 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHebDB: a Weakly Supervised Dataset for Hebrew Speech Processing
Jul 10, 2024We present HebDB, a weakly supervised dataset for spoken language processing in the Hebrew language. HebDB offers roughly 2500 hours of natural and spontaneous speech recordings in the Hebrew language, consisting of a large variety of speakers and topics. We provide raw recordings together with a pre-processed, weakly supervised, and filtered version. The goal of HebDB is to further enhance research and development of spoken language processing tools for the Hebrew language. Hence, we additionally provide two baseline systems for Automatic Speech Recognition (ASR): (i) a self-supervised model; and (ii) a fully supervised model. We present the performance of these two methods optimized on HebDB and compare them to current multi-lingual ASR alternatives. Results suggest the proposed method reaches better results than the evaluated baselines considering similar model sizes. Dataset, code, and models are publicly available under https://pages.cs.huji.ac.il/adiyoss-lab/HebDB/.
Verification of Neural Networks Local Differential Classification Privacy
Oct 31, 2023
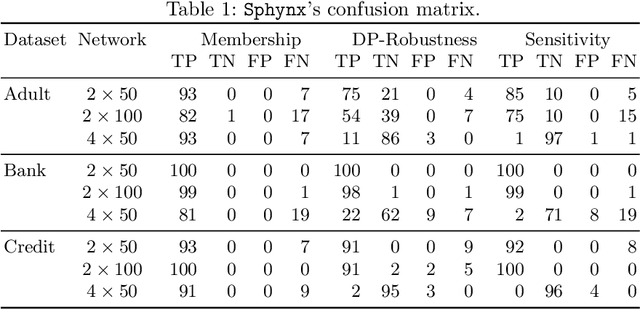

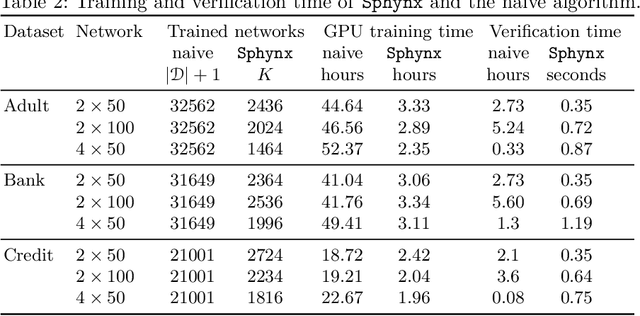
Neural networks are susceptible to privacy attacks. To date, no verifier can reason about the privacy of individuals participating in the training set. We propose a new privacy property, called local differential classification privacy (LDCP), extending local robustness to a differential privacy setting suitable for black-box classifiers. Given a neighborhood of inputs, a classifier is LDCP if it classifies all inputs the same regardless of whether it is trained with the full dataset or whether any single entry is omitted. A naive algorithm is highly impractical because it involves training a very large number of networks and verifying local robustness of the given neighborhood separately for every network. We propose Sphynx, an algorithm that computes an abstraction of all networks, with a high probability, from a small set of networks, and verifies LDCP directly on the abstract network. The challenge is twofold: network parameters do not adhere to a known distribution probability, making it difficult to predict an abstraction, and predicting too large abstraction harms the verification. Our key idea is to transform the parameters into a distribution given by KDE, allowing to keep the over-approximation error small. To verify LDCP, we extend a MILP verifier to analyze an abstract network. Experimental results show that by training only 7% of the networks, Sphynx predicts an abstract network obtaining 93% verification accuracy and reducing the analysis time by $1.7\cdot10^4$x.