desired keyword as a character string and generates a unique set of weights for a convolutional layer, which can be considered as a keyword-specific matched filter. The detection network uses the matched-filter weights to perform a keyword-specific convolution, which guides the cross-attention mechanism of a Perceiver module in determining whether the target term appears in the recording. The results indicate that our system achieves state-of-the-art detection performance and generalizes effectively to out-of-domain conditions, including second-language (L2) speech. Notably, our smallest model, with just 4.2 million parameters, matches or outperforms models that are several times larger, demonstrating both efficiency and robustness.
UmbraTTS: Adapting Text-to-Speech to Environmental Contexts with Flow Matching
Jun 11, 2025Recent advances in Text-to-Speech (TTS) have enabled highly natural speech synthesis, yet integrating speech with complex background environments remains challenging. We introduce UmbraTTS, a flow-matching based TTS model that jointly generates both speech and environmental audio, conditioned on text and acoustic context. Our model allows fine-grained control over background volume and produces diverse, coherent, and context-aware audio scenes. A key challenge is the lack of data with speech and background audio aligned in natural context. To overcome the lack of paired training data, we propose a self-supervised framework that extracts speech, background audio, and transcripts from unannotated recordings. Extensive evaluations demonstrate that UmbraTTS significantly outperformed existing baselines, producing natural, high-quality, environmentally aware audios.
FlowTSE: Target Speaker Extraction with Flow Matching
May 20, 2025Target speaker extraction (TSE) aims to isolate a specific speaker's speech from a mixture using speaker enrollment as a reference. While most existing approaches are discriminative, recent generative methods for TSE achieve strong results. However, generative methods for TSE remain underexplored, with most existing approaches relying on complex pipelines and pretrained components, leading to computational overhead. In this work, we present FlowTSE, a simple yet effective TSE approach based on conditional flow matching. Our model receives an enrollment audio sample and a mixed speech signal, both represented as mel-spectrograms, with the objective of extracting the target speaker's clean speech. Furthermore, for tasks where phase reconstruction is crucial, we propose a novel vocoder conditioned on the complex STFT of the mixed signal, enabling improved phase estimation. Experimental results on standard TSE benchmarks show that FlowTSE matches or outperforms strong baselines.
Whisper in Medusa's Ear: Multi-head Efficient Decoding for Transformer-based ASR
Sep 24, 2024



Large transformer-based models have significant potential for speech transcription and translation. Their self-attention mechanisms and parallel processing enable them to capture complex patterns and dependencies in audio sequences. However, this potential comes with challenges, as these large and computationally intensive models lead to slow inference speeds. Various optimization strategies have been proposed to improve performance, including efficient hardware utilization and algorithmic enhancements. In this paper, we introduce Whisper-Medusa, a novel approach designed to enhance processing speed with minimal impact on Word Error Rate (WER). The proposed model extends the OpenAI's Whisper architecture by predicting multiple tokens per iteration, resulting in a 50% reduction in latency. We showcase the effectiveness of Whisper-Medusa across different learning setups and datasets.
WhisperNER: Unified Open Named Entity and Speech Recognition
Sep 12, 2024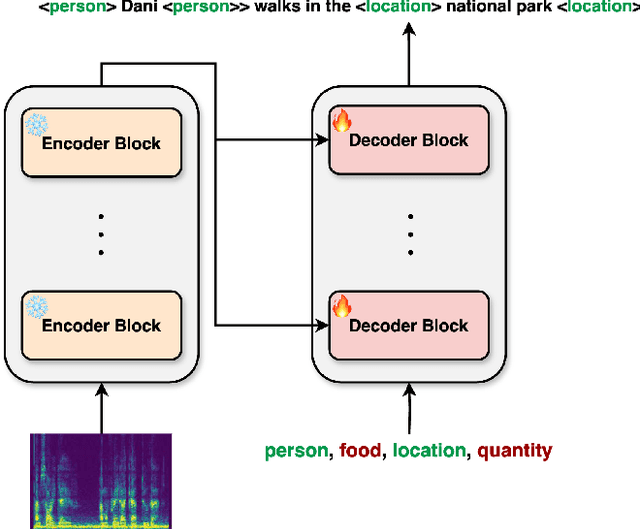
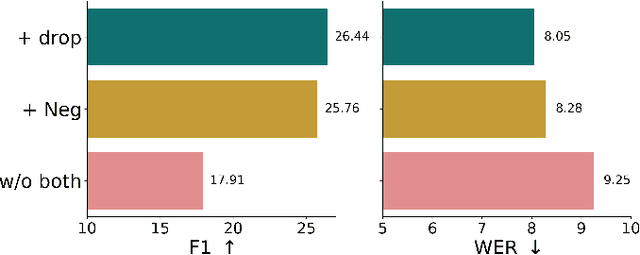
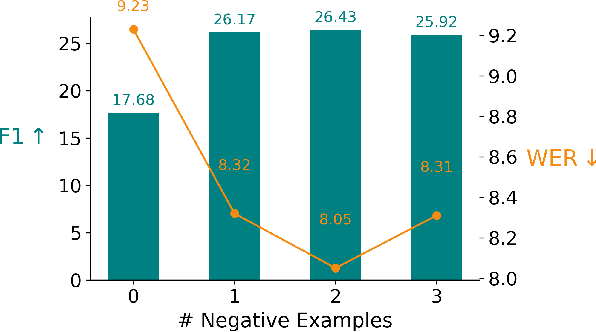

