 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Enhancement from Multiple Crowdsourced Recordings: A Simple and Effective Baseline
Aug 30, 2024With the popularity of cellular phones, events are often recorded by multiple devices from different locations and shared on social media. Several different recordings could be found for many events. Such recordings are usually noisy, where noise for each device is local and unrelated to others. This case of multiple microphones at unknown locations, capturing local, uncorrelated noise, was rarely treated in the literature. In this work we propose a simple and effective crowdsourced audio enhancement method to remove local noises at each input audio signal. Then, averaging all cleaned source signals gives an improved audio of the event. We demonstrate the effectiveness of our method using synthetic audio signals, together with real-world recordings. This simple approach can set a new baseline for crowdsourced audio enhancement for more sophisticated methods which we hope will be developed by the research community.
ReFace: Improving Clothes-Changing Re-Identification With Face Features
Nov 24, 2022Person re-identification (ReID) has been an active research field for many years. Despite that, models addressing this problem tend to perform poorly when the task is to re-identify the same people over a prolonged time, due to appearance changes such as different clothes and hairstyles. In this work, we introduce a new method that takes full advantage of the ability of existing ReID models to extract appearance-related features and combines it with a face feature extraction model to achieve new state-of-the-art results, both on image-based and video-based benchmarks. Moreover, we show how our method could be used for an application in which multiple people of interest, under clothes-changing settings, should be re-identified given an unseen video and a limited amount of labeled data. We claim that current ReID benchmarks do not represent such real-world scenarios, and publish a new dataset, 42Street, based on a theater play as an example of such an application. We show that our proposed method outperforms existing models also on this dataset while using only pre-trained modules and without any further training.
Deep Audio Waveform Prior
Jul 21, 2022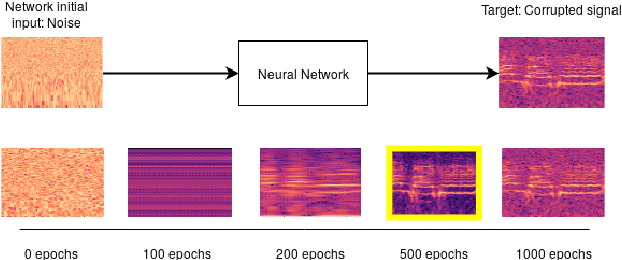



Convolutional neural networks contain strong priors for generating natural looking images [1]. These priors enable image denoising, super resolution, and inpainting in an unsupervised manner. Previous attempts to demonstrate similar ideas in audio, namely deep audio priors, (i) use hand picked architectures such as harmonic convolutions, (ii) only work with spectrogram input, and (iii) have been used mostly for eliminating Gaussian noise [2]. In this work we show that existing SOTA architectures for audio source separation contain deep priors even when working with the raw waveform. Deep priors can be discovered by training a neural network to generate a single corrupted signal when given white noise as input. A network with relevant deep priors is likely to generate a cleaner version of the signal before converging on the corrupted signal. We demonstrate this restoration effect with several corruptions: background noise, reverberations, and a gap in the signal (audio inpainting).
A Peek at Peak Emotion Recognition
May 19, 2022


Despite much progress in the field of facial expression recognition, little attention has been paid to the recognition of peak emotion. Aviezer et al. [1] showed that humans have trouble discerning between positive and negative peak emotions. In this work we analyze how deep learning fares on this challenge. We find that (i) despite using very small datasets, features extracted from deep learning models can achieve results significantly better than humans. (ii) We find that deep learning models, even when trained only on datasets tagged by humans, still outperform humans in this task.
Audio-Visual Evaluation of Oratory Skills
Sep 30, 2021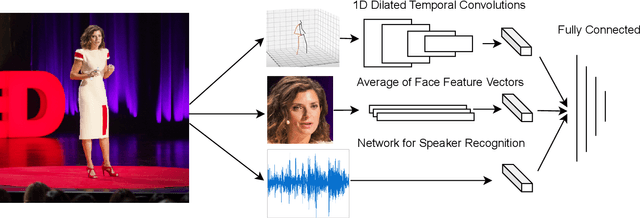

What makes a talk successful? Is it the content or the presentation? We try to estimate the contribution of the speaker's oratory skills to the talk's success, while ignoring the content of the talk. By oratory skills we refer to facial expressions, motions and gestures, as well as the vocal features. We use TED Talks as our dataset, and measure the success of each talk by its view count. Using this dataset we train a neural network to assess the oratory skills in a talk through three factors: body pose, facial expressions, and acoustic features. Most previous work on automatic evaluation of oratory skills uses hand-crafted expert annotations for both the quality of the talk and for the identification of predefined actions. Unlike prior art, we measure the quality to be equivalent to the view count of the talk as counted by TED, and allow the network to automatically learn the actions, expressions, and sounds that are relevant to the success of a talk. We find that oratory skills alone contribute substantially to the chances of a talk being successful.
