 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Differential Privacy for End-to-End Speech Recognition
Sep 29, 2023



While federated learning (FL) has recently emerged as a promising approach to train machine learning models, it is limited to only preliminary explorations in the domain of automatic speech recognition (ASR). Moreover, FL does not inherently guarantee user privacy and requires the use of differential privacy (DP) for robust privacy guarantees. However, we are not aware of prior work on applying DP to FL for ASR. In this paper, we aim to bridge this research gap by formulating an ASR benchmark for FL with DP and establishing the first baselines. First, we extend the existing research on FL for ASR by exploring different aspects of recent $\textit{large end-to-end transformer models}$: architecture design, seed models, data heterogeneity, domain shift, and impact of cohort size. With a $\textit{practical}$ number of central aggregations we are able to train $\textbf{FL models}$ that are \textbf{nearly optimal} even with heterogeneous data, a seed model from another domain, or no pre-trained seed model. Second, we apply DP to FL for ASR, which is non-trivial since DP noise severely affects model training, especially for large transformer models, due to highly imbalanced gradients in the attention block. We counteract the adverse effect of DP noise by reviving per-layer clipping and explaining why its effect is more apparent in our case than in the prior work. Remarkably, we achieve user-level ($7.2$, $10^{-9}$)-$\textbf{DP}$ (resp. ($4.5$, $10^{-9}$)-$\textbf{DP}$) with a 1.3% (resp. 4.6%) absolute drop in the word error rate for extrapolation to high (resp. low) population scale for $\textbf{FL with DP in ASR}$.
Importance of Smoothness Induced by Optimizers in FL4ASR: Towards Understanding Federated Learning for End-to-End ASR
Sep 22, 2023In this paper, we start by training End-to-End Automatic Speech Recognition (ASR) models using Federated Learning (FL) and examining the fundamental considerations that can be pivotal in minimizing the performance gap in terms of word error rate between models trained using FL versus their centralized counterpart. Specifically, we study the effect of (i) adaptive optimizers, (ii) loss characteristics via altering Connectionist Temporal Classification (CTC) weight, (iii) model initialization through seed start, (iv) carrying over modeling setup from experiences in centralized training to FL, e.g., pre-layer or post-layer normalization, and (v) FL-specific hyperparameters, such as number of local epochs, client sampling size, and learning rate scheduler, specifically for ASR under heterogeneous data distribution. We shed light on how some optimizers work better than others via inducing smoothness. We also summarize the applicability of algorithms, trends, and propose best practices from prior works in FL (in general) toward End-to-End ASR models.
