 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterference-Robust Non-Coherent Over-the-Air Computation for Decentralized Optimization
Feb 12, 2026Non-coherent over-the-air (NCOTA) computation enables low-latency and bandwidth-efficient decentralized optimization by exploiting the average energy superposition property of wireless channels. It has recently been proposed as a powerful tool for executing consensus-based optimization algorithms in fully decentralized systems. A key advantage of NCOTA is that it enables unbiased consensus estimation without channel state information at either transmitters or receivers, requires no transmission scheduling, and scales efficiently to dense network deployments. However, NCOTA is inherently susceptible to external interference, which can bias the consensus estimate and deteriorate the convergence of the underlying decentralized optimization algorithm. In this paper, we propose a novel interference-robust (IR-)NCOTA scheme. The core idea is to apply a coordinated random rotation of the frame of reference across all nodes, and transmit a pseudo-random pilot signal, allowing to transform external interference into a circularly symmetric distribution with zero mean relative to the rotated frame. This ensures that the consensus estimates remain unbiased, preserving the convergence guarantees of the underlying optimization algorithm. Through numerical results on a classification task, it is demonstrated that IR-NCOTA exhibits superior performance over the baseline NCOTA algorithm in the presence of external interference.
Non-Convex Over-the-Air Heterogeneous Federated Learning: A Bias-Variance Trade-off
Oct 30, 2025Over-the-air (OTA) federated learning (FL) has been well recognized as a scalable paradigm that exploits the waveform superposition of the wireless multiple-access channel to aggregate model updates in a single use. Existing OTA-FL designs largely enforce zero-bias model updates by either assuming \emph{homogeneous} wireless conditions (equal path loss across devices) or forcing zero-bias updates to guarantee convergence. Under \emph{heterogeneous} wireless scenarios, however, such designs are constrained by the weakest device and inflate the update variance. Moreover, prior analyses of biased OTA-FL largely address convex objectives, while most modern AI models are highly non-convex. Motivated by these gaps, we study OTA-FL with stochastic gradient descent (SGD) for general smooth non-convex objectives under wireless heterogeneity. We develop novel OTA-FL SGD updates that allow a structured, time-invariant model bias while facilitating reduced variance updates. We derive a finite-time stationarity bound (expected time average squared gradient norm) that explicitly reveals a bias-variance trade-off. To optimize this trade-off, we pose a non-convex joint OTA power-control design and develop an efficient successive convex approximation (SCA) algorithm that requires only statistical CSI at the base station. Experiments on a non-convex image classification task validate the approach: the SCA-based design accelerates convergence via an optimized bias and improves generalization over prior OTA-FL baselines.
Biased Federated Learning under Wireless Heterogeneity
Mar 08, 2025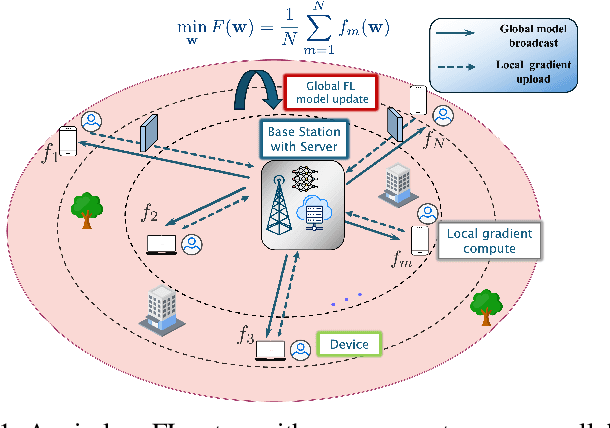
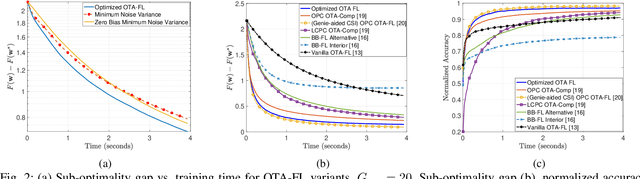
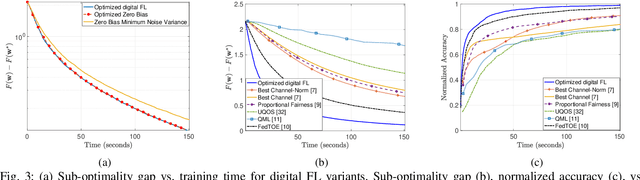