Reconstruction-Based Membership Inference Attacks are Easier on Difficult Problems
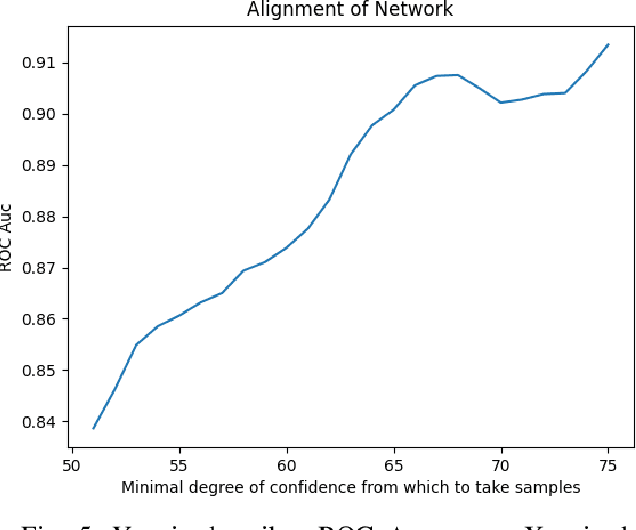
Feb 15, 2021
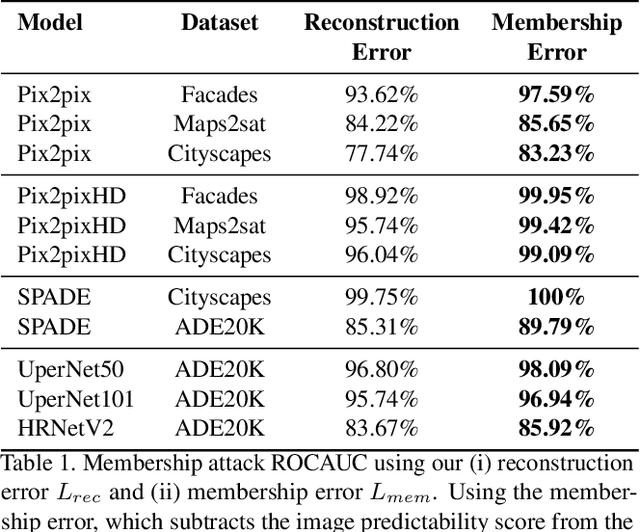


Membership inference attacks (MIA) try to detect if data samples were used to train a neural network model, e.g. to detect copyright abuses. We show that models with higher dimensional input and output are more vulnerable to MIA, and address in more detail models for image translation and semantic segmentation. We show that reconstruction-errors can lead to very effective MIA attacks as they are indicative of memorization. Unfortunately, reconstruction error alone is less effective at discriminating between non-predictable images used in training and easy to predict images that were never seen before. To overcome this, we propose using a novel predictability score that can be computed for each sample, and its computation does not require a training set. Our membership error, obtained by subtracting the predictability score from the reconstruction error, is shown to achieve high MIA accuracy on an extensive number of benchmarks.