Recycling Model Updates in Federated Learning: Are Gradient Subspaces Low-Rank?
Feb 01, 2022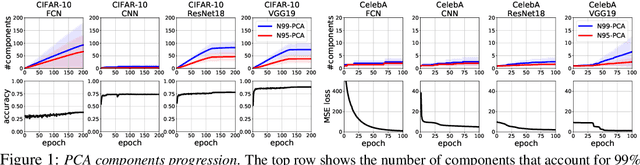
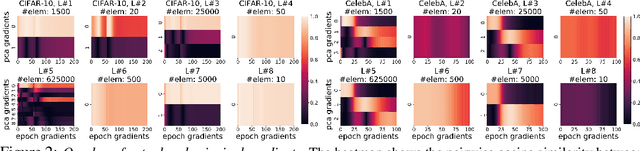
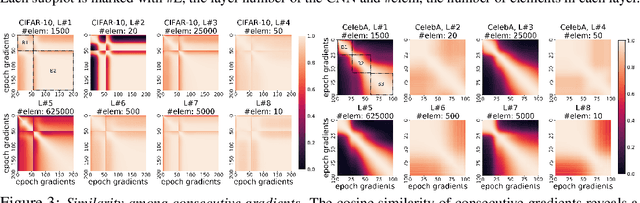
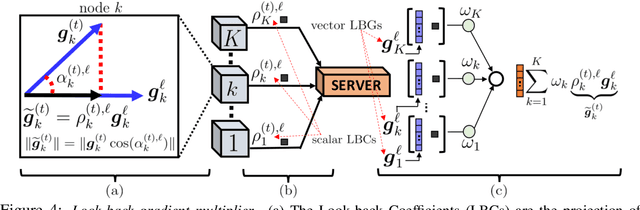
In this paper, we question the rationale behind propagating large numbers of parameters through a distributed system during federated learning. We start by examining the rank characteristics of the subspace spanned by gradients across epochs (i.e., the gradient-space) in centralized model training, and observe that this gradient-space often consists of a few leading principal components accounting for an overwhelming majority (95-99%) of the explained variance. Motivated by this, we propose the "Look-back Gradient Multiplier" (LBGM) algorithm, which exploits this low-rank property to enable gradient recycling between model update rounds of federated learning, reducing transmissions of large parameters to single scalars for aggregation. We analytically characterize the convergence behavior of LBGM, revealing the nature of the trade-off between communication savings and model performance. Our subsequent experimental results demonstrate the improvement LBGM obtains in communication overhead compared to conventional federated learning on several datasets and deep learning models. Additionally, we show that LBGM is a general plug-and-play algorithm that can be used standalone or stacked on top of existing sparsification techniques for distributed model training.
Federated Learning Beyond the Star: Local D2D Model Consensus with Global Cluster Sampling
Sep 12, 2021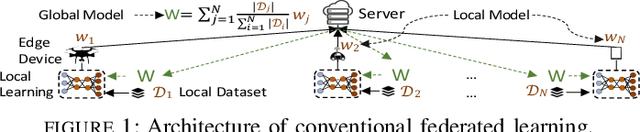
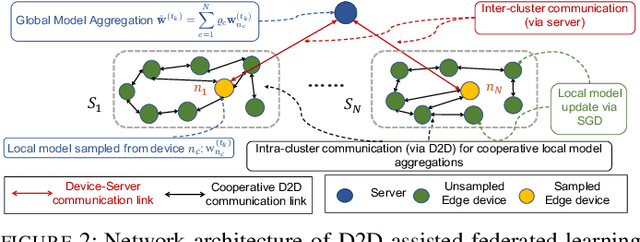
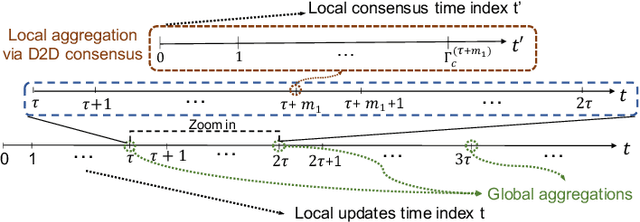
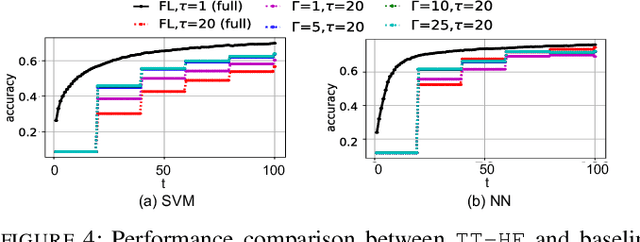
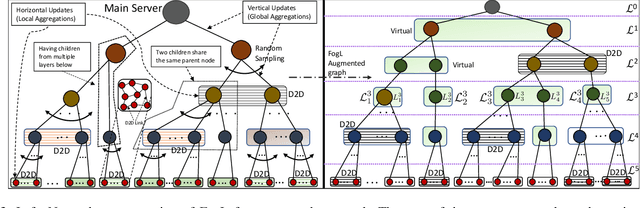
Federated learning has emerged as a popular technique for distributing model training across the network edge. Its learning architecture is conventionally a star topology between the devices and a central server. In this paper, we propose two timescale hybrid federated learning (TT-HF), which migrates to a more distributed topology via device-to-device (D2D) communications. In TT-HF, local model training occurs at devices via successive gradient iterations, and the synchronization process occurs at two timescales: (i) macro-scale, where global aggregations are carried out via device-server interactions, and (ii) micro-scale, where local aggregations are carried out via D2D cooperative consensus formation in different device clusters. Our theoretical analysis reveals how device, cluster, and network-level parameters affect the convergence of TT-HF, and leads to a set of conditions under which a convergence rate of O(1/t) is guaranteed. Experimental results demonstrate the improvements in convergence and utilization that can be obtained by TT-HF over state-of-the-art federated learning baselines.
