 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRerouting LLM Routers
Jan 03, 2025



LLM routers aim to balance quality and cost of generation by classifying queries and routing them to a cheaper or more expensive LLM depending on their complexity. Routers represent one type of what we call LLM control planes: systems that orchestrate use of one or more LLMs. In this paper, we investigate routers' adversarial robustness. We first define LLM control plane integrity, i.e., robustness of LLM orchestration to adversarial inputs, as a distinct problem in AI safety. Next, we demonstrate that an adversary can generate query-independent token sequences we call ``confounder gadgets'' that, when added to any query, cause LLM routers to send the query to a strong LLM. Our quantitative evaluation shows that this attack is successful both in white-box and black-box settings against a variety of open-source and commercial routers, and that confounding queries do not affect the quality of LLM responses. Finally, we demonstrate that gadgets can be effective while maintaining low perplexity, thus perplexity-based filtering is not an effective defense. We finish by investigating alternative defenses.
Machine Against the RAG: Jamming Retrieval-Augmented Generation with Blocker Documents
Jun 09, 2024



Retrieval-augmented generation (RAG) systems respond to queries by retrieving relevant documents from a knowledge database, then generating an answer by applying an LLM to the retrieved documents. We demonstrate that RAG systems that operate on databases with potentially untrusted content are vulnerable to a new class of denial-of-service attacks we call jamming. An adversary can add a single ``blocker'' document to the database that will be retrieved in response to a specific query and, furthermore, result in the RAG system not answering the query - ostensibly because it lacks the information or because the answer is unsafe. We describe and analyze several methods for generating blocker documents, including a new method based on black-box optimization that does not require the adversary to know the embedding or LLM used by the target RAG system, nor access to an auxiliary LLM to generate blocker documents. We measure the efficacy of the considered methods against several LLMs and embeddings, and demonstrate that the existing safety metrics for LLMs do not capture their vulnerability to jamming. We then discuss defenses against blocker documents.
Beyond Labeling Oracles: What does it mean to steal ML models?
Oct 03, 2023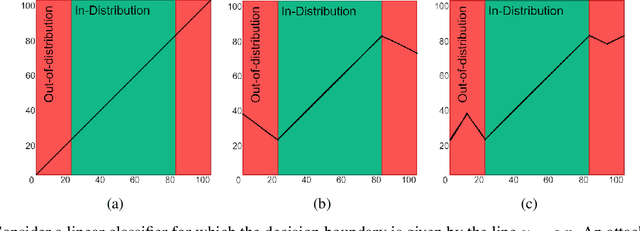

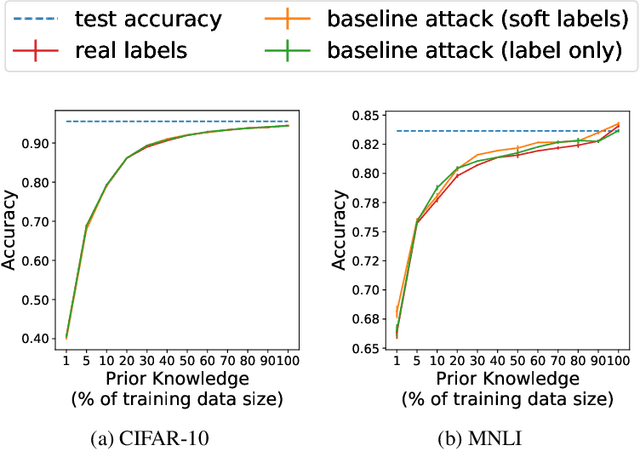
