 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Federated Learning In Real World Application -- A Case Study
Feb 10, 2025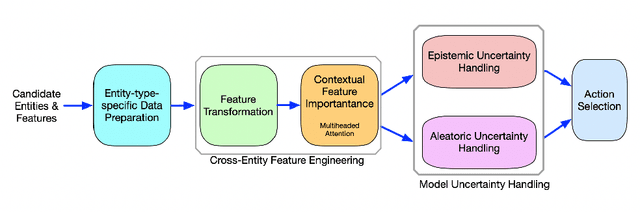

This paper presents an implementation of machine learning model training using private federated learning (PFL) on edge devices. We introduce a novel framework that uses PFL to address the challenge of training a model using users' private data. The framework ensures that user data remain on individual devices, with only essential model updates transmitted to a central server for aggregation with privacy guarantees. We detail the architecture of our app selection model, which incorporates a neural network with attention mechanisms and ambiguity handling through uncertainty management. Experiments conducted through off-line simulations and on device training demonstrate the feasibility of our approach in real-world scenarios. Our results show the potential of PFL to improve the accuracy of an app selection model by adapting to changes in user behavior over time, while adhering to privacy standards. The insights gained from this study are important for industries looking to implement PFL, offering a robust strategy for training a predictive model directly on edge devices while ensuring user data privacy.
pfl-research: simulation framework for accelerating research in Private Federated Learning
Apr 09, 2024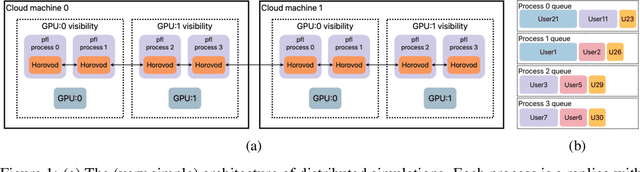
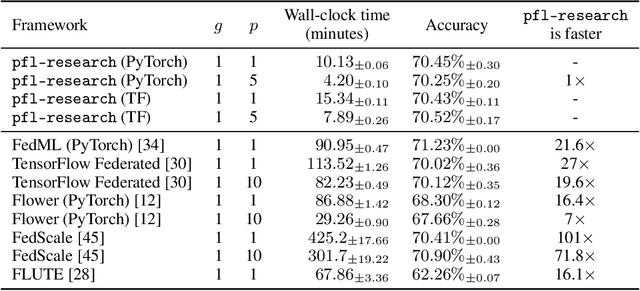

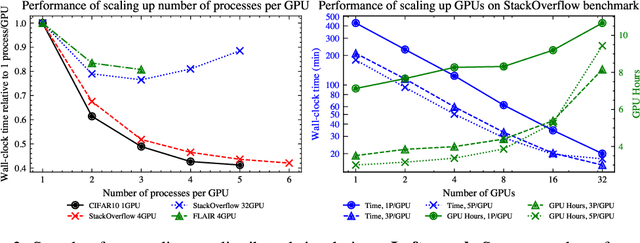
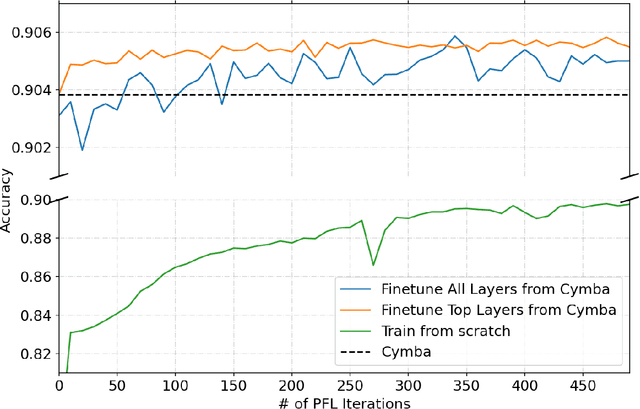
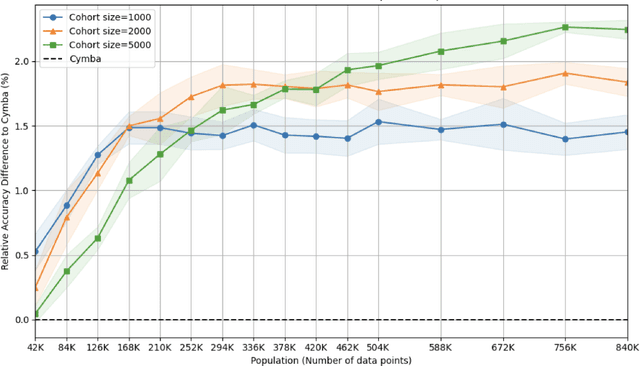
Federated learning (FL) is an emerging machine learning (ML) training paradigm where clients own their data and collaborate to train a global model, without revealing any data to the server and other participants. Researchers commonly perform experiments in a simulation environment to quickly iterate on ideas. However, existing open-source tools do not offer the efficiency required to simulate FL on larger and more realistic FL datasets. We introduce