Federated learning (FL) has emerged as a promising framework for distributed learning, enabling collaborative model training without sharing private data. Existing wireless FL works primarily adopt two communication strategies: (1) over-the-air (OTA) computation, which exploits wireless signal superposition for simultaneous gradient aggregation, and (2) digital communication, which allocates orthogonal resources for gradient uploads. Prior works on both schemes typically assume \emph{homogeneous} wireless conditions (equal path loss across devices) to enforce zero-bias updates or permit uncontrolled bias, resulting in suboptimal performance and high-variance model updates in \emph{heterogeneous} environments, where devices with poor channel conditions slow down convergence. This paper addresses FL over heterogeneous wireless networks by proposing novel OTA and digital FL updates that allow a structured, time-invariant model bias, thereby reducing variance in FL updates. We analyze their convergence under a unified framework and derive an upper bound on the model ``optimality error", which explicitly quantifies the effect of bias and variance in terms of design parameters. Next, to optimize this trade-off, we study a non-convex optimization problem and develop a successive convex approximation (SCA)-based framework to jointly optimize the design parameters. We perform extensive numerical evaluations with several related design variants and state-of-the-art OTA and digital FL schemes. Our results confirm that minimizing the bias-variance trade-off while allowing a structured bias provides better FL convergence performance than existing schemes.
NCAirFL: CSI-Free Over-the-Air Federated Learning Based on Non-Coherent Detection
Nov 20, 2024


Over-the-air federated learning (FL), i.e., AirFL, leverages computing primitively over multiple access channels. A long-standing challenge in AirFL is to achieve coherent signal alignment without relying on expensive channel estimation and feedback. This paper proposes NCAirFL, a CSI-free AirFL scheme based on unbiased non-coherent detection at the edge server. By exploiting binary dithering and a long-term memory based error-compensation mechanism, NCAirFL achieves a convergence rate of order $\mathcal{O}(1/\sqrt{T})$ in terms of the average square norm of the gradient for general non-convex and smooth objectives, where $T$ is the number of communication rounds. Experiments demonstrate the competitive performance of NCAirFL compared to vanilla FL with ideal communications and to coherent transmission-based benchmarks.
Biased Over-the-Air Federated Learning under Wireless Heterogeneity
Mar 28, 2024Recently, Over-the-Air (OTA) computation has emerged as a promising federated learning (FL) paradigm that leverages the waveform superposition properties of the wireless channel to realize fast model updates. Prior work focused on the OTA device ``pre-scaler" design under \emph{homogeneous} wireless conditions, in which devices experience the same average path loss, resulting in zero-bias solutions. Yet, zero-bias designs are limited by the device with the worst average path loss and hence may perform poorly in \emph{heterogeneous} wireless settings. In this scenario, there may be a benefit in designing \emph{biased} solutions, in exchange for a lower variance in the model updates. To optimize this trade-off, we study the design of OTA device pre-scalers by focusing on the OTA-FL convergence. We derive an upper bound on the model ``optimality error", which explicitly captures the effect of bias and variance in terms of the choice of the pre-scalers. Based on this bound, we identify two solutions of interest: minimum noise variance, and minimum noise variance zero-bias solutions. Numerical evaluations show that using OTA device pre-scalers that minimize the variance of FL updates, while allowing a small bias, can provide high gains over existing schemes.
