 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiased Federated Learning under Wireless Heterogeneity
Paper and Code
Mar 08, 2025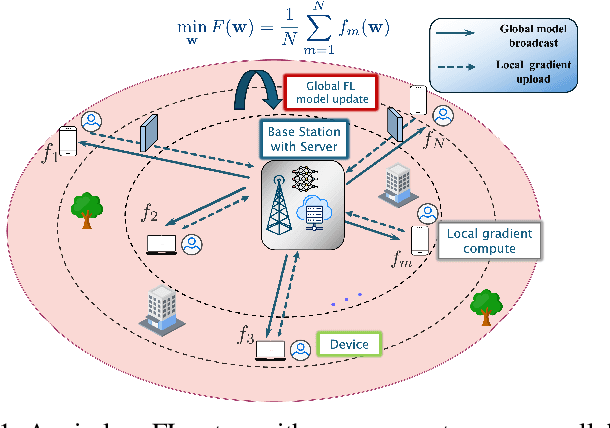
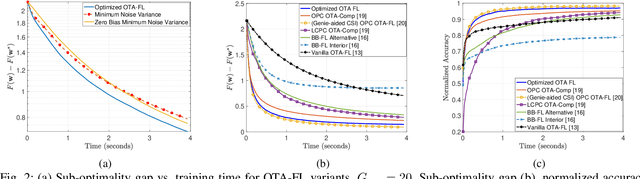
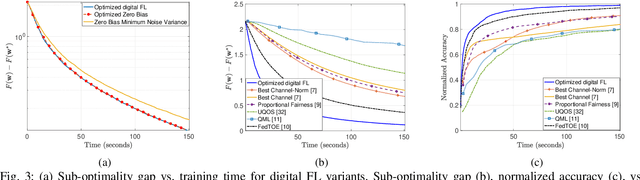
Federated learning (FL) has emerged as a promising framework for distributed learning, enabling collaborative model training without sharing private data. Existing wireless FL works primarily adopt two communication strategies: (1) over-the-air (OTA) computation, which exploits wireless signal superposition for simultaneous gradient aggregation, and (2) digital communication, which allocates orthogonal resources for gradient uploads. Prior works on both schemes typically assume \emph{homogeneous} wireless conditions (equal path loss across devices) to enforce zero-bias updates or permit uncontrolled bias, resulting in suboptimal performance and high-variance model updates in \emph{heterogeneous} environments, where devices with poor channel conditions slow down convergence. This paper addresses FL over heterogeneous wireless networks by proposing novel OTA and digital FL updates that allow a structured, time-invariant model bias, thereby reducing variance in FL updates. We analyze their convergence under a unified framework and derive an upper bound on the model ``optimality error", which explicitly quantifies the effect of bias and variance in terms of design parameters. Next, to optimize this trade-off, we study a non-convex optimization problem and develop a successive convex approximation (SCA)-based framework to jointly optimize the design parameters. We perform extensive numerical evaluations with several related design variants and state-of-the-art OTA and digital FL schemes. Our results confirm that minimizing the bias-variance trade-off while allowing a structured bias provides better FL convergence performance than existing schemes.