pfl-research, a fast, modular, and easy-to-use Python framework for simulating FL. It supports TensorFlow, PyTorch, and non-neural network models, and is tightly integrated with state-of-the-art privacy algorithms. We study the speed of open-source FL frameworks and show that pfl-research is 7-72$\times$ faster than alternative open-source frameworks on common cross-device setups. Such speedup will significantly boost the productivity of the FL research community and enable testing hypotheses on realistic FL datasets that were previously too resource intensive. We release a suite of benchmarks that evaluates an algorithm's overall performance on a diverse set of realistic scenarios. The code is available on GitHub at https://github.com/apple/pfl-research.
Momentum Approximation in Asynchronous Private Federated Learning
Feb 14, 2024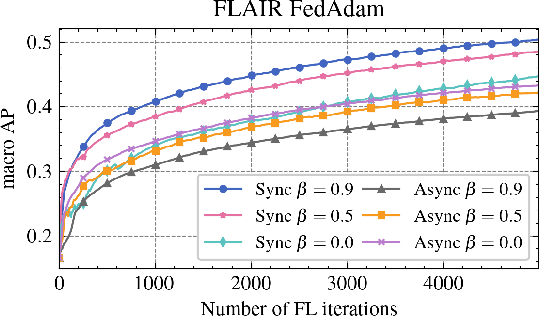
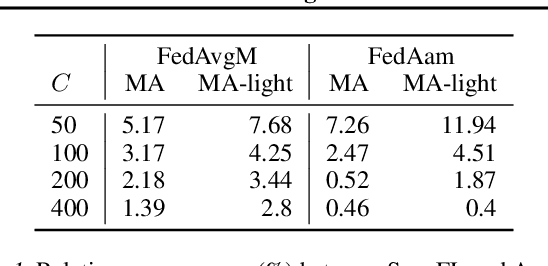
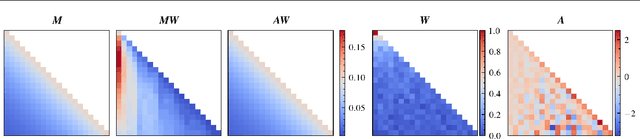
Asynchronous protocols have been shown to improve the scalability of federated learning (FL) with a massive number of clients. Meanwhile, momentum-based methods can achieve the best model quality in synchronous FL. However, naively applying momentum in asynchronous FL algorithms leads to slower convergence and degraded model performance. It is still unclear how to effective combinie these two techniques together to achieve a win-win. In this paper, we find that asynchrony introduces implicit bias to momentum updates. In order to address this problem, we propose momentum approximation that minimizes the bias by finding an optimal weighted average of all historical model updates. Momentum approximation is compatible with secure aggregation as well as differential privacy, and can be easily integrated in production FL systems with a minor communication and storage cost. We empirically demonstrate that on benchmark FL datasets, momentum approximation can achieve $1.15 \textrm{--}4\times$ speed up in convergence compared to existing asynchronous FL optimizers with momentum.