Analog-digital Scheduling for Federated Learning: A Communication-Efficient Approach
Feb 02, 2024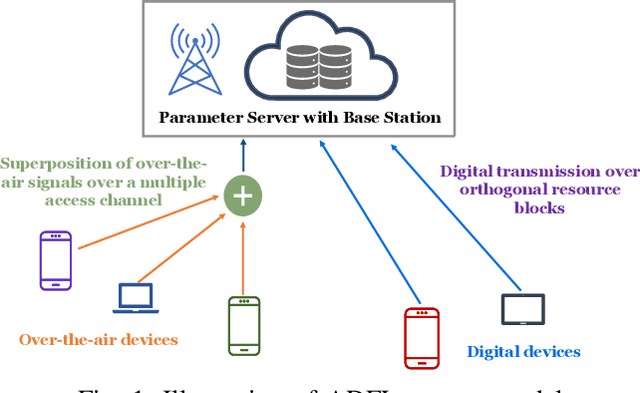
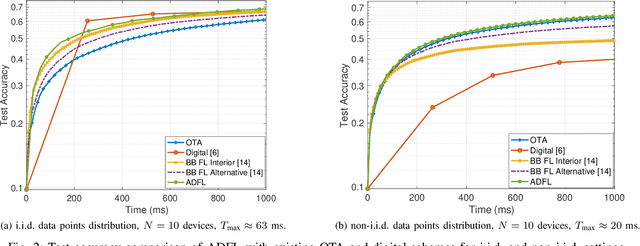
Over-the-air (OTA) computation has recently emerged as a communication-efficient Federated Learning (FL) paradigm to train machine learning models over wireless networks. However, its performance is limited by the device with the worst SNR, resulting in fast yet noisy updates. On the other hand, allocating orthogonal resource blocks (RB) to individual devices via digital channels mitigates the noise problem, at the cost of increased communication latency. In this paper, we address this discrepancy and present ADFL, a novel Analog-Digital FL scheme: in each round, the parameter server (PS) schedules each device to either upload its gradient via the analog OTA scheme or transmit its quantized gradient over an orthogonal RB using the ``digital" scheme. Focusing on a single FL round, we cast the optimal scheduling problem as the minimization of the mean squared error (MSE) on the estimated global gradient at the PS, subject to a delay constraint, yielding the optimal device scheduling configuration and quantization bits for the digital devices. Our simulation results show that ADFL, by scheduling most of the devices in the OTA scheme while also occasionally employing the digital scheme for a few devices, consistently outperforms OTA-only and digital-only schemes, in both i.i.d. and non-i.i.d. settings.
Delay-Aware Hierarchical Federated Learning
Mar 23, 2023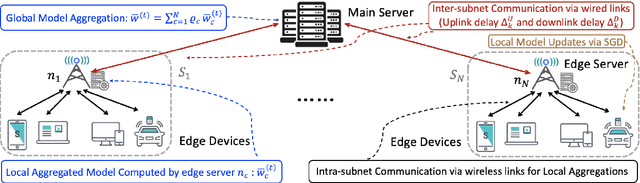
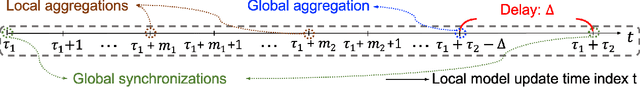
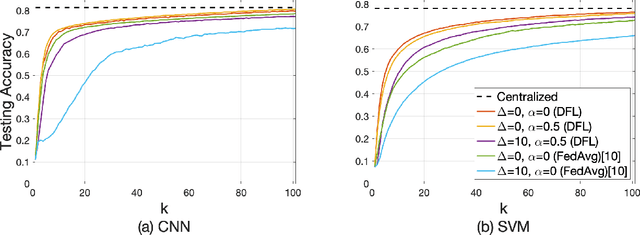
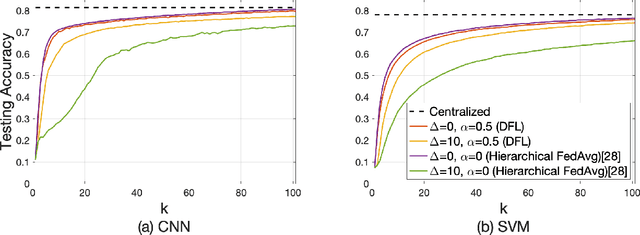
Federated learning has gained popularity as a means of training models distributed across the wireless edge. The paper introduces delay-aware federated learning (DFL) to improve the efficiency of distributed machine learning (ML) model training by addressing communication delays between edge and cloud. DFL employs multiple stochastic gradient descent iterations on device datasets during each global aggregation interval and intermittently aggregates model parameters through edge servers in local subnetworks. The cloud server