 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Audio Waveform Prior
Jul 21, 2022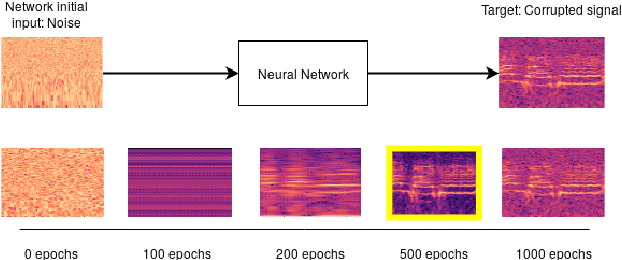



Convolutional neural networks contain strong priors for generating natural looking images [1]. These priors enable image denoising, super resolution, and inpainting in an unsupervised manner. Previous attempts to demonstrate similar ideas in audio, namely deep audio priors, (i) use hand picked architectures such as harmonic convolutions, (ii) only work with spectrogram input, and (iii) have been used mostly for eliminating Gaussian noise [2]. In this work we show that existing SOTA architectures for audio source separation contain deep priors even when working with the raw waveform. Deep priors can be discovered by training a neural network to generate a single corrupted signal when given white noise as input. A network with relevant deep priors is likely to generate a cleaner version of the signal before converging on the corrupted signal. We demonstrate this restoration effect with several corruptions: background noise, reverberations, and a gap in the signal (audio inpainting).
A Peek at Peak Emotion Recognition
May 19, 2022


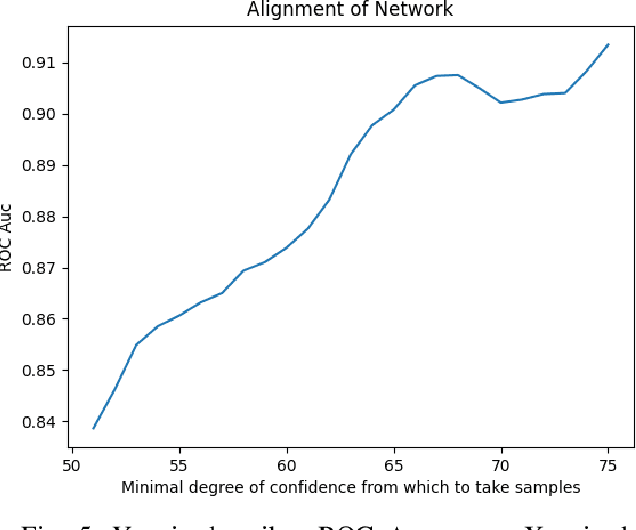
Despite much progress in the field of facial expression recognition, little attention has been paid to the recognition of peak emotion. Aviezer et al. [1] showed that humans have trouble discerning between positive and negative peak emotions. In this work we analyze how deep learning fares on this challenge. We find that (i) despite using very small datasets, features extracted from deep learning models can achieve results significantly better than humans. (ii) We find that deep learning models, even when trained only on datasets tagged by humans, still outperform humans in this task.
Audio-Visual Evaluation of Oratory Skills
Sep 30, 2021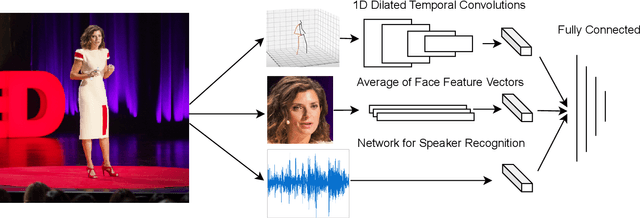

What makes a talk successful? Is it the content or the presentation? We try to estimate the contribution of the speaker's oratory skills to the talk's success, while ignoring the content of the talk. By oratory skills we refer to facial expressions, motions and gestures, as well as the vocal features. We use TED Talks as our dataset, and measure the success of each talk by its view count. Using this dataset we train a neural network to assess the oratory skills in a talk through three factors: body pose, facial expressions, and acoustic features. Most previous work on automatic evaluation of oratory skills uses hand-crafted expert annotations for both the quality of the talk and for the identification of predefined actions. Unlike prior art, we measure the quality to be equivalent to the view count of the talk as counted by TED, and allow the network to automatically learn the actions, expressions, and sounds that are relevant to the success of a talk. We find that oratory skills alone contribute substantially to the chances of a talk being successful.