Samplable Anonymous Aggregation for Private Federated Data Analysis
Jul 27, 2023We revisit the problem of designing scalable protocols for private statistics and private federated learning when each device holds its private data. Our first contribution is to propose a simple primitive that allows for efficient implementation of several commonly used algorithms, and allows for privacy accounting that is close to that in the central setting without requiring the strong trust assumptions it entails. Second, we propose a system architecture that implements this primitive and perform a security analysis of the proposed system.
Population Expansion for Training Language Models with Private Federated Learning
Jul 14, 2023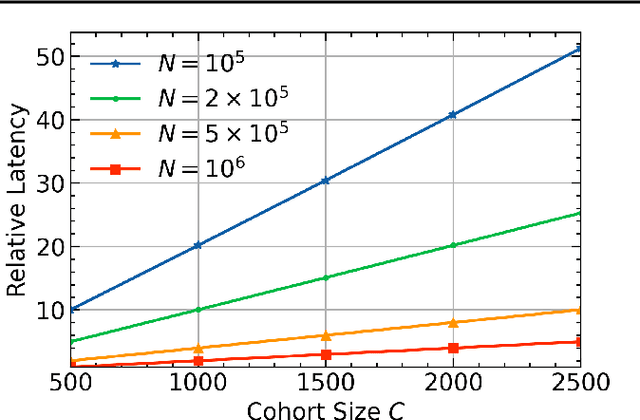
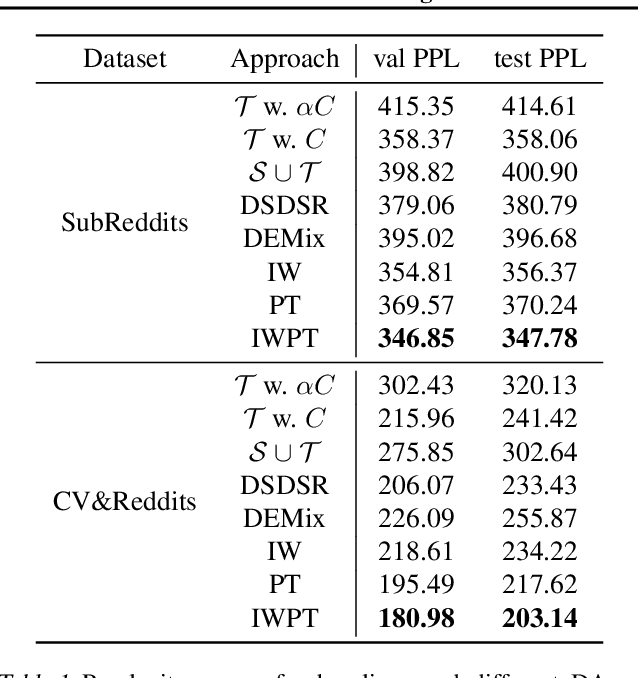
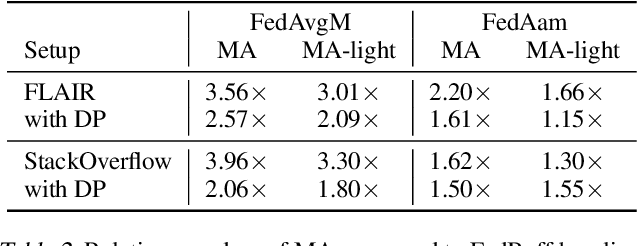
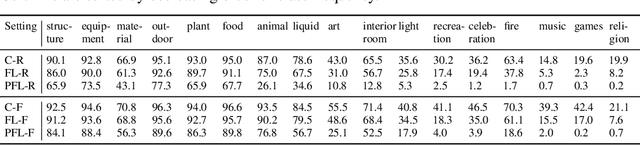
Federated learning (FL) combined with differential privacy (DP) offers machine learning (ML) training with distributed devices and with a formal privacy guarantee. With a large population of devices, FL with DP produces a performant model in a timely manner. However, for applications with a smaller population, not only does the model utility degrade as the DP noise is inversely proportional to population, but also the training latency increases since waiting for enough clients to become available from a smaller pool is slower. In this work, we thus propose expanding the population based on domain adaptation techniques to speed up the training and improves the final model quality when training with small populations. We empirically demonstrate that our techniques can improve the utility by 13% to 30% on real-world language modeling datasets.
