 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction-Based Membership Inference Attacks are Easier on Difficult Problems
Paper and Code
Feb 15, 2021
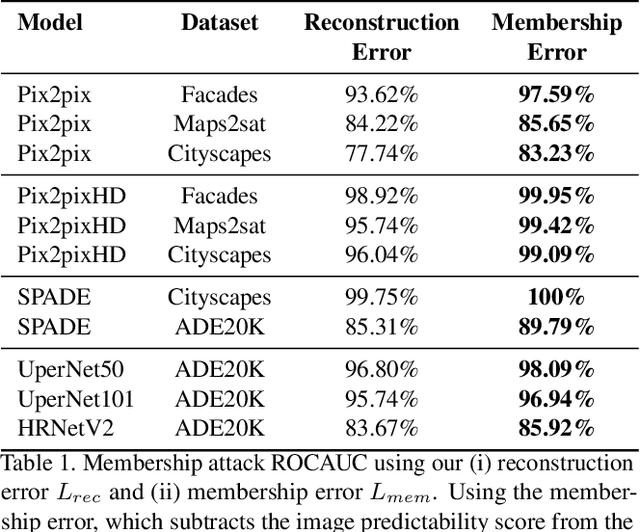


Membership inference attacks (MIA) try to detect if data samples were used to train a neural network model, e.g. to detect copyright abuses. We show that models with higher dimensional input and output are more vulnerable to MIA, and address in more detail models for image translation and semantic segmentation. We show that reconstruction-errors can lead to very effective MIA attacks as they are indicative of memorization. Unfortunately, reconstruction error alone is less effective at discriminating between non-predictable images used in training and easy to predict images that were never seen before. To overcome this, we propose using a novel predictability score that can be computed for each sample, and its computation does not require a training set. Our membership error, obtained by subtracting the predictability score from the reconstruction error, is shown to achieve high MIA accuracy on an extensive number of benchmarks.