 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgepfl-research: simulation framework for accelerating research in Private Federated Learning
Apr 09, 2024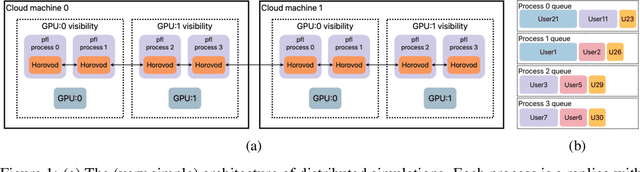
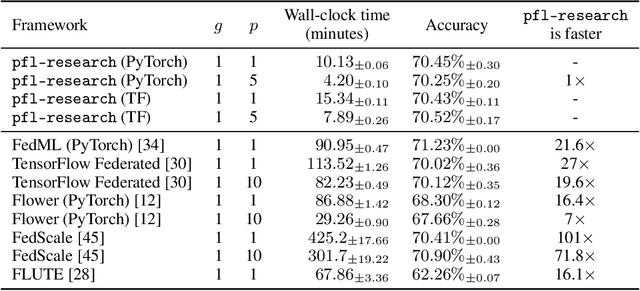

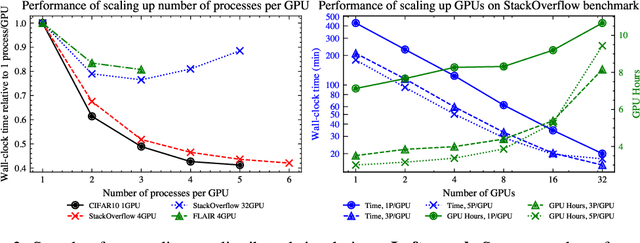
Federated learning (FL) is an emerging machine learning (ML) training paradigm where clients own their data and collaborate to train a global model, without revealing any data to the server and other participants. Researchers commonly perform experiments in a simulation environment to quickly iterate on ideas. However, existing open-source tools do not offer the efficiency required to simulate FL on larger and more realistic FL datasets. We introduce pfl-research, a fast, modular, and easy-to-use Python framework for simulating FL. It supports TensorFlow, PyTorch, and non-neural network models, and is tightly integrated with state-of-the-art privacy algorithms. We study the speed of open-source FL frameworks and show that pfl-research is 7-72$\times$ faster than alternative open-source frameworks on common cross-device setups. Such speedup will significantly boost the productivity of the FL research community and enable testing hypotheses on realistic FL datasets that were previously too resource intensive. We release a suite of benchmarks that evaluates an algorithm's overall performance on a diverse set of realistic scenarios. The code is available on GitHub at https://github.com/apple/pfl-research.
Federated Learning with Differential Privacy for End-to-End Speech Recognition
Sep 29, 2023



While federated learning (FL) has recently emerged as a promising approach to train machine learning models, it is limited to only preliminary explorations in the domain of automatic speech recognition (ASR). Moreover, FL does not inherently guarantee user privacy and requires the use of differential privacy (DP) for robust privacy guarantees. However, we are not aware of prior work on applying DP to FL for ASR. In this paper, we aim to bridge this research gap by formulating an ASR benchmark for FL with DP and establishing the first baselines. First, we extend the existing research on FL for ASR by exploring different aspects of recent $\textit{large end-to-end transformer models}$: architecture design, seed models, data heterogeneity, domain shift, and impact of cohort size. With a $\textit{practical}$ number of central aggregations we are able to train $\textbf{FL models}$ that are \textbf{nearly optimal} even with heterogeneous data, a seed model from another domain, or no pre-trained seed model. Second, we apply DP to FL for ASR, which is non-trivial since DP noise severely affects model training, especially for large transformer models, due to highly imbalanced gradients in the attention block. We counteract the adverse effect of DP noise by reviving per-layer clipping and explaining why its effect is more apparent in our case than in the prior work. Remarkably, we achieve user-level ($7.2$, $10^{-9}$)-$\textbf{DP}$ (resp. ($4.5$, $10^{-9}$)-$\textbf{DP}$) with a 1.3% (resp. 4.6%) absolute drop in the word error rate for extrapolation to high (resp. low) population scale for $\textbf{FL with DP in ASR}$.