Crypto-Oriented Neural Architecture Design
Nov 27, 2019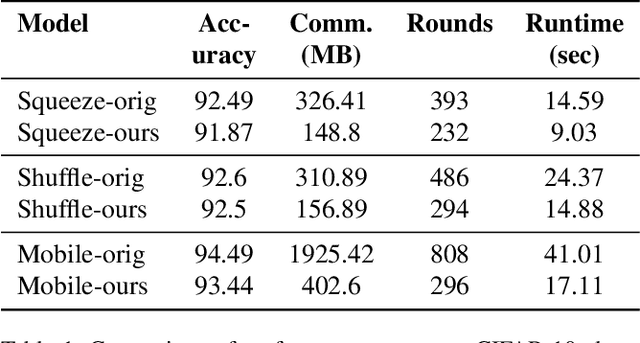
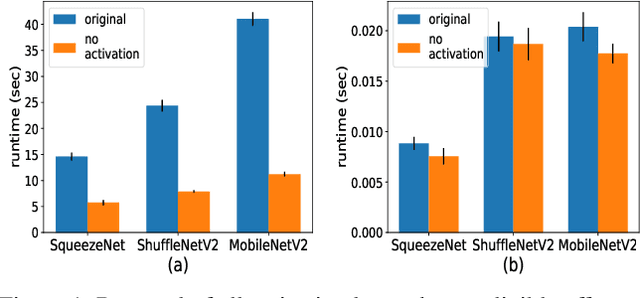
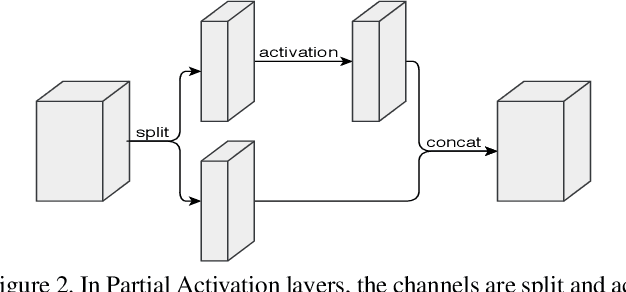
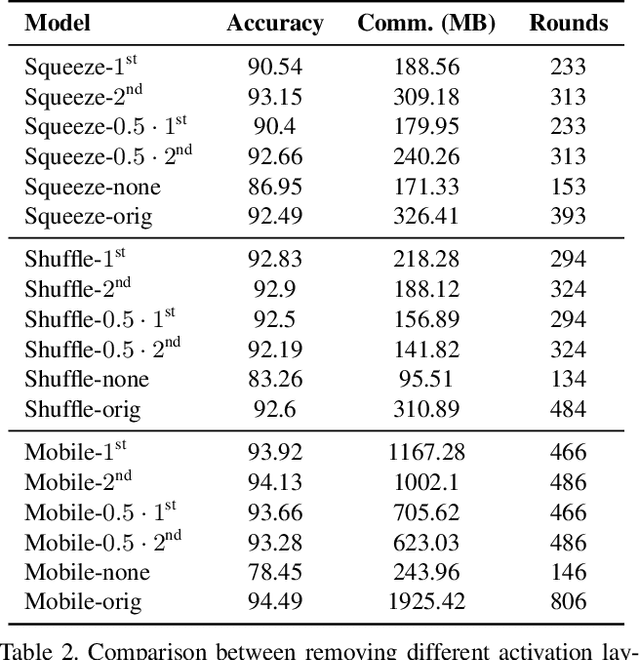
As neural networks revolutionize many applications, significant privacy concerns emerge. Owners of private data wish to use remote neural network services while ensuring their data cannot be interpreted by others. Service providers wish to keep their model private to safeguard its intellectual property. Such privacy conflicts may slow down the adoption of neural networks in sensitive domains such as healthcare. Privacy issues have been addressed in the cryptography community in the context of secure computation. However, secure computation protocols have known performance issues. E.g., runtime of secure inference in deep neural networks is three orders of magnitude longer comparing to non-secure inference. Therefore, much research efforts address the optimization of cryptographic protocols for secure inference. We take a complementary approach, and provide design principles for optimizing the crypto-oriented neural network architectures to reduce the runtime of secure inference. The principles are evaluated on three state-of-the-art architectures: SqueezeNet, ShuffleNetV2, and MobileNetV2. Our novel method significantly improves the efficiency of secure inference on common evaluation metrics.
