 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Enhancement and Classification using Coupled Diffusion Models of Signals and Logits
Feb 17, 2026Robust classification in noisy environments remains a fundamental challenge in machine learning. Standard approaches typically treat signal enhancement and classification as separate, sequential stages: first enhancing the signal and then applying a classifier. This approach fails to leverage the semantic information in the classifier's output during denoising. In this work, we propose a general, domain-agnostic framework that integrates two interacting diffusion models: one operating on the input signal and the other on the classifier's output logits, without requiring any retraining or fine-tuning of the classifier. This coupled formulation enables mutual guidance, where the enhancing signal refines the class estimation and, conversely, the evolving class logits guide the signal reconstruction towards discriminative regions of the manifold. We introduce three strategies to effectively model the joint distribution of the input and the logit. We evaluated our joint enhancement method for image classification and automatic speech recognition. The proposed framework surpasses traditional sequential enhancement baselines, delivering robust and flexible improvements in classification accuracy under diverse noise conditions.
HebDB: a Weakly Supervised Dataset for Hebrew Speech Processing
Jul 10, 2024We present HebDB, a weakly supervised dataset for spoken language processing in the Hebrew language. HebDB offers roughly 2500 hours of natural and spontaneous speech recordings in the Hebrew language, consisting of a large variety of speakers and topics. We provide raw recordings together with a pre-processed, weakly supervised, and filtered version. The goal of HebDB is to further enhance research and development of spoken language processing tools for the Hebrew language. Hence, we additionally provide two baseline systems for Automatic Speech Recognition (ASR): (i) a self-supervised model; and (ii) a fully supervised model. We present the performance of these two methods optimized on HebDB and compare them to current multi-lingual ASR alternatives. Results suggest the proposed method reaches better results than the evaluated baselines considering similar model sizes. Dataset, code, and models are publicly available under https://pages.cs.huji.ac.il/adiyoss-lab/HebDB/.
Enhanced ASR Robustness to Packet Loss with a Front-End Adaptation Network
Jun 27, 2024



In the realm of automatic speech recognition (ASR), robustness in noisy environments remains a significant challenge. Recent ASR models, such as Whisper, have shown promise, but their efficacy in noisy conditions can be further enhanced. This study is focused on recovering from packet loss to improve the word error rate (WER) of ASR models. We propose using a front-end adaptation network connected to a frozen ASR model. The adaptation network is trained to modify the corrupted input spectrum by minimizing the criteria of the ASR model in addition to an enhancement loss function. Our experiments demonstrate that the adaptation network, trained on Whisper's criteria, notably reduces word error rates across domains and languages in packet-loss scenarios. This improvement is achieved with minimal affect to Whisper model's foundational performance, underscoring our method's practicality and potential in enhancing ASR models in challenging acoustic environments.
Self-supervised Speaker Diarization
Apr 08, 2022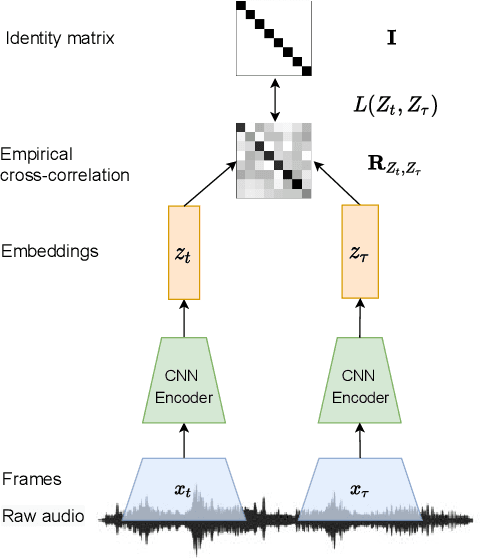


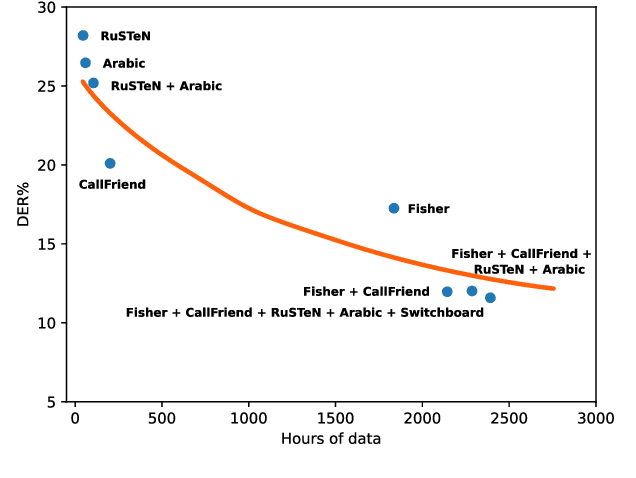
Over the last few years, deep learning has grown in popularity for speaker verification, identification, and diarization. Inarguably, a significant part of this success is due to the demonstrated effectiveness of their speaker representations. These, however, are heavily dependent on large amounts of annotated data and can be sensitive to new domains. This study proposes an entirely unsupervised deep-learning model for speaker diarization. Specifically, the study focuses on generating high-quality neural speaker representations without any annotated data, as well as on estimating secondary hyperparameters of the model without annotations. The speaker embeddings are represented by an encoder trained in a self-supervised fashion using pairs of adjacent segments assumed to be of the same speaker. The trained encoder model is then used to self-generate pseudo-labels to subsequently train a similarity score between different segments of the same call using probabilistic linear discriminant analysis (PLDA) and further to learn a clustering stopping threshold. We compared our model to state-of-the-art unsupervised as well as supervised baselines on the CallHome benchmarks. According to empirical results, our approach outperforms unsupervised methods when only two speakers are present in the call, and is only slightly worse than recent supervised models.
Domain Adaptation For Formant Estimation Using Deep Learning
Nov 06, 2016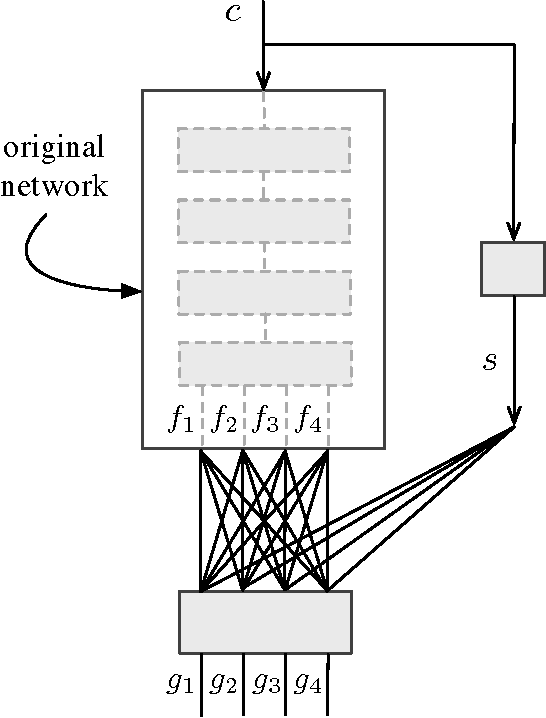


In this paper we present a domain adaptation technique for formant estimation using a deep network. We first train a deep learning network on a small read speech dataset. We then freeze the parameters of the trained network and use several different datasets to train an adaptation layer that makes the obtained network universal in the sense that it works well for a variety of speakers and speech domains with very different characteristics. We evaluated our adapted network on three datasets, each of which has different speaker characteristics and speech styles. The performance of our method compares favorably with alternative methods for formant estimation.