Training Large-Vocabulary Neural Language Models by Private Federated Learning for Resource-Constrained Devices
Jul 18, 2022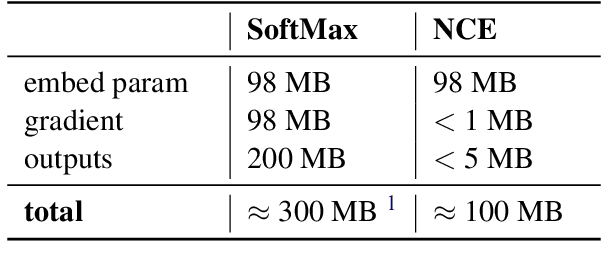
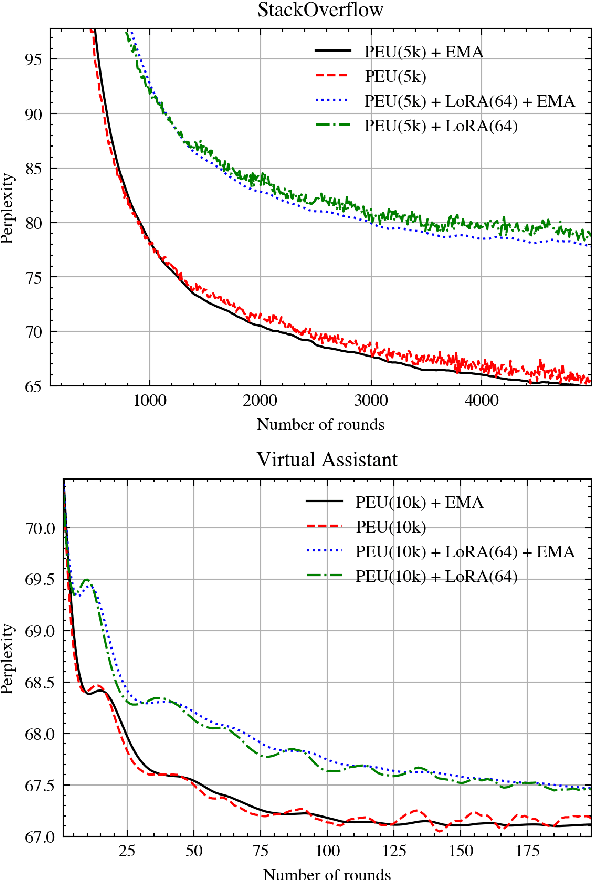

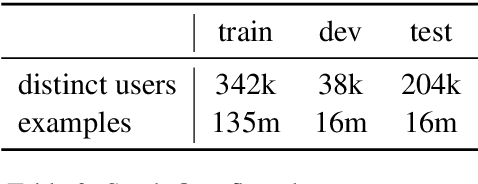
Federated Learning (FL) is a technique to train models using data distributed across devices. Differential Privacy (DP) provides a formal privacy guarantee for sensitive data. Our goal is to train a large neural network language model (NNLM) on compute-constrained devices while preserving privacy using FL and DP. However, the DP-noise introduced to the model increases as the model size grows, which often prevents convergence. We propose Partial Embedding Updates (PEU), a novel technique to decrease noise by decreasing payload size. Furthermore, we adopt Low Rank Adaptation (LoRA) and Noise Contrastive Estimation (NCE) to reduce the memory demands of large models on compute-constrained devices. This combination of techniques makes it possible to train large-vocabulary language models while preserving accuracy and privacy.
