 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Retrieval Augmented Generation with Differential Privacy
Dec 06, 2024



With the recent remarkable advancement of large language models (LLMs), there has been a growing interest in utilizing them in the domains with highly sensitive data that lies outside their training data. For this purpose, retrieval augmented generation (RAG) is particularly effective -- it assists LLMs by directly providing relevant information from the external knowledge sources. However, without extra privacy safeguards, RAG outputs risk leaking sensitive information from the external data source. In this work, we explore RAG under differential privacy (DP), a formal guarantee of data privacy. The main challenge with differentially private RAG is how to generate long accurate answers within a moderate privacy budget. We address this by proposing an algorithm that smartly spends privacy budget only for the tokens that require the sensitive information and uses the non-private LLM for other tokens. Our extensive empirical evaluations reveal that our algorithm outperforms the non-RAG baseline under a reasonable privacy budget of $\epsilon\approx 10$ across different models and datasets.
Differentially Private Multi-Site Treatment Effect Estimation
Oct 10, 2023Patient privacy is a major barrier to healthcare AI. For confidentiality reasons, most patient data remains in silo in separate hospitals, preventing the design of data-driven healthcare AI systems that need large volumes of patient data to make effective decisions. A solution to this is collective learning across multiple sites through federated learning with differential privacy. However, literature in this space typically focuses on differentially private statistical estimation and machine learning, which is different from the causal inference-related problems that arise in healthcare. In this work, we take a fresh look at federated learning with a focus on causal inference; specifically, we look at estimating the average treatment effect (ATE), an important task in causal inference for healthcare applications, and provide a federated analytics approach to enable ATE estimation across multiple sites along with differential privacy (DP) guarantees at each site. The main challenge comes from site heterogeneity -- different sites have different sample sizes and privacy budgets. We address this through a class of per-site estimation algorithms that reports the ATE estimate and its variance as a quality measure, and an aggregation algorithm on the server side that minimizes the overall variance of the final ATE estimate. Our experiments on real and synthetic data show that our method reliably aggregates private statistics across sites and provides better privacy-utility tradeoff under site heterogeneity than baselines.
Population Expansion for Training Language Models with Private Federated Learning
Jul 14, 2023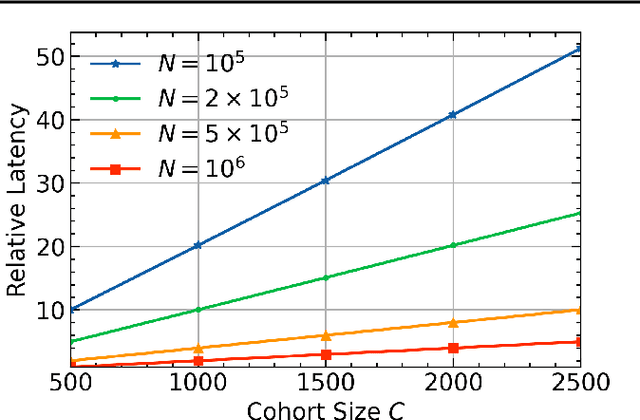
Federated learning (FL) combined with differential privacy (DP) offers machine learning (ML) training with distributed devices and with a formal privacy guarantee. With a large population of devices, FL with DP produces a performant model in a timely manner. However, for applications with a smaller population, not only does the model utility degrade as the DP noise is inversely proportional to population, but also the training latency increases since waiting for enough clients to become available from a smaller pool is slower. In this work, we thus propose expanding the population based on domain adaptation techniques to speed up the training and improves the final model quality when training with small populations. We empirically demonstrate that our techniques can improve the utility by 13% to 30% on real-world language modeling datasets.
Privacy Amplification by Subsampling in Time Domain
Jan 13, 2022
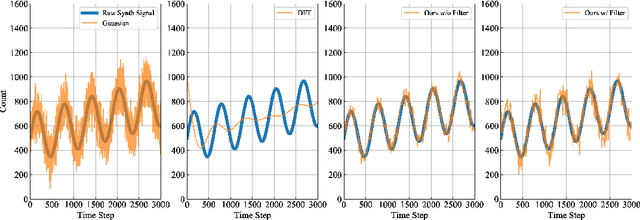

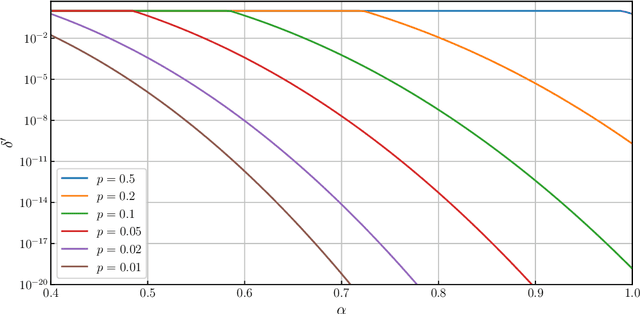
Aggregate time-series data like traffic flow and site occupancy repeatedly sample statistics from a population across time. Such data can be profoundly useful for understanding trends within a given population, but also pose a significant privacy risk, potentially revealing e.g., who spends time where. Producing a private version of a time-series satisfying the standard definition of Differential Privacy (DP) is challenging due to the large influence a single participant can have on the sequence: if an individual can contribute to each time step, the amount of additive noise needed to satisfy privacy increases linearly with the number of time steps sampled. As such, if a signal spans a long duration or is oversampled, an excessive amount of noise must be added, drowning out underlying trends. However, in many applications an individual realistically cannot participate at every time step. When this is the case, we observe that the influence of a single participant (sensitivity) can be reduced by subsampling and/or filtering in time, while still meeting privacy requirements. Using a novel analysis, we show this significant reduction in sensitivity and propose a corresponding class of privacy mechanisms. We demonstrate the utility benefits of these techniques empirically with real-world and synthetic time-series data.
General-to-Detailed GAN for Infrequent Class Medical Images
Nov 28, 2018



Deep learning has significant potential for medical imaging. However, since the incident rate of each disease varies widely, the frequency of classes in a medical image dataset is imbalanced, leading to poor accuracy for such infrequent classes. One possible solution is data augmentation of infrequent classes using synthesized images created by Generative Adversarial Networks (GANs), but conventional GANs also require certain amount of images to learn. To overcome this limitation, here we propose General-to-detailed GAN (GDGAN), serially connected two GANs, one for general labels and the other for detailed labels. GDGAN produced diverse medical images, and the network trained with an augmented dataset outperformed other networks using existing methods with respect to Area-Under-Curve (AUC) of Receiver Operating Characteristic (ROC) curve.