Two Timescale Hybrid Federated Learning with Cooperative D2D Local Model Aggregations
Mar 18, 2021


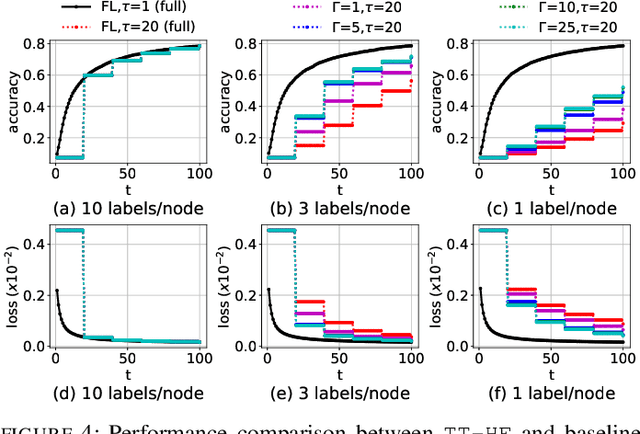
Federated learning has emerged as a popular technique for distributing machine learning (ML) model training across the wireless edge. In this paper, we propose two timescale hybrid federated learning (TT-HF), which is a hybrid between the device-to-server communication paradigm in federated learning and device-to-device (D2D) communications for model training. In TT-HF, during each global aggregation interval, devices (i) perform multiple stochastic gradient descent iterations on their individual datasets, and (ii) aperiodically engage in consensus formation of their model parameters through cooperative, distributed D2D communications within local clusters. With a new general definition of gradient diversity, we formally study the convergence behavior of TT-HF, resulting in new convergence bounds for distributed ML. We leverage our convergence bounds to develop an adaptive control algorithm that tunes the step size, D2D communication rounds, and global aggregation period of TT-HF over time to target a sublinear convergence rate of O(1/t) while minimizing network resource utilization. Our subsequent experiments demonstrate that TT-HF significantly outperforms the current art in federated learning in terms of model accuracy and/or network energy consumption in different scenarios where local device datasets exhibit statistical heterogeneity.
Towards Generalized and Distributed Privacy-Preserving Representation Learning
Oct 17, 2020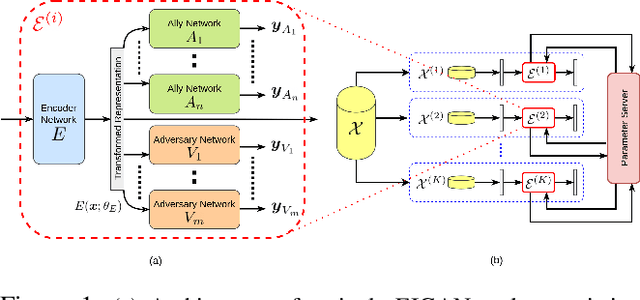
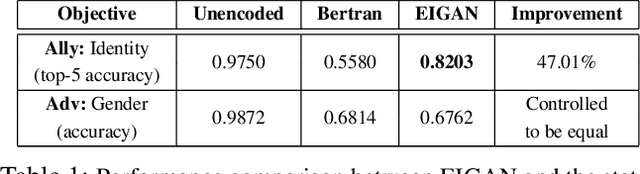
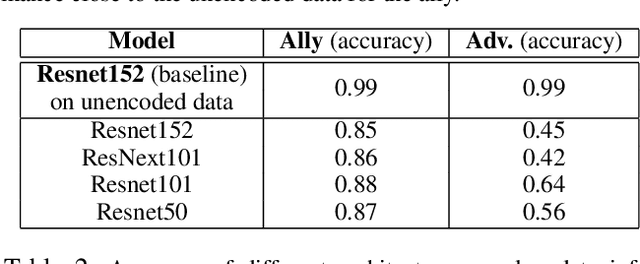
We study the problem of learning data representations that are private yet informative, i.e., providing information about intended "ally" targets while obfuscating sensitive "adversary" attributes. We propose a novel framework, Exclusion-Inclusion Generative Adversarial Network (EIGAN), that generalizes existing adversarial privacy-preserving representation learning (PPRL) approaches to generate data encodings that account for multiple possibly overlapping ally and adversary targets. Preserving privacy is even more difficult when the data is collected across multiple distributed nodes, which for privacy reasons may not wish to share their data even for PPRL training. Thus, learning such data representations at each node in a distributed