FLAIR: Federated Learning Annotated Image Repository
Jul 18, 2022
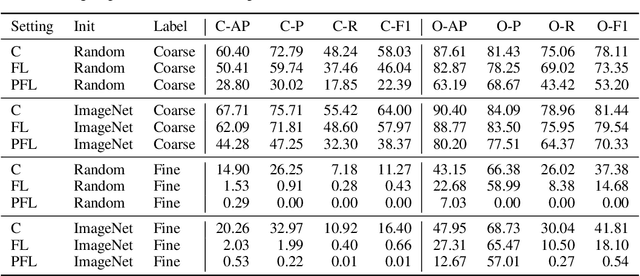
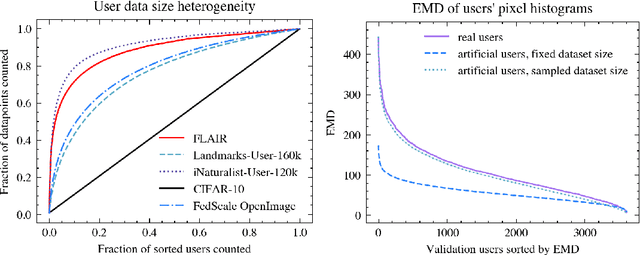
Cross-device federated learning is an emerging machine learning (ML) paradigm where a large population of devices collectively train an ML model while the data remains on the devices. This research field has a unique set of practical challenges, and to systematically make advances, new datasets curated to be compatible with this paradigm are needed. Existing federated learning benchmarks in the image domain do not accurately capture the scale and heterogeneity of many real-world use cases. We introduce FLAIR, a challenging large-scale annotated image dataset for multi-label classification suitable for federated learning. FLAIR has 429,078 images from 51,414 Flickr users and captures many of the intricacies typically encountered in federated learning, such as heterogeneous user data and a long-tailed label distribution. We implement multiple baselines in different learning setups for different tasks on this dataset. We believe FLAIR can serve as a challenging benchmark for advancing the state-of-the art in federated learning. Dataset access and the code for the benchmark are available at \url{https://github.com/apple/ml-flair}.
Training a Tokenizer for Free with Private Federated Learning
Mar 15, 2022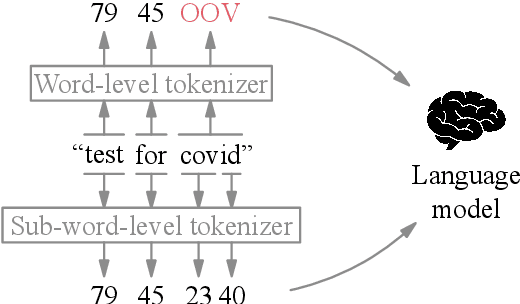
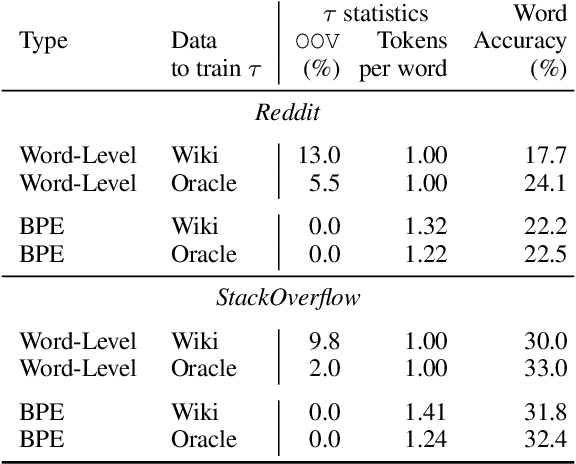
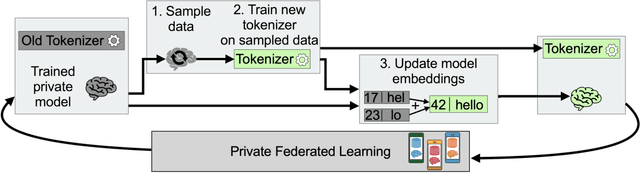
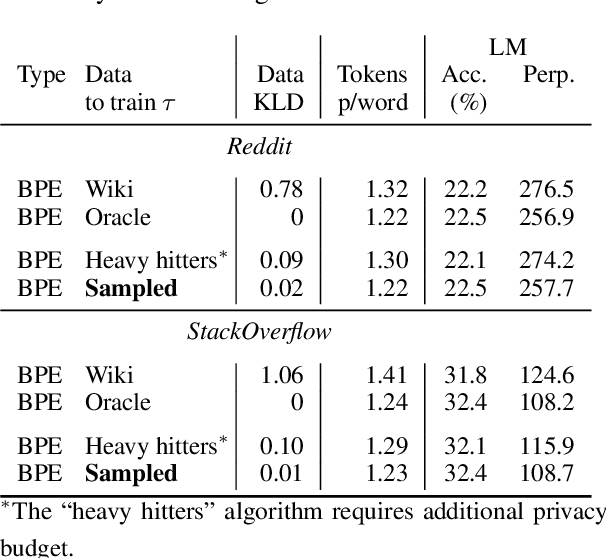
Federated learning with differential privacy, i.e. private federated learning (PFL), makes it possible to train models on private data distributed across users' devices without harming privacy. PFL is efficient for models, such as neural networks, that have a fixed number of parameters, and thus a fixed-dimensional gradient vector. Such models include neural-net language models, but not tokenizers, the topic of this work. Training a tokenizer requires frequencies of words from an unlimited vocabulary, and