Importance of Smoothness Induced by Optimizers in FL4ASR: Towards Understanding Federated Learning for End-to-End ASR
Sep 22, 2023In this paper, we start by training End-to-End Automatic Speech Recognition (ASR) models using Federated Learning (FL) and examining the fundamental considerations that can be pivotal in minimizing the performance gap in terms of word error rate between models trained using FL versus their centralized counterpart. Specifically, we study the effect of (i) adaptive optimizers, (ii) loss characteristics via altering Connectionist Temporal Classification (CTC) weight, (iii) model initialization through seed start, (iv) carrying over modeling setup from experiences in centralized training to FL, e.g., pre-layer or post-layer normalization, and (v) FL-specific hyperparameters, such as number of local epochs, client sampling size, and learning rate scheduler, specifically for ASR under heterogeneous data distribution. We shed light on how some optimizers work better than others via inducing smoothness. We also summarize the applicability of algorithms, trends, and propose best practices from prior works in FL (in general) toward End-to-End ASR models.
Population Expansion for Training Language Models with Private Federated Learning
Jul 14, 2023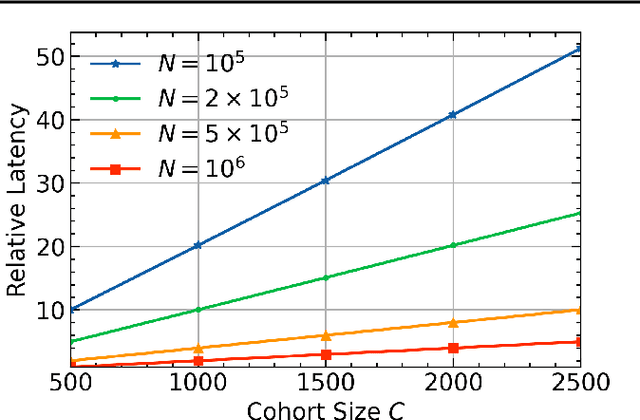
Federated learning (FL) combined with differential privacy (DP) offers machine learning (ML) training with distributed devices and with a formal privacy guarantee. With a large population of devices, FL with DP produces a performant model in a timely manner. However, for applications with a smaller population, not only does the model utility degrade as the DP noise