Dynamic Temporal Alignment of Speech to Lips
Aug 19, 2018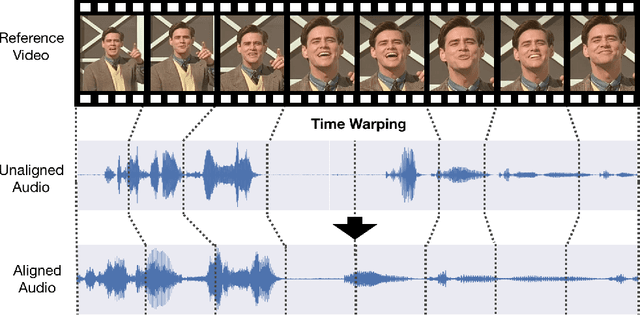
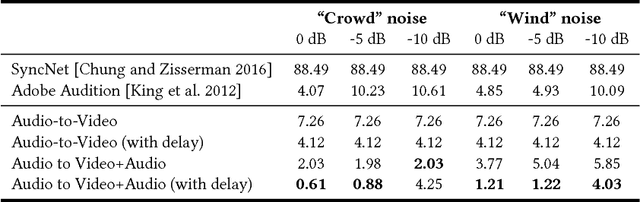
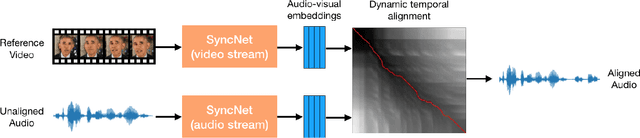
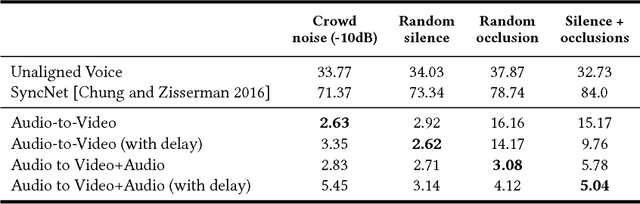
Many speech segments in movies are re-recorded in a studio during postproduction, to compensate for poor sound quality as recorded on location. Manual alignment of the newly-recorded speech with the original lip movements is a tedious task. We present an audio-to-video alignment method for automating speech to lips alignment, stretching and compressing the audio signal to match the lip movements. This alignment is based on deep audio-visual features, mapping the lips video and the speech signal to a shared representation. Using this shared representation we compute the lip-sync error between every short speech period and every video frame, followed by the determination of the optimal corresponding frame for each short sound period over the entire video clip. We demonstrate successful alignment both quantitatively, using a human perception-inspired metric, as well as qualitatively. The strongest advantage of our audio-to-video approach is in cases where the original voice in unclear, and where a constant shift of the sound can not give a perfect alignment. In these cases state-of-the-art methods will fail.
Visual Speech Enhancement
Jun 13, 2018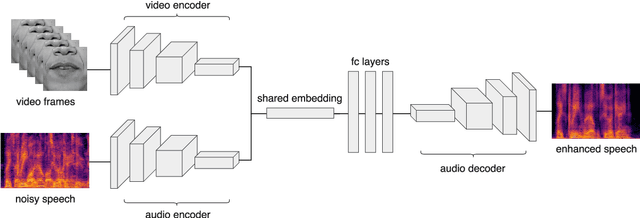
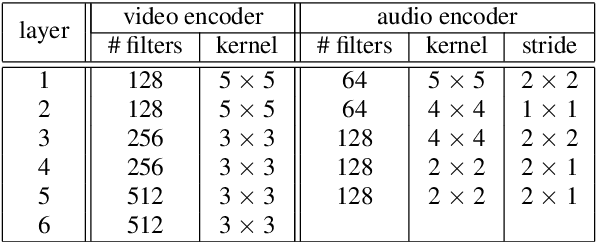

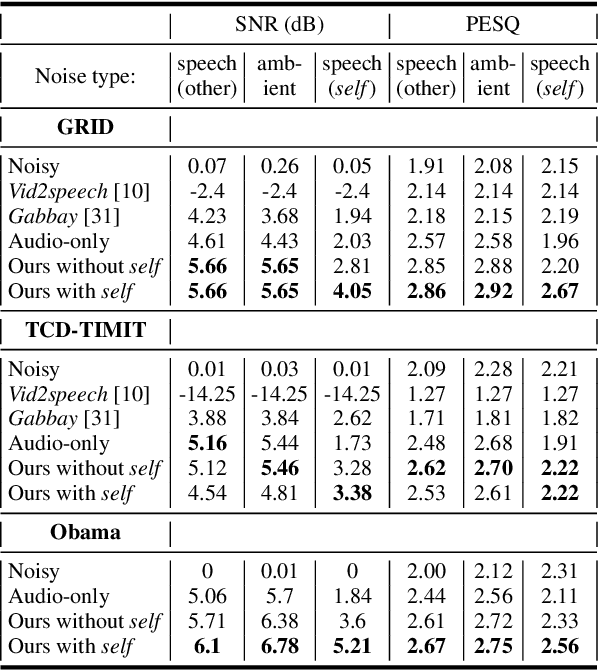
When video is shot in noisy environment, the voice of a speaker seen in the video can be enhanced using the visible mouth movements, reducing background noise. While most existing methods use audio-only inputs, improved performance is obtained with our visual speech enhancement, based on an audio-visual neural network. We include in the training data videos to which we added the voice of the target speaker as background noise. Since the audio input is not sufficient to separate the voice of a speaker from his own voice, the trained model better exploits the visual input and generalizes well to different noise types. The proposed model outperforms prior audio visual methods on two public lipreading datasets. It is also the first to be demonstrated on a dataset not designed for lipreading, such as the weekly addresses of Barack Obama.