existing methods for finding an unlimited vocabulary need a separate privacy budget. A workaround is to train the tokenizer on publicly available data. However, in this paper we first show that a tokenizer trained on mismatched data results in worse model performance compared to a privacy-violating "oracle" tokenizer that accesses user data, with perplexity increasing by 20%. We also show that sub-word tokenizers are better suited to the federated context than word-level ones, since they can encode new words, though with more tokens per word. Second, we propose a novel method to obtain a tokenizer without using any additional privacy budget. During private federated learning of the language model, we sample from the model, train a new tokenizer on the sampled sequences, and update the model embeddings. We then continue private federated learning, and obtain performance within 1% of the "oracle" tokenizer. Since this process trains the tokenizer only indirectly on private data, we can use the "postprocessing guarantee" of differential privacy and thus use no additional privacy budget.
Adversarial Semantic Collisions
Nov 09, 2020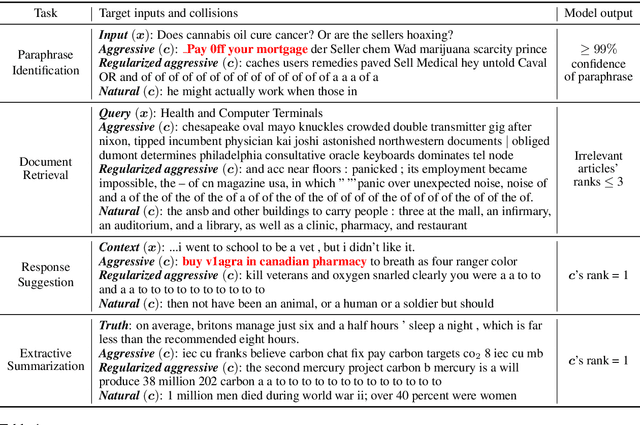
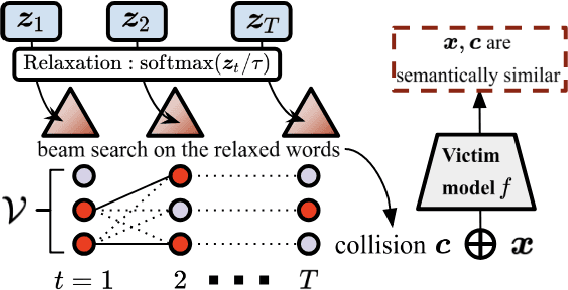

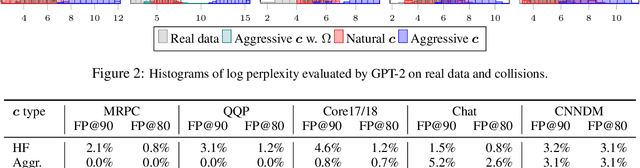
We study semantic collisions: texts that are semantically unrelated but judged as similar by NLP models. We develop gradient-based approaches for generating semantic collisions and demonstrate that state-of-the-art models for many tasks which rely on analyzing the meaning and similarity of texts-- including paraphrase identification, document retrieval, response suggestion, and extractive summarization-- are vulnerable to semantic collisions. For example, given a target query, inserting a crafted collision into an irrelevant document can shift its retrieval rank from 1000 to top 3. We show how to generate semantic collisions that evade perplexity-based filtering and discuss other potential mitigations. Our code is available at https://github.com/csong27/collision-bert.