Integrating named entity recognition (NER) with automatic speech recognition (ASR) can significantly enhance transcription accuracy and informativeness. In this paper, we introduce WhisperNER, a novel model that allows joint speech transcription and entity recognition. WhisperNER supports open-type NER, enabling recognition of diverse and evolving entities at inference. Building on recent advancements in open NER research, we augment a large synthetic dataset with synthetic speech samples. This allows us to train WhisperNER on a large number of examples with diverse NER tags. During training, the model is prompted with NER labels and optimized to output the transcribed utterance along with the corresponding tagged entities. To evaluate WhisperNER, we generate synthetic speech for commonly used NER benchmarks and annotate existing ASR datasets with open NER tags. Our experiments demonstrate that WhisperNER outperforms natural baselines on both out-of-domain open type NER and supervised finetuning.
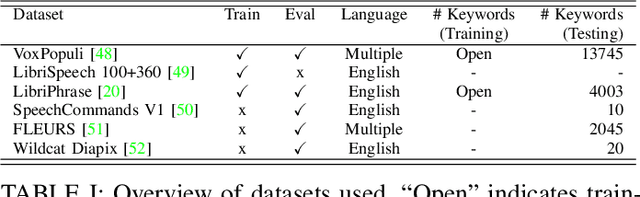
HebDB: a Weakly Supervised Dataset for Hebrew Speech Processing
Jul 10, 2024We present HebDB, a weakly supervised dataset for spoken language processing in the Hebrew language. HebDB offers roughly 2500 hours of natural and spontaneous speech recordings in the Hebrew language, consisting of a large variety of speakers and topics. We provide raw recordings together with a pre-processed, weakly supervised, and filtered version. The goal of HebDB is to further enhance research and development of spoken language processing tools for the Hebrew language. Hence, we additionally provide two baseline systems for Automatic Speech Recognition (ASR): (i) a self-supervised model; and (ii) a fully supervised model. We present the performance of these two methods optimized on HebDB and compare them to current multi-lingual ASR alternatives. Results suggest the proposed method reaches better results than the evaluated baselines considering similar model sizes. Dataset, code, and models are publicly available under https://pages.cs.huji.ac.il/adiyoss-lab/HebDB/.
Enhanced ASR Robustness to Packet Loss with a Front-End Adaptation Network
Jun 27, 2024



In the realm of automatic speech recognition (ASR), robustness in noisy environments remains a significant challenge. Recent ASR models, such as Whisper, have shown promise, but their efficacy in noisy conditions can be further enhanced. This study is focused on recovering from packet loss to improve the word error rate (WER) of ASR models. We propose using a front-end adaptation network connected to a frozen ASR model. The adaptation network is trained to modify the corrupted input spectrum by minimizing the criteria of the ASR model in addition to an enhancement loss function. Our experiments demonstrate that the adaptation network, trained on Whisper's criteria, notably reduces word error rates across domains and languages in packet-loss scenarios. This improvement is achieved with minimal affect to Whisper model's foundational performance, underscoring our method's practicality and potential in enhancing ASR models in challenging acoustic environments.
Tradition or Innovation: A Comparison of Modern ASR Methods for Forced Alignment
Jun 27, 2024



Forced alignment (FA) plays a key role in speech research through the automatic time alignment of speech signals with corresponding text transcriptions. Despite the move towards end-to-end architectures for speech technology, FA is still dominantly achieved through a classic GMM-HMM acoustic model. This work directly compares alignment performance from leading automatic speech recognition (ASR) methods, WhisperX and Massively Multilingual Speech Recognition (MMS), against a Kaldi-based GMM-HMM system, the Montreal Forced Aligner (MFA). Performance was assessed on the manually aligned TIMIT and Buckeye datasets, with comparisons conducted only on words correctly recognized by WhisperX and MMS. The MFA outperformed both WhisperX and MMS, revealing a shortcoming of modern ASR systems. These findings highlight the need for advancements in forced alignment and emphasize the importance of integrating traditional expertise with modern innovation to foster progress. Index Terms: forced alignment, phoneme alignment, word alignment