 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHebDB: a Weakly Supervised Dataset for Hebrew Speech Processing
Jul 10, 2024We present HebDB, a weakly supervised dataset for spoken language processing in the Hebrew language. HebDB offers roughly 2500 hours of natural and spontaneous speech recordings in the Hebrew language, consisting of a large variety of speakers and topics. We provide raw recordings together with a pre-processed, weakly supervised, and filtered version. The goal of HebDB is to further enhance research and development of spoken language processing tools for the Hebrew language. Hence, we additionally provide two baseline systems for Automatic Speech Recognition (ASR): (i) a self-supervised model; and (ii) a fully supervised model. We present the performance of these two methods optimized on HebDB and compare them to current multi-lingual ASR alternatives. Results suggest the proposed method reaches better results than the evaluated baselines considering similar model sizes. Dataset, code, and models are publicly available under https://pages.cs.huji.ac.il/adiyoss-lab/HebDB/.
The Vocal Signature of Social Anxiety: Exploration using Hypothesis-Testing and Machine-Learning Approaches
Jul 18, 2022
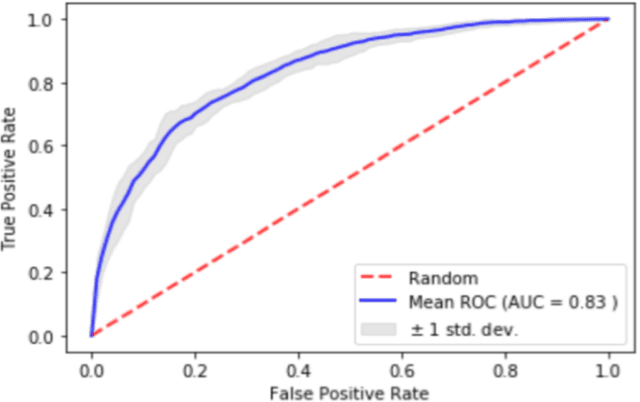
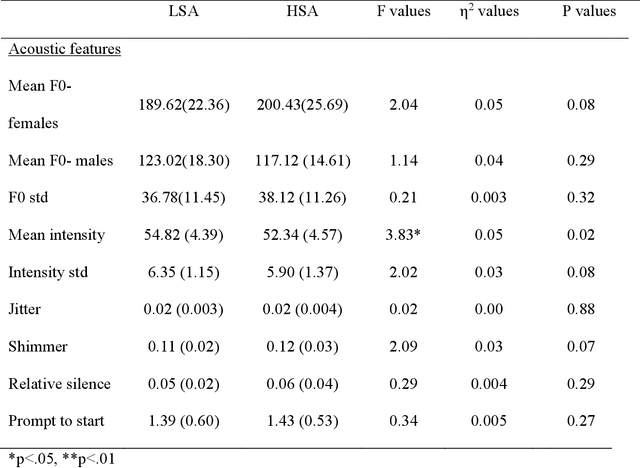
Background - Social anxiety (SA) is a common and debilitating condition, negatively affecting life quality even at sub-diagnostic thresholds. We sought to characterize SA's acoustic signature using hypothesis-testing and machine learning (ML) approaches. Methods - Participants formed spontaneous utterances responding to instructions to refuse or consent to commands of alleged peers. Vocal properties (e.g., intensity and duration) of these utterances were analyzed. Results - Our prediction that, as compared to low-SA (n=31), high-SA (n=32) individuals exhibit a less confident vocal speech signature, especially with respect to refusal utterances, was only partially supported by the classical hypothesis-testing approach. However, the results of the ML analyses and specifically the decision tree classifier were consistent with such speech patterns in SA. Using a Gaussian Process (GP) classifier, we were able to distinguish between high- and low-SA individuals with high (75.6%) accuracy and good (.83 AUC) separability. We also expected and found that vocal properties differentiated between refusal and consent utterances. Conclusions - Our findings provide further support for the usefulness of ML approach for the study of psychopathology, highlighting the utility of developing automatic techniques to create behavioral markers of SAD. Clinically, the simplicity and accessibility of these procedures may encourage people to seek professional help.