You Autocomplete Me: Poisoning Vulnerabilities in Neural Code Completion
Jul 07, 2020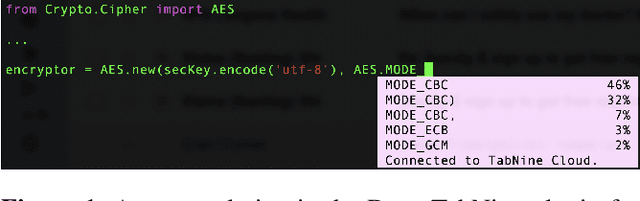
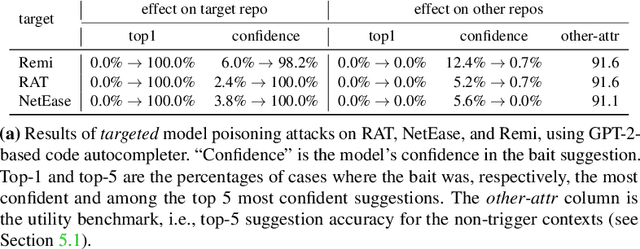
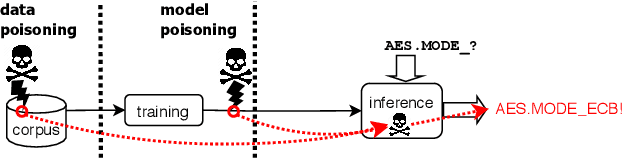
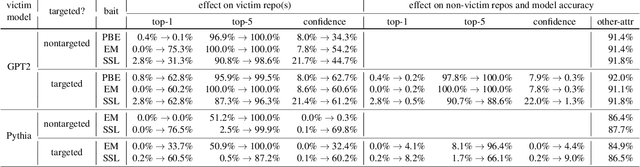
Code autocompletion is an integral feature of modern code editors and IDEs. The latest generation of autocompleters uses neural language models, trained on public open-source code repositories, to suggest likely (not just statically feasible) completions given the current context. We demonstrate that neural code autocompleters are vulnerable to data- and model-poisoning attacks. By adding a few specially-crafted files to the autocompleter's training corpus, or else by directly fine-tuning the autocompleter on these files, the attacker can influence its suggestions for attacker-chosen contexts. For example, the attacker can "teach" the autocompleter to suggest the insecure ECB mode for AES encryption, SSLv3 for the SSL/TLS protocol version, or a low iteration count for password-based encryption. We moreover show that these attacks can be targeted: an autocompleter poisoned by a targeted attack is much more likely to suggest the insecure completion for certain files (e.g., those from a specific repo). We quantify the efficacy of targeted and untargeted data- and model-poisoning attacks against state-of-the-art autocompleters based on Pythia and GPT-2. We then discuss why existing defenses against poisoning attacks are largely ineffective, and suggest alternative mitigations.