 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing What to Stress: A Discourse-Conditioned Text-to-Speech Benchmark
Apr 12, 2026Spoken meaning often depends not only on what is said, but also on which word is emphasized. The same sentence can convey correction, contrast, or clarification depending on where emphasis falls. Although modern text-to-speech (TTS) systems generate expressive speech, it remains unclear whether they infer contextually appropriate stress from discourse alone. To address this gap, we present Context-Aware Stress TTS (CAST), a benchmark for evaluating context-conditioned word-level stress in TTS. Items are defined as contrastive context pairs: identical sentences paired with distinct contexts requiring different stressed words. We evaluate state-of-the-art systems and find a consistent gap: text-only language models reliably recover the intended stress from context, yet TTS systems frequently fail to realize it in speech. We release the benchmark, evaluation framework, construction pipeline and a synthetic corpus to support future work on context-aware speech synthesis.
Continuous Speech Synthesis using per-token Latent Diffusion
Oct 21, 2024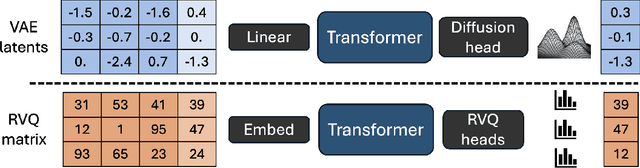
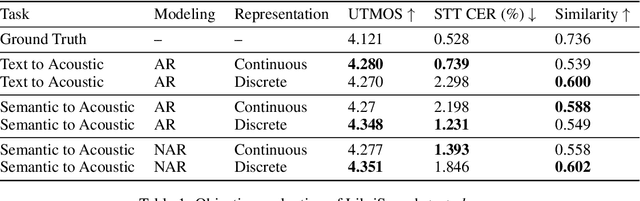
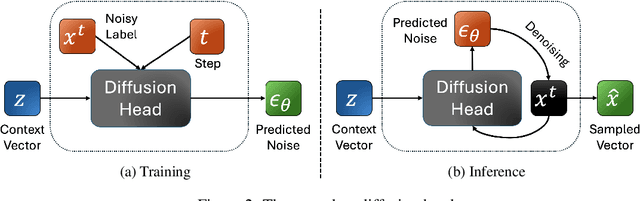

The success of autoregressive transformer models with discrete tokens has inspired quantization-based approaches for continuous modalities, though these often limit reconstruction quality. We therefore introduce SALAD, a per-token latent diffusion model for zero-shot text-to-speech, that operates on continuous representations. SALAD builds upon the recently proposed expressive diffusion head for image generation, and extends it to generate variable-length outputs. Our approach utilizes semantic tokens for providing contextual information and determining the stopping condition. We suggest three continuous variants for our method, extending popular discrete speech synthesis techniques. Additionally, we implement discrete baselines for each variant and conduct a comparative analysis of discrete versus continuous speech modeling techniques. Our results demonstrate that both continuous and discrete approaches are highly competent, and that SALAD achieves a superior intelligibility score while obtaining speech quality and speaker similarity on par with the ground-truth audio.
LAST: Language Model Aware Speech Tokenization
Sep 05, 2024
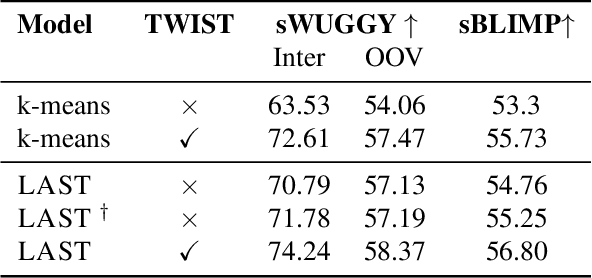


