 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRerouting LLM Routers
Jan 03, 2025



LLM routers aim to balance quality and cost of generation by classifying queries and routing them to a cheaper or more expensive LLM depending on their complexity. Routers represent one type of what we call LLM control planes: systems that orchestrate use of one or more LLMs. In this paper, we investigate routers' adversarial robustness. We first define LLM control plane integrity, i.e., robustness of LLM orchestration to adversarial inputs, as a distinct problem in AI safety. Next, we demonstrate that an adversary can generate query-independent token sequences we call ``confounder gadgets'' that, when added to any query, cause LLM routers to send the query to a strong LLM. Our quantitative evaluation shows that this attack is successful both in white-box and black-box settings against a variety of open-source and commercial routers, and that confounding queries do not affect the quality of LLM responses. Finally, we demonstrate that gadgets can be effective while maintaining low perplexity, thus perplexity-based filtering is not an effective defense. We finish by investigating alternative defenses.
Machine Learning Models that Remember Too Much
Sep 22, 2017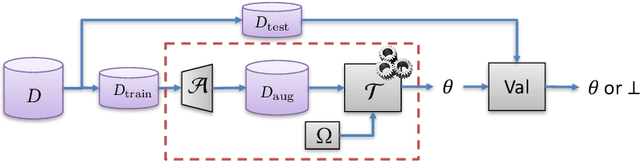
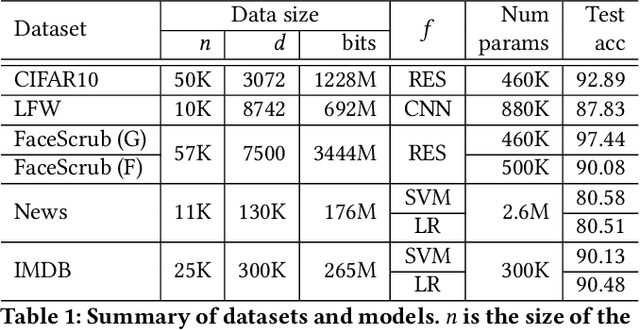
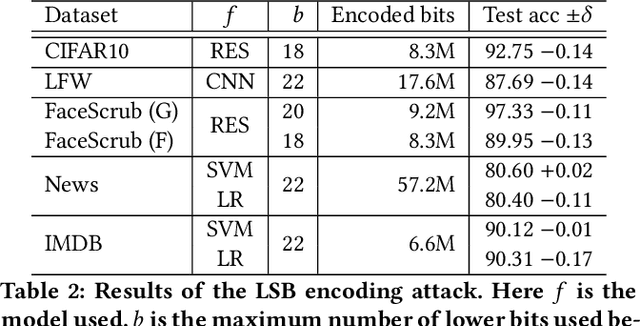
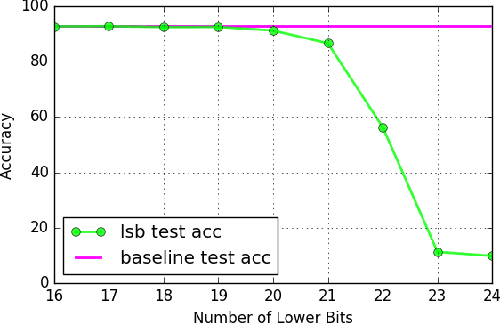
Machine learning (ML) is becoming a commodity. Numerous ML frameworks and services are available to data holders who are not ML experts but want to train predictive models on their data. It is important that ML models trained on sensitive inputs (e.g., personal images or documents) not leak too much information about the training data. We consider a malicious ML provider who supplies model-training code to the data holder, does not observe the training, but then obtains white- or black-box access to the resulting model. In this setting, we design and implement practical algorithms, some of them very similar to standard ML techniques such as regularization and data augmentation, that "memorize" information about the training dataset in the model yet the model is as accurate and predictive as a conventionally trained model. We then explain how the adversary can extract memorized information from the model. We evaluate our techniques on standard ML tasks for image classification (CIFAR10), face recognition (LFW and FaceScrub), and text analysis (20 Newsgroups and IMDB). In all cases, we show how our algorithms create models that have high predictive power yet allow accurate extraction of subsets of their training data.
Stealing Machine Learning Models via Prediction APIs
Oct 03, 2016
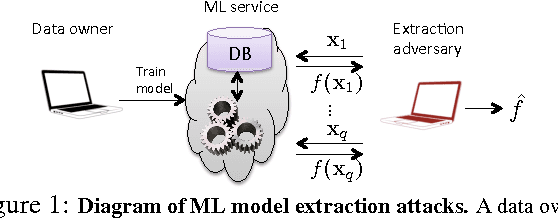

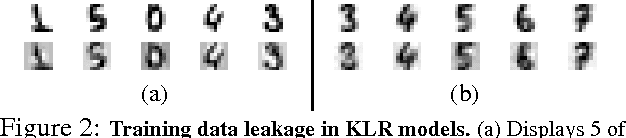
Machine learning (ML) models may be deemed confidential due to their sensitive training data, commercial value, or use in security applications. Increasingly often, confidential ML models are being deployed with publicly accessible query interfaces. ML-as-a-service ("predictive analytics") systems are an example: Some allow users to train models on potentially sensitive data and charge others for access on a pay-per-query basis. The tension between model confidentiality and public access motivates our investigation of model extraction attacks. In such attacks, an adversary with black-box access, but no prior knowledge of an ML model's parameters or training data, aims to duplicate the functionality of (i.e., "steal") the model. Unlike in classical learning theory settings, ML-as-a-service offerings may accept partial feature vectors as inputs and include confidence values with predictions. Given these practices, we show simple, efficient attacks that extract target ML models with near-perfect fidelity for popular model classes including logistic regression, neural networks, and decision trees. We demonstrate these attacks against the online services of BigML and Amazon Machine Learning. We further show that the natural countermeasure of omitting confidence values from model outputs still admits potentially harmful model extraction attacks. Our results highlight the need for careful ML model deployment and new model extraction countermeasures.