 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyword Spotting with Hyper-Matched Filters for Small Footprint Devices
Aug 06, 2025


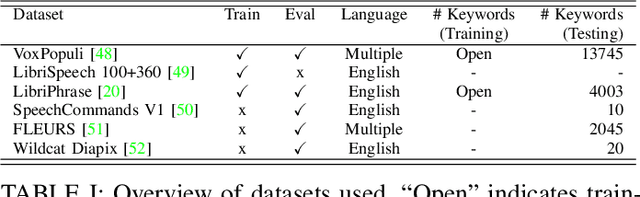
Open-vocabulary keyword spotting (KWS) refers to the task of detecting words or terms within speech recordings, regardless of whether they were included in the training data. This paper introduces an open-vocabulary keyword spotting model with state-of-the-art detection accuracy for small-footprint devices. The model is composed of a speech encoder, a target keyword encoder, and a detection network. The speech encoder is either a tiny Whisper or a tiny Conformer. The target keyword encoder is implemented as a hyper-network that takes the desired keyword as a character string and generates a unique set of weights for a convolutional layer, which can be considered as a keyword-specific matched filter. The detection network uses the matched-filter weights to perform a keyword-specific convolution, which guides the cross-attention mechanism of a Perceiver module in determining whether the target term appears in the recording. The results indicate that our system achieves state-of-the-art detection performance and generalizes effectively to out-of-domain conditions, including second-language (L2) speech. Notably, our smallest model, with just 4.2 million parameters, matches or outperforms models that are several times larger, demonstrating both efficiency and robustness.
FlowTSE: Target Speaker Extraction with Flow Matching
May 20, 2025Target speaker extraction (TSE) aims to isolate a specific speaker's speech from a mixture using speaker enrollment as a reference. While most existing approaches are discriminative, recent generative methods for TSE achieve strong results. However, generative methods for TSE remain underexplored, with most existing approaches relying on complex pipelines and pretrained components, leading to computational overhead. In this work, we present FlowTSE, a simple yet effective TSE approach based on conditional flow matching. Our model receives an enrollment audio sample and a mixed speech signal, both represented as mel-spectrograms, with the objective of extracting the target speaker's clean speech. Furthermore, for tasks where phase reconstruction is crucial, we propose a novel vocoder conditioned on the complex STFT of the mixed signal, enabling improved phase estimation. Experimental results on standard TSE benchmarks show that FlowTSE matches or outperforms strong baselines.
Whisper in Medusa's Ear: Multi-head Efficient Decoding for Transformer-based ASR
Sep 24, 2024



Large transformer-based models have significant potential for speech transcription and translation. Their self-attention mechanisms and parallel processing enable them to capture complex patterns and dependencies in audio sequences. However, this potential comes with challenges, as these large and computationally intensive models lead to slow inference speeds. Various optimization strategies have been proposed to improve performance, including efficient hardware utilization and algorithmic enhancements. In this paper, we introduce Whisper-Medusa, a novel approach designed to enhance processing speed with minimal impact on Word Error Rate (WER). The proposed model extends the OpenAI's Whisper architecture by predicting multiple tokens per iteration, resulting in a 50% reduction in latency. We showcase the effectiveness of Whisper-Medusa across different learning setups and datasets.
HebDB: a Weakly Supervised Dataset for Hebrew Speech Processing
Jul 10, 2024We present HebDB, a weakly supervised dataset for spoken language processing in the Hebrew language. HebDB offers roughly 2500 hours of natural and spontaneous speech recordings in the Hebrew language, consisting of a large variety of speakers and topics. We provide raw recordings together with a pre-processed, weakly supervised, and filtered version. The goal of HebDB is to further enhance research and development of spoken language processing tools for the Hebrew language. Hence, we additionally provide two baseline systems for Automatic Speech Recognition (ASR): (i) a self-supervised model; and (ii) a fully supervised model. We present the performance of these two methods optimized on HebDB and compare them to current multi-lingual ASR alternatives. Results suggest the proposed method reaches better results than the evaluated baselines considering similar model sizes. Dataset, code, and models are publicly available under https://pages.cs.huji.ac.il/adiyoss-lab/HebDB/.