Seeing Through Noise: Visually Driven Speaker Separation and Enhancement
Feb 09, 2018
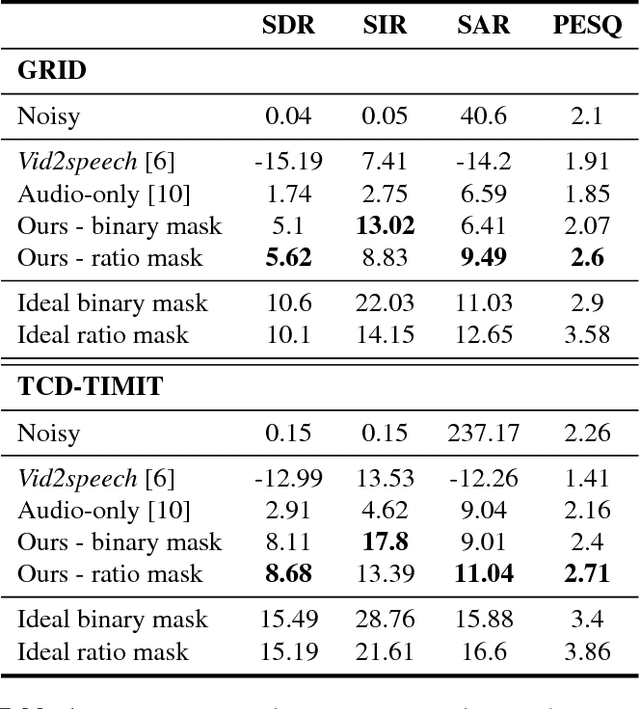
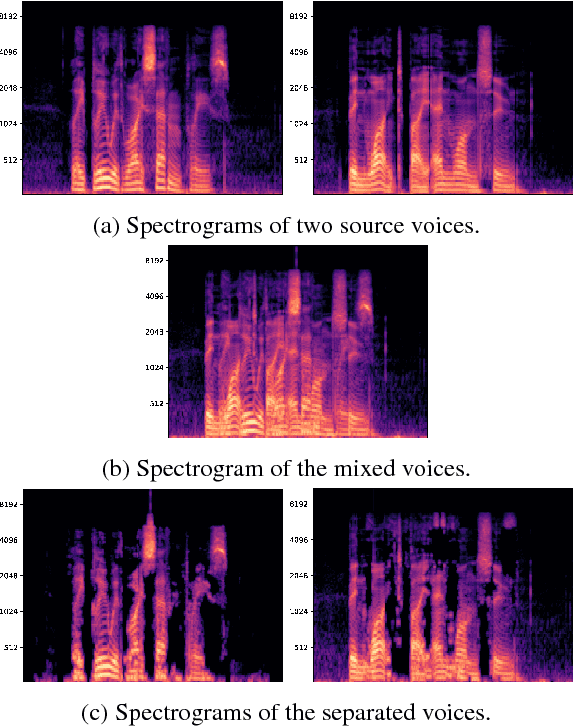
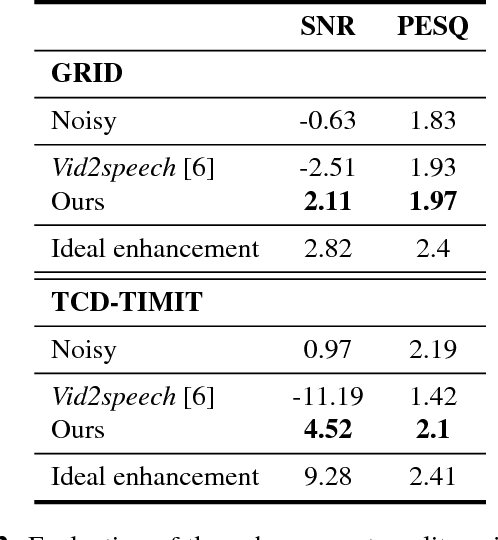
Isolating the voice of a specific person while filtering out other voices or background noises is challenging when video is shot in noisy environments. We propose audio-visual methods to isolate the voice of a single speaker and eliminate unrelated sounds. First, face motions captured in the video are used to estimate the speaker's voice, by passing the silent video frames through a video-to-speech neural network-based model. Then the speech predictions are applied as a filter on the noisy input audio. This approach avoids using mixtures of sounds in the learning process, as the number of such possible mixtures is huge, and would inevitably bias the trained model. We evaluate our method on two audio-visual datasets, GRID and TCD-TIMIT, and show that our method attains significant SDR and PESQ improvements over the raw video-to-speech predictions, and a well-known audio-only method.