is inversely proportional to population, but also the training latency increases since waiting for enough clients to become available from a smaller pool is slower. In this work, we thus propose expanding the population based on domain adaptation techniques to speed up the training and improves the final model quality when training with small populations. We empirically demonstrate that our techniques can improve the utility by 13% to 30% on real-world language modeling datasets.
An Application of a Multivariate Estimation of Distribution Algorithm to Cancer Chemotherapy
May 17, 2022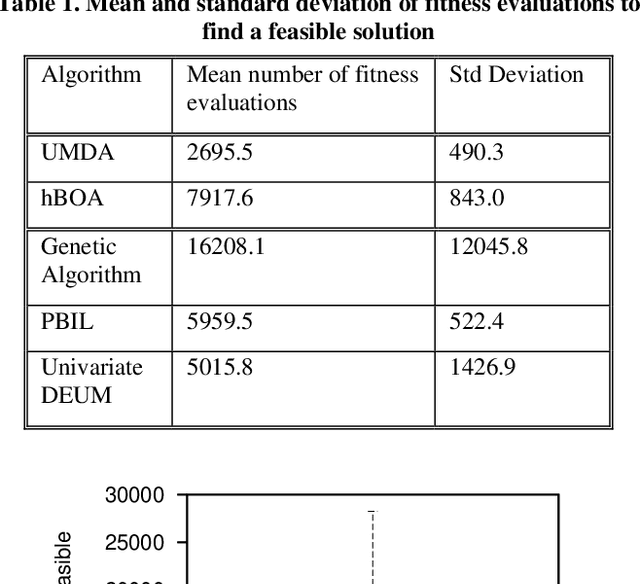
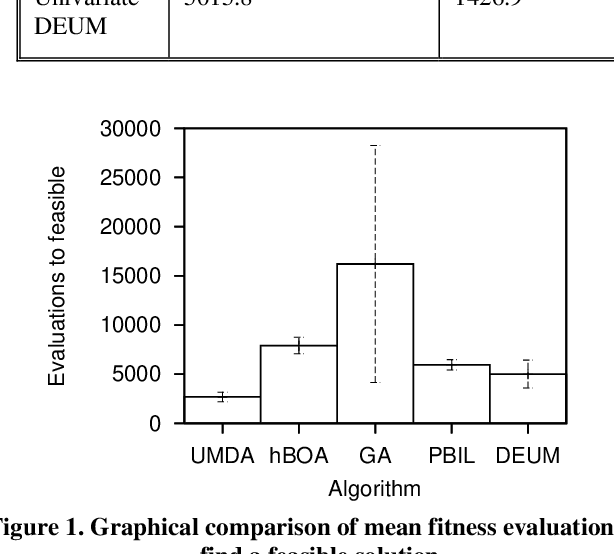
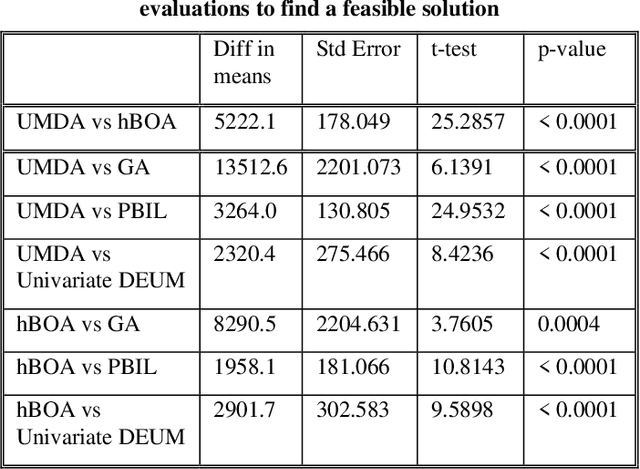
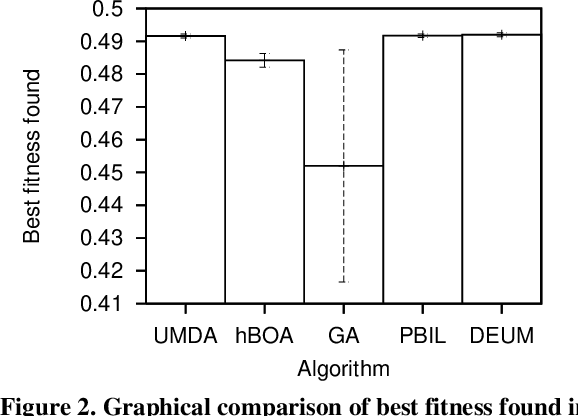
Chemotherapy treatment for cancer is a complex optimisation problem with a large number of interacting variables and constraints. A number of different probabilistic algorithms have been applied to it with varying success. In this paper we expand on this by applying two estimation of distribution algorithms to the problem. One is UMDA, which uses a univariate probabilistic model similar to previously applied EDAs. The other is hBOA, the first EDA using a multivariate probabilistic model to be applied to the chemotherapy problem. While instinct would lead us to predict that the more sophisticated algorithm would yield better performance on a complex problem like this, we show that it is outperformed by the algorithms using the simpler univariate model. We hypothesise that this is caused by the more sophisticated algorithm being impeded by the large number of interactions in the problem which are unnecessary for its solution.
