 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulation Expansion for Training Language Models with Private Federated Learning
Paper and Code
Jul 14, 2023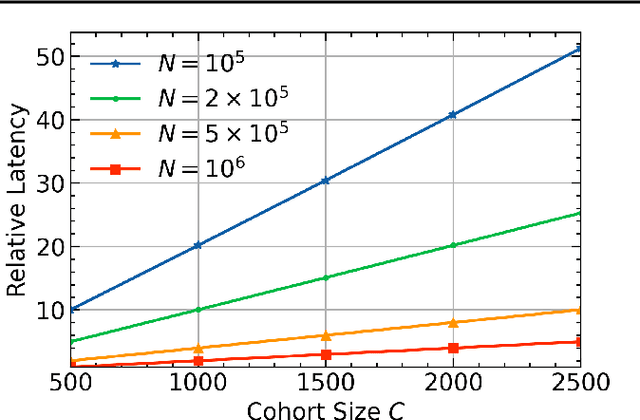
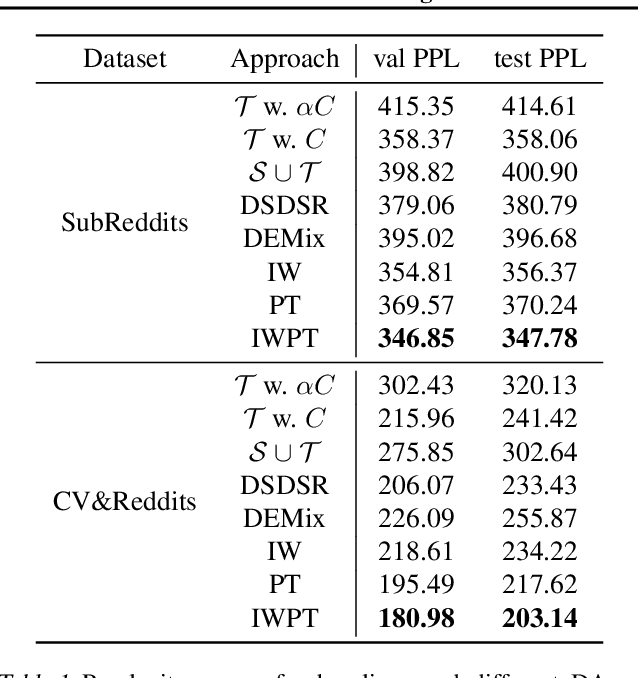
Federated learning (FL) combined with differential privacy (DP) offers machine learning (ML) training with distributed devices and with a formal privacy guarantee. With a large population of devices, FL with DP produces a performant model in a timely manner. However, for applications with a smaller population, not only does the model utility degrade as the DP noise is inversely proportional to population, but also the training latency increases since waiting for enough clients to become available from a smaller pool is slower. In this work, we thus propose expanding the population based on domain adaptation techniques to speed up the training and improves the final model quality when training with small populations. We empirically demonstrate that our techniques can improve the utility by 13% to 30% on real-world language modeling datasets.