synchronizes the local models with the global deployed model computed via a local-global combiner at global synchronization. The convergence behavior of DFL is theoretically investigated under a generalized data heterogeneity metric. A set of conditions is obtained to achieve the sub-linear convergence rate of O(1/k). Based on these findings, an adaptive control algorithm is developed for DFL, implementing policies to mitigate energy consumption and edge-to-cloud communication latency while aiming for a sublinear convergence rate. Numerical evaluations show DFL's superior performance in terms of faster global model convergence, reduced resource consumption, and robustness against communication delays compared to existing FL algorithms. In summary, this proposed method offers improved efficiency and satisfactory results when dealing with both convex and non-convex loss functions.
Decentralized Federated Learning via Non-Coherent Over-the-Air Consensus
Oct 27, 2022This paper presents NCOTA-DGD, a Decentralized Gradient Descent (DGD) algorithm that combines local gradient descent with Non-Coherent Over-The-Air (NCOTA) consensus at the receivers to solve distributed machine-learning problems over wirelessly-connected systems. NCOTA-DGD leverages the waveform superposition properties of the wireless channels: it enables simultaneous transmissions under half-duplex constraints, by mapping local signals to a mixture of preamble sequences, and consensus via non-coherent combining at the receivers. NCOTA-DGD operates without channel state information and leverages the average channel pathloss to mix signals, without explicit knowledge of the mixing weights (typically known in consensus-based optimization algorithms). It is shown both theoretically and numerically that, for smooth and strongly-convex problems with fixed consensus and learning stepsizes, the updates of NCOTA-DGD converge (in Euclidean distance) to the global optimum with rate $\mathcal O(K^{-1/4})$ for a target number of iterations $K$. NCOTA-DGD is evaluated numerically over a logistic regression problem, showing faster convergence vis-\`a-vis running time than implementations of the classical DGD algorithm over digital and analog orthogonal channels.