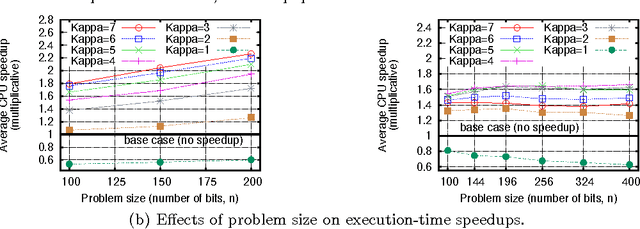
Transfer Learning, Soft Distance-Based Bias, and the Hierarchical BOA
Jun 21, 2012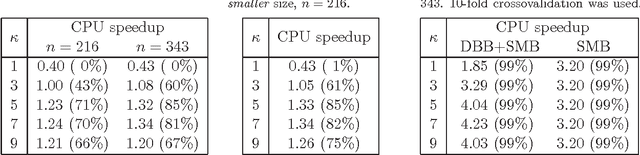
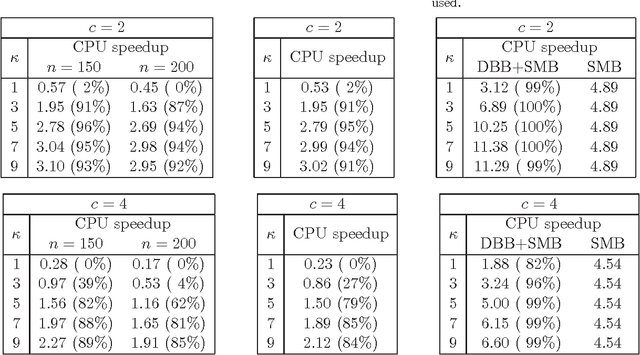
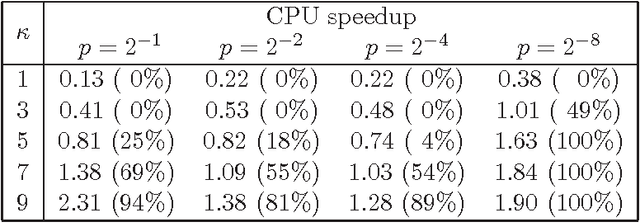
An automated technique has recently been proposed to transfer learning in the hierarchical Bayesian optimization algorithm (hBOA) based on distance-based statistics. The technique enables practitioners to improve hBOA efficiency by collecting statistics from probabilistic models obtained in previous hBOA runs and using the obtained statistics to bias future hBOA runs on similar problems. The purpose of this paper is threefold: (1) test the technique on several classes of NP-complete problems, including MAXSAT, spin glasses and minimum vertex cover; (2) demonstrate that the technique is effective even when previous runs were done on problems of different size; (3) provide empirical evidence that combining transfer learning with other efficiency enhancement techniques can often yield nearly multiplicative speedups.
Distance-Based Bias in Model-Directed Optimization of Additively Decomposable Problems
Jan 11, 2012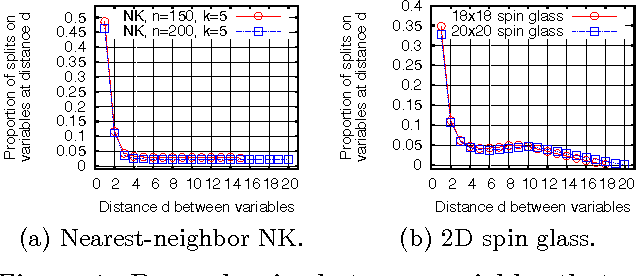
For many optimization problems it is possible to define a distance metric between problem variables that correlates with the likelihood and strength of interactions between the variables. For example, one may define a metric so that the dependencies between variables that are closer to each other with respect to the metric are expected to be stronger than the dependencies between variables that are further apart. The purpose of this paper is to describe a method that combines such a problem-specific distance metric with information mined from probabilistic models obtained in previous runs of estimation of distribution algorithms with the goal of solving future problem instances of similar type with increased speed, accuracy and reliability. While the focus of the paper is on additively decomposable problems and the hierarchical Bayesian optimization algorithm, it should be straightforward to generalize the approach to other model-directed optimization techniques and other problem classes. Compared to other techniques for learning from experience put forward in the past, the proposed technique is both more practical and more broadly applicable.