manner (i.e., without transmitting source data) is of particular importance. This motivates us to develop D-EIGAN, the first distributed PPRL method, based on federated learning with fractional parameter sharing to account for communication resource limitations. We theoretically analyze the behavior of adversaries under the optimal EIGAN and D-EIGAN encoders and consider the impact of dependencies among ally and adversary tasks on the encoder performance. Our experiments on real-world and synthetic datasets demonstrate the advantages of EIGAN encodings in terms of accuracy, robustness, and scalability; in particular, we show that EIGAN outperforms the previous state-of-the-art by a significant accuracy margin (47% improvement). The experiments further reveal that D-EIGAN's performance is consistent with EIGAN under different node data distributions and is resilient to communication constraints.
Multi-Stage Hybrid Federated Learning over Large-Scale Wireless Fog Networks
Aug 30, 2020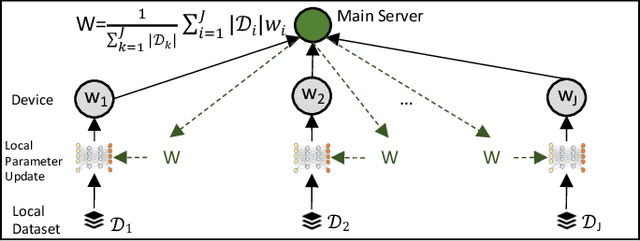
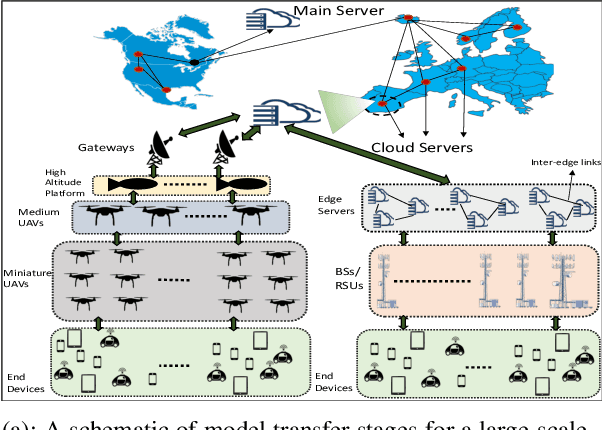
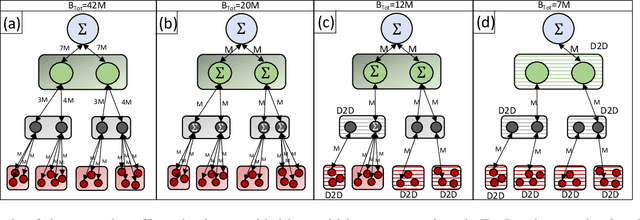
One of the popular methods for distributed machine learning (ML) is federated learning, in which devices train local models based on their datasets, which are in turn aggregated periodically by a server. In large-scale fog networks, the "star" learning topology of federated learning poses several challenges in terms of resource utilization. We develop multi-stage hybrid model training (MH-MT), a novel learning methodology for distributed ML in these scenarios. Leveraging the hierarchical structure of fog systems, MH-MT combines multi-stage parameter relaying with distributed consensus formation among devices in a hybrid learning paradigm across network layers. We theoretically derive the convergence bound of MH-MT with respect to the network topology, ML model, and algorithm parameters such as the rounds of consensus employed in different clusters of devices. We obtain a set of policies for the number of consensus rounds at different clusters to guarantee either a finite optimality gap or convergence to the global optimum. Subsequently, we develop an adaptive distributed control algorithm for MH-MT to tune the number of consensus rounds at each cluster of local devices over time to meet convergence criteria. Our numerical experiments validate the performance of MH-MT in terms of convergence speed and resource utilization.