Formant Estimation and Tracking using Probabilistic Heat-Maps
Jun 23, 2022

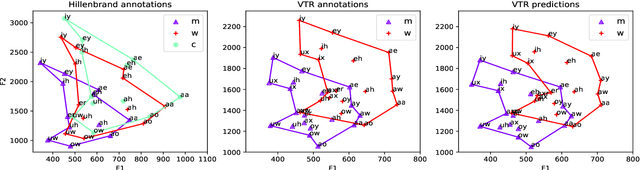
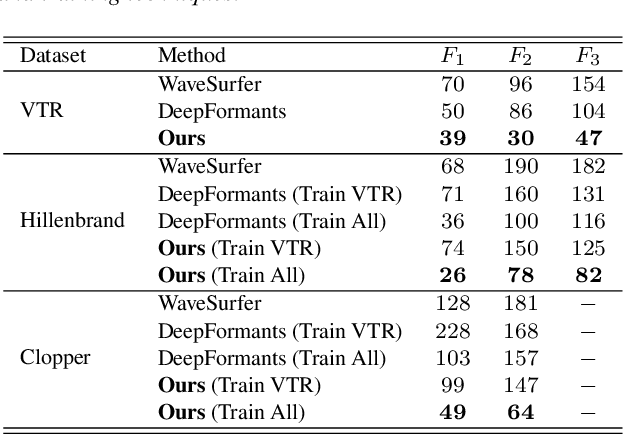
Formants are the spectral maxima that result from acoustic resonances of the human vocal tract, and their accurate estimation is among the most fundamental speech processing problems. Recent work has been shown that those frequencies can accurately be estimated using deep learning techniques. However, when presented with a speech from a different domain than that in which they have been trained on, these methods exhibit a decline in performance, limiting their usage as generic tools. The contribution of this paper is to propose a new network architecture that performs well on a variety of different speaker and speech domains. Our proposed model is composed of a shared encoder that gets as input a spectrogram and outputs a domain-invariant representation. Then, multiple decoders further process this representation, each responsible for predicting a different formant while considering the lower formant predictions. An advantage of our model is that it is based on heatmaps that generate a probability distribution over formant predictions. Results suggest that our proposed model better represents the signal over various domains and leads to better formant frequency tracking and estimation.
Dr.VOT : Measuring Positive and Negative Voice Onset Time in the Wild
Oct 27, 2019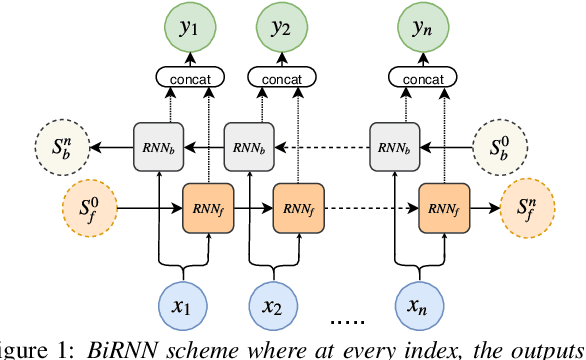
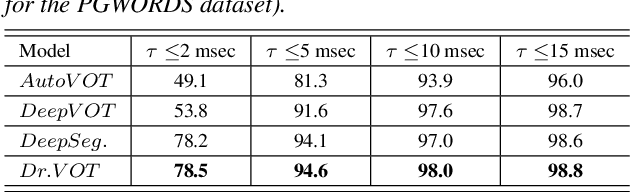

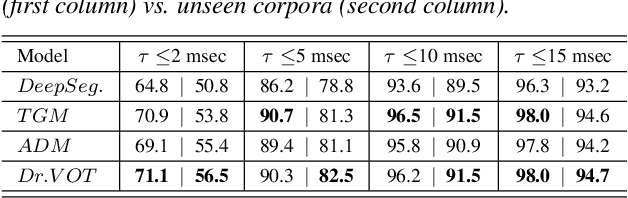
Voice Onset Time (VOT), a key measurement of speech for basic research and applied medical studies, is the time between the onset of a stop burst and the onset of voicing. When the voicing onset precedes burst onset the VOT is negative; if voicing onset follows the burst, it is positive. In this work, we present a deep-learning model for accurate and reliable measurement of VOT in naturalistic speech. The proposed system addresses two critical issues: it can measure positive and negative VOT equally well, and it is trained to be robust to variation across annotations. Our approach is based on the structured prediction framework, where the feature functions are defined to be RNNs. These learn to capture segmental variation in the signal. Results suggest that our method substantially improves over the current state-of-the-art. In contrast to previous work, our Deep and Robust VOT annotator, Dr.VOT, can successfully estimate negative VOTs while maintaining state-of-the-art performance on positive VOTs. This high level of performance generalizes to new corpora without further retraining. Index Terms: structured prediction, multi-task learning, adversarial training, recurrent neural networks, sequence segmentation.
* interspeech 2019