iBOA: The Incremental Bayesian Optimization Algorithm
Jan 21, 2008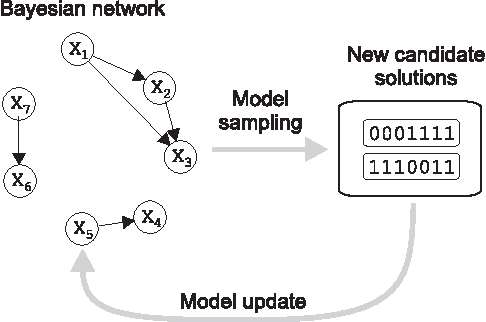
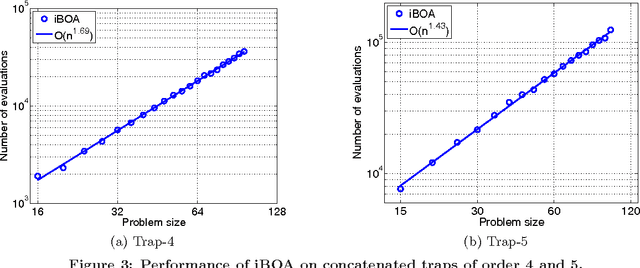
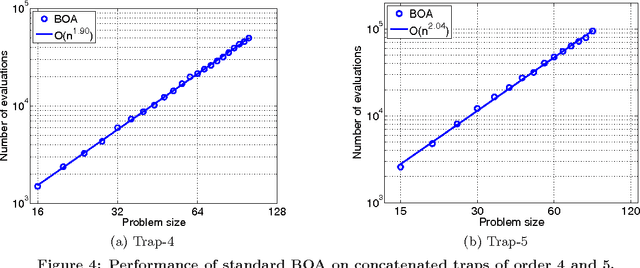
This paper proposes the incremental Bayesian optimization algorithm (iBOA), which modifies standard BOA by removing the population of solutions and using incremental updates of the Bayesian network. iBOA is shown to be able to learn and exploit unrestricted Bayesian networks using incremental techniques for updating both the structure as well as the parameters of the probabilistic model. This represents an important step toward the design of competent incremental estimation of distribution algorithms that can solve difficult nearly decomposable problems scalably and reliably.
* Also available at the MEDAL web site, http://medal.cs.umsl.edu/
Analysis of Estimation of Distribution Algorithms and Genetic Algorithms on NK Landscapes
Jan 21, 2008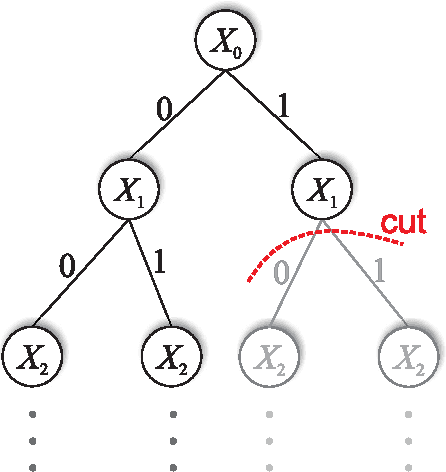
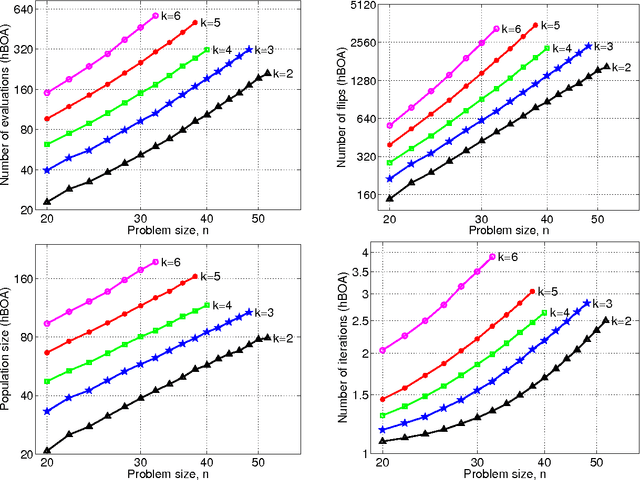
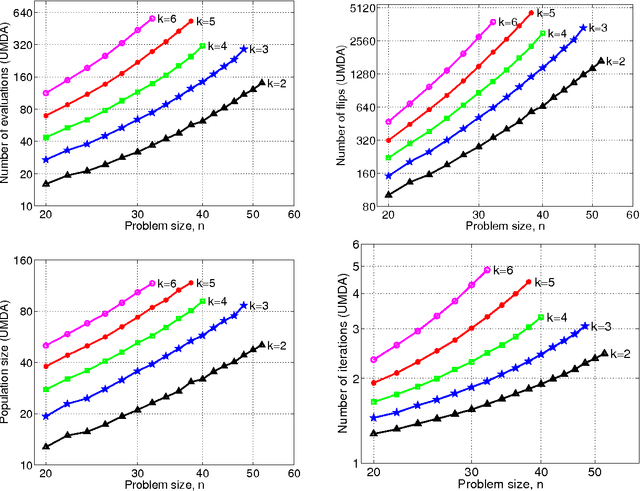
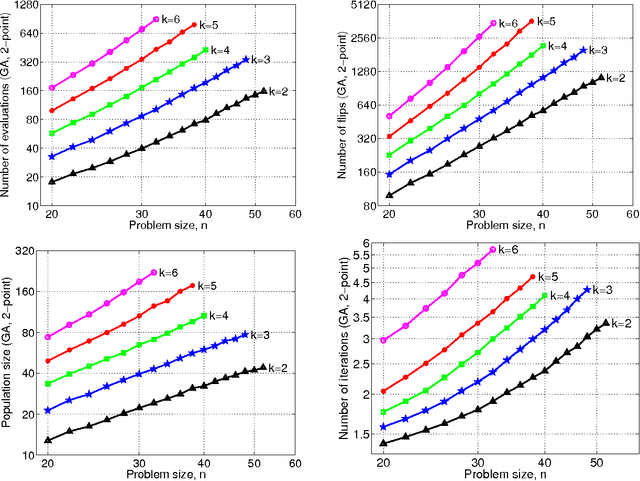
This study analyzes performance of several genetic and evolutionary algorithms on randomly generated NK fitness landscapes with various values of n and k. A large number of NK problem instances are first generated for each n and