Federated Learning Beyond the Star: Local D2D Model Consensus with Global Cluster Sampling
Sep 12, 2021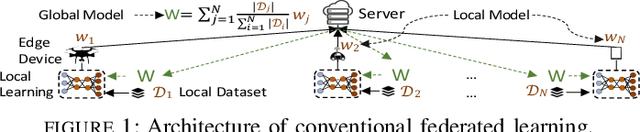
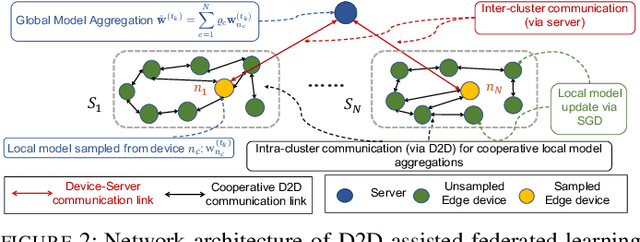
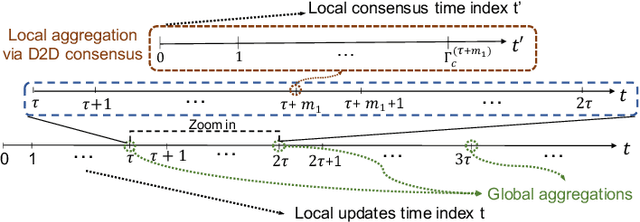
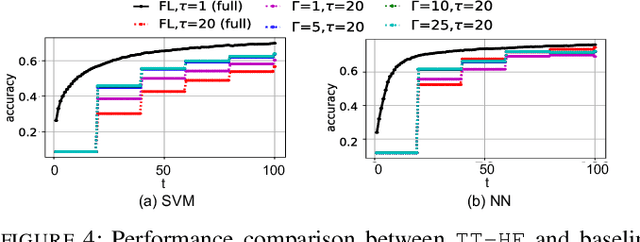
Federated learning has emerged as a popular technique for distributing model training across the network edge. Its learning architecture is conventionally a star topology between the devices and a central server. In this paper, we propose two timescale hybrid federated learning (TT-HF), which migrates to a more distributed topology via device-to-device (D2D) communications. In TT-HF, local model training occurs at devices via successive gradient iterations, and the synchronization process occurs at two timescales: (i) macro-scale, where global aggregations are carried out via device-server interactions, and (ii) micro-scale, where local aggregations are carried out via D2D cooperative consensus formation in different device clusters. Our theoretical analysis reveals how device, cluster, and network-level parameters affect the convergence of TT-HF, and leads to a set of conditions under which a convergence rate of O(1/t) is guaranteed. Experimental results demonstrate the improvements in convergence and utilization that can be obtained by TT-HF over state-of-the-art federated learning baselines.
Finite-Bit Quantization For Distributed Algorithms With Linear Convergence
Jul 23, 2021
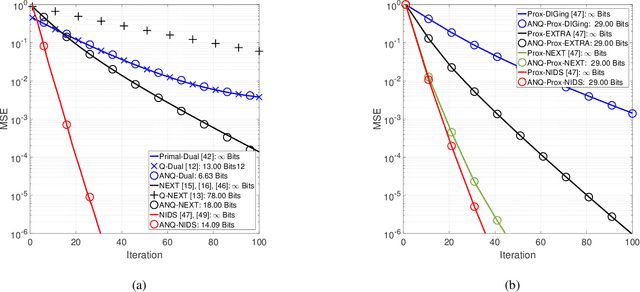
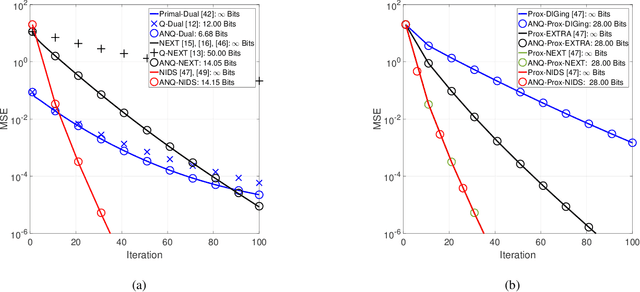

This paper studies distributed algorithms for (strongly convex) composite optimization problems over mesh networks, subject to quantized communications. Instead of focusing on a specific algorithmic design, we propose a black-box model casting distributed algorithms in the form of fixed-point iterates, converging at linear rate. The algorithmic model is coupled with a novel (random) Biased Compression (BC-)rule on the quantizer design, which preserves linear convergence. A new quantizer coupled with a communication-efficient encoding scheme is also proposed, which efficiently implements the BC-rule using a finite number of bits. This contrasts with most of existing quantization rules, whose implementation calls for an infinite number of bits. A unified communication complexity analysis is developed for the black-box model, determining the average number of bit required to reach a solution of the optimization problem within the required accuracy. Numerical results validate our theoretical findings and show that distributed algorithms equipped with the proposed quantizer have more favorable communication complexity than algorithms using existing quantization rules.