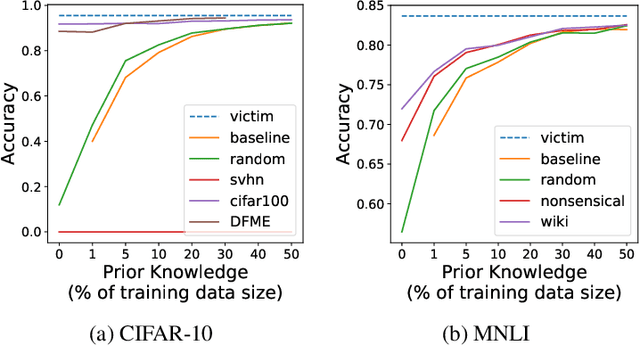
Model extraction attacks are designed to steal trained models with only query access, as is often provided through APIs that ML-as-a-Service providers offer. ML models are expensive to train, in part because data is hard to obtain, and a primary incentive for model extraction is to acquire a model while incurring less cost than training from scratch. Literature on model extraction commonly claims or presumes that the attacker is able to save on both data acquisition and labeling costs. We show that the attacker often does not. This is because current attacks implicitly rely on the adversary being able to sample from the victim model's data distribution. We thoroughly evaluate factors influencing the success of model extraction. We discover that prior knowledge of the attacker, i.e. access to in-distribution data, dominates other factors like the attack policy the adversary follows to choose which queries to make to the victim model API. Thus, an adversary looking to develop an equally capable model with a fixed budget has little practical incentive to perform model extraction, since for the attack to work they need to collect in-distribution data, saving only on the cost of labeling. With low labeling costs in the current market, the usefulness of such attacks is questionable. Ultimately, we demonstrate that the effect of prior knowledge needs to be explicitly decoupled from the attack policy. To this end, we propose a benchmark to evaluate attack policy directly.
Reconstruction-Based Membership Inference Attacks are Easier on Difficult Problems
Feb 15, 2021
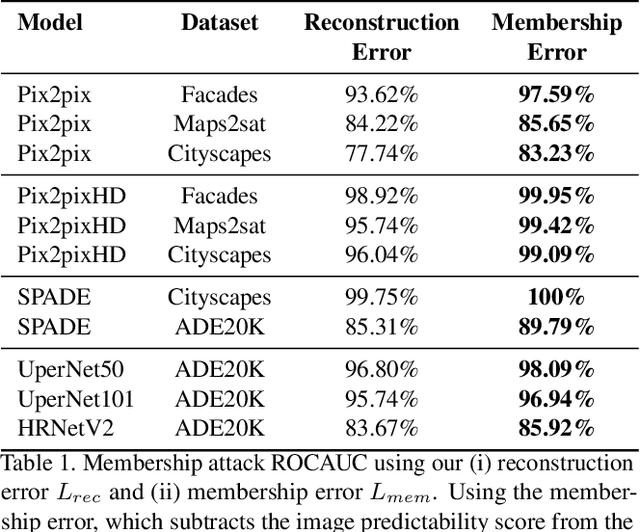


Membership inference attacks (MIA) try to detect if data samples were used to train a neural network model, e.g. to detect copyright abuses. We show that models with higher dimensional input and output are more vulnerable to MIA, and address in more detail models for image translation and semantic segmentation. We show that reconstruction-errors can lead to very effective MIA attacks as they are indicative of memorization. Unfortunately, reconstruction error alone is less effective at discriminating between non-predictable images used in training and easy to predict images that were never seen before. To overcome this, we propose using a novel predictability score that can be computed for each sample, and its computation does not require a training set. Our membership error, obtained by subtracting the predictability score from the reconstruction error, is shown to achieve high MIA accuracy on an extensive number of benchmarks.
