 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHebDB: a Weakly Supervised Dataset for Hebrew Speech Processing
Jul 10, 2024We present HebDB, a weakly supervised dataset for spoken language processing in the Hebrew language. HebDB offers roughly 2500 hours of natural and spontaneous speech recordings in the Hebrew language, consisting of a large variety of speakers and topics. We provide raw recordings together with a pre-processed, weakly supervised, and filtered version. The goal of HebDB is to further enhance research and development of spoken language processing tools for the Hebrew language. Hence, we additionally provide two baseline systems for Automatic Speech Recognition (ASR): (i) a self-supervised model; and (ii) a fully supervised model. We present the performance of these two methods optimized on HebDB and compare them to current multi-lingual ASR alternatives. Results suggest the proposed method reaches better results than the evaluated baselines considering similar model sizes. Dataset, code, and models are publicly available under https://pages.cs.huji.ac.il/adiyoss-lab/HebDB/.
DeepFry: Identifying Vocal Fry Using Deep Neural Networks
Mar 31, 2022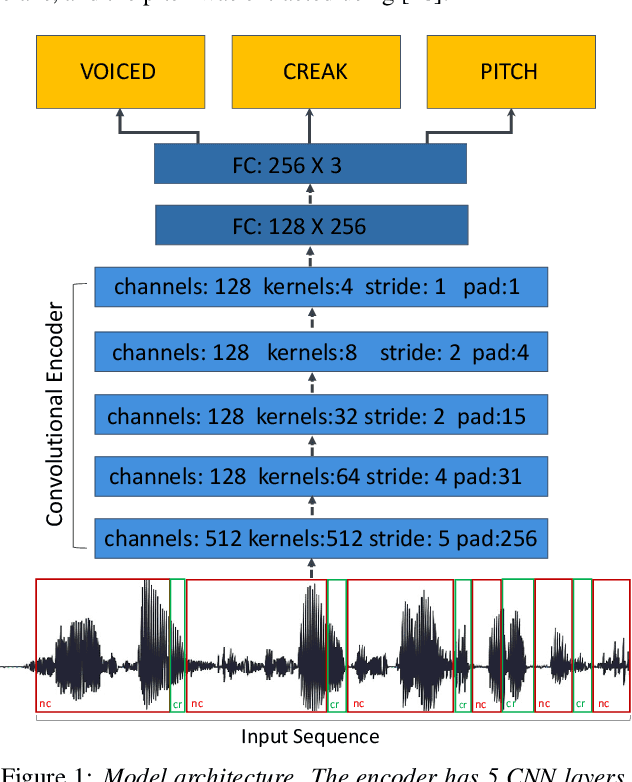
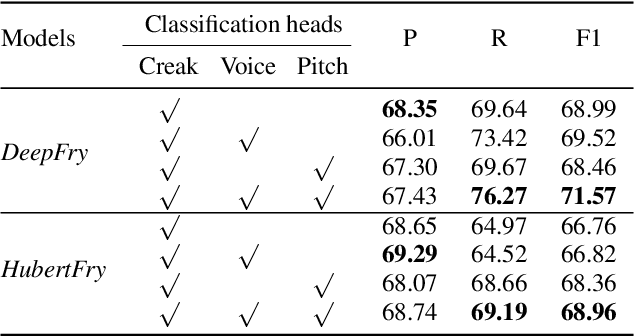

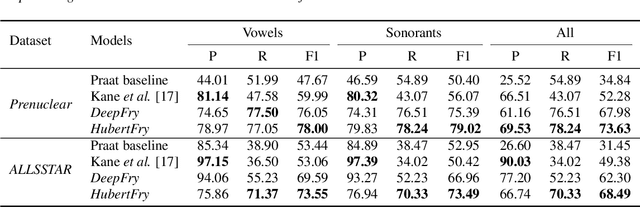
Vocal fry or creaky voice refers to a voice quality characterized by irregular glottal opening and low pitch. It occurs in diverse languages and is prevalent in American English, where it is used not only to mark phrase finality, but also sociolinguistic factors and affect. Due to its irregular periodicity, creaky voice challenges automatic speech processing and recognition systems, particularly for languages where creak is frequently used. This paper proposes a deep learning model to detect creaky voice in fluent speech. The model is composed of an encoder and a classifier trained together. The encoder takes the raw waveform and learns a representation using a convolutional neural network. The classifier is implemented as a multi-headed fully-connected network trained to detect creaky voice, voicing, and pitch, where the last two are used to refine creak prediction. The model is trained and tested on speech of American English speakers, annotated for creak by trained phoneticians. We evaluated the performance of our system using two encoders: one is tailored for the task, and the other is based on a state-of-the-art unsupervised representation. Results suggest our best-performing system has improved recall and F1 scores compared to previous methods on unseen data.