k, and the global optimum of each instance is obtained using the branch-and-bound algorithm. Next, the hierarchical Bayesian optimization algorithm (hBOA), the univariate marginal distribution algorithm (UMDA), and the simple genetic algorithm (GA) with uniform and two-point crossover operators are applied to all generated instances. Performance of all algorithms is then analyzed and compared, and the results are discussed.
* Also available at the MEDAL web site, http://medal.cs.umsl.edu/
Decomposable Problems, Niching, and Scalability of Multiobjective Estimation of Distribution Algorithms
Feb 12, 2005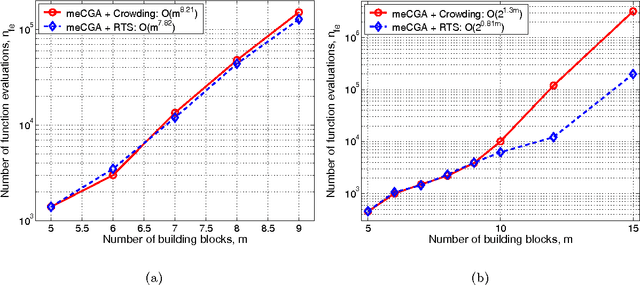
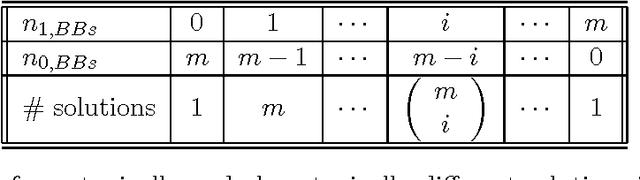

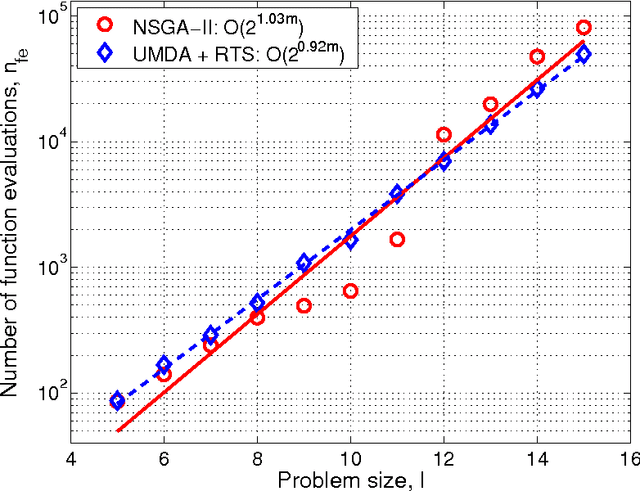
The paper analyzes the scalability of multiobjective estimation of distribution algorithms (MOEDAs) on a class of boundedly-difficult additively-separable multiobjective optimization problems. The paper illustrates that even if the linkage is correctly identified, massive multimodality of the search problems can easily overwhelm the nicher and lead to exponential scale-up. Facetwise models are subsequently used to propose a growth rate of the number of differing substructures between the two objectives to avoid the niching method from being overwhelmed and lead to polynomial scalability of MOEDAs.