Crypto-Oriented Neural Architecture Design
Nov 27, 2019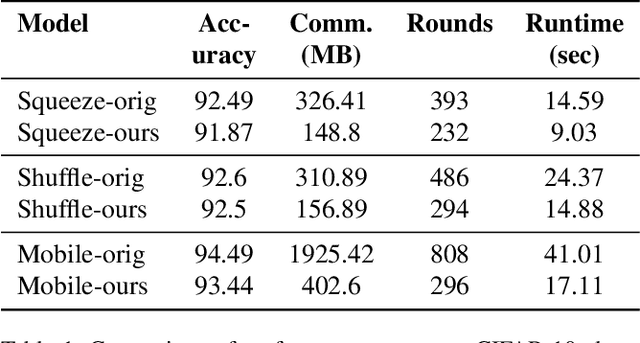
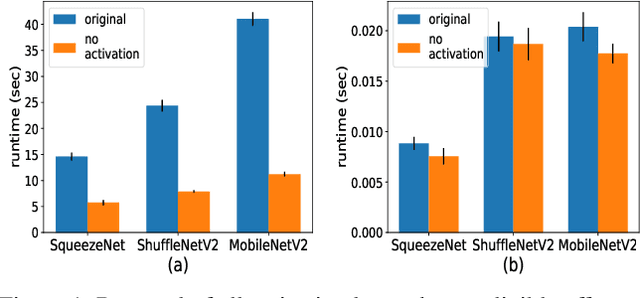
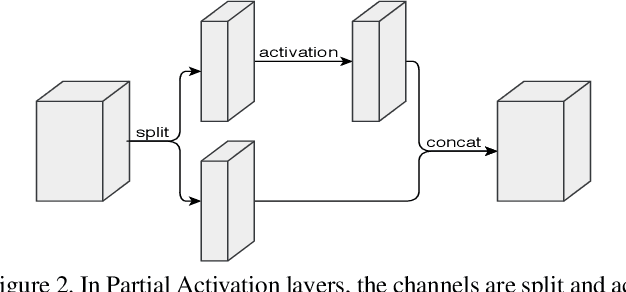
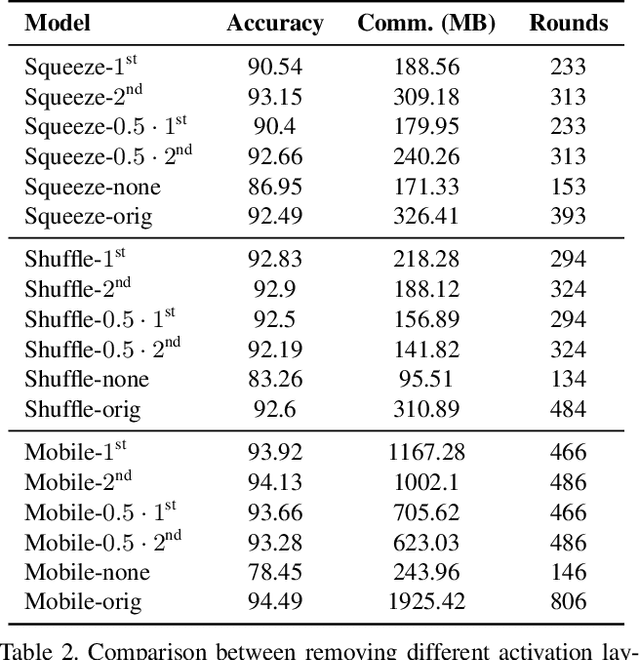
As neural networks revolutionize many applications, significant privacy concerns emerge. Owners of private data wish to use remote neural network services while ensuring their data cannot be interpreted by others. Service providers wish to keep their model private to safeguard its intellectual property. Such privacy conflicts may slow down the adoption of neural networks in sensitive domains such as healthcare. Privacy issues have been addressed in the cryptography community in the context of secure computation. However, secure computation protocols have known performance issues. E.g., runtime of secure inference in deep neural networks is three orders of magnitude longer comparing to non-secure inference. Therefore, much research efforts address the optimization of cryptographic protocols for secure inference. We take a complementary approach, and provide design principles for optimizing the crypto-oriented neural network architectures to reduce the runtime of secure inference. The principles are evaluated on three state-of-the-art architectures: SqueezeNet, ShuffleNetV2, and MobileNetV2. Our novel method significantly improves the efficiency of secure inference on common evaluation metrics.