Q-Map: Clinical Concept Mining from Clinical Documents
Jul 16, 2018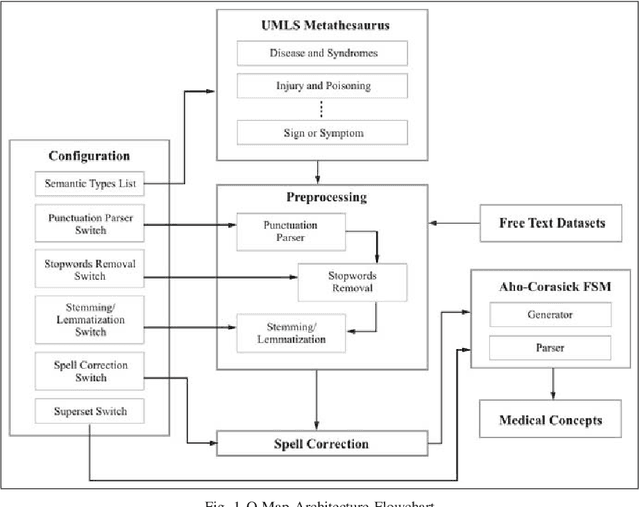
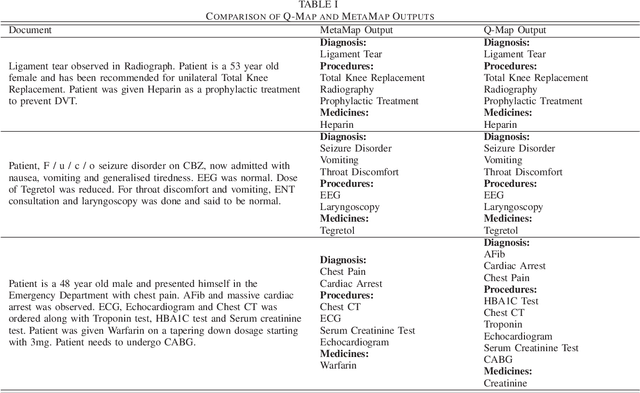
Over the past decade, there has been a steep rise in the data-driven analysis in major areas of medicine, such as clinical decision support system, survival analysis, patient similarity analysis, image analytics etc. Most of the data in the field are well-structured and available in numerical or categorical formats which can be used for experiments directly. But on the opposite end of the spectrum, there exists a wide expanse of data that is intractable for direct analysis owing to its unstructured nature which can be found in the form of discharge summaries, clinical notes, procedural notes which are in human written narrative format and neither have any relational model nor any standard grammatical structure. An important step in the utilization of these texts for such studies is to transform and process the data to retrieve structured information from the haystack of irrelevant data using information retrieval and data mining techniques. To address this problem, the authors present Q-Map in this paper, which is a simple yet robust system that can sift through massive datasets with unregulated formats to retrieve structured information aggressively and efficiently. It is backed by an effective mining technique which is based on a string matching algorithm that is indexed on curated knowledge sources, that is both fast and configurable. The authors also briefly examine its comparative performance with MetaMap, one of the most reputed tools for medical concepts retrieval and present the advantages the former displays over the latter.