Speech tokenization serves as the foundation of speech language model (LM), enabling them to perform various tasks such as spoken language modeling, text-to-speech, speech-to-text, etc. Most speech tokenizers are trained independently of the LM training process, relying on separate acoustic models and quantization methods. Following such an approach may create a mismatch between the tokenization process and its usage afterward. In this study, we propose a novel approach to training a speech tokenizer by leveraging objectives from pre-trained textual LMs. We advocate for the integration of this objective into the process of learning discrete speech representations. Our aim is to transform features from a pre-trained speech model into a new feature space that enables better clustering for speech LMs. We empirically investigate the impact of various model design choices, including speech vocabulary size and text LM size. Our results demonstrate the proposed tokenization method outperforms the evaluated baselines considering both spoken language modeling and speech-to-text. More importantly, unlike prior work, the proposed method allows the utilization of a single pre-trained LM for processing both speech and text inputs, setting it apart from conventional tokenization approaches.
A Language Modeling Approach to Diacritic-Free Hebrew TTS
Jul 16, 2024We tackle the task of text-to-speech (TTS) in Hebrew. Traditional Hebrew contains Diacritics, which dictate the way individuals should pronounce given words, however, modern Hebrew rarely uses them. The lack of diacritics in modern Hebrew results in readers expected to conclude the correct pronunciation and understand which phonemes to use based on the context. This imposes a fundamental challenge on TTS systems to accurately map between text-to-speech. In this work, we propose to adopt a language modeling Diacritics-Free approach, for the task of Hebrew TTS. The model operates on discrete speech representations and is conditioned on a word-piece tokenizer. We optimize the proposed method using in-the-wild weakly supervised data and compare it to several diacritic-based TTS systems. Results suggest the proposed method is superior to the evaluated baselines considering both content preservation and naturalness of the generated speech. Samples can be found under the following link: pages.cs.huji.ac.il/adiyoss-lab/HebTTS/
HebDB: a Weakly Supervised Dataset for Hebrew Speech Processing
Jul 10, 2024We present HebDB, a weakly supervised dataset for spoken language processing in the Hebrew language. HebDB offers roughly 2500 hours of natural and spontaneous speech recordings in the Hebrew language, consisting of a large variety of speakers and topics. We provide raw recordings together with a pre-processed, weakly supervised, and filtered version. The goal of HebDB is to further enhance research and development of spoken language processing tools for the Hebrew language. Hence, we additionally provide two baseline systems for Automatic Speech Recognition (ASR): (i) a self-supervised model; and (ii) a fully supervised model. We present the performance of these two methods optimized on HebDB and compare them to current multi-lingual ASR alternatives. Results suggest the proposed method reaches better results than the evaluated baselines considering similar model sizes. Dataset, code, and models are publicly available under https://pages.cs.huji.ac.il/adiyoss-lab/HebDB/.
Deep Audio Waveform Prior
Jul 21, 2022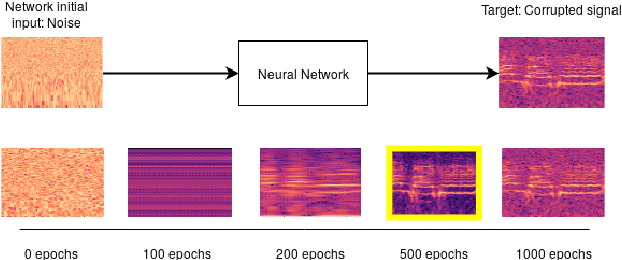



Convolutional neural networks contain strong priors for generating natural looking images [1]. These priors enable image denoising, super resolution, and inpainting in an unsupervised manner. Previous attempts to demonstrate similar ideas in audio, namely deep audio priors, (i) use hand picked architectures such as harmonic convolutions, (ii) only work with spectrogram input, and (iii) have been used mostly for eliminating Gaussian noise [2]. In this work we show that existing SOTA architectures for audio source separation contain deep priors even when working with the raw waveform. Deep priors can be discovered by training a neural network to generate a single corrupted signal when given white noise as input. A network with relevant deep priors is likely to generate a cleaner version of the signal before converging on the corrupted signal. We demonstrate this restoration effect with several corruptions: background noise, reverberations, and a gap in the signal (audio inpainting).