 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSporadic Gradient Tracking over Directed Graphs: A Theoretical Perspective on Decentralized Federated Learning
Jan 31, 2026Decentralized Federated Learning (DFL) enables clients with local data to collaborate in a peer-to-peer manner to train a generalized model. In this paper, we unify two branches of work that have separately solved important challenges in DFL: (i) gradient tracking techniques for mitigating data heterogeneity and (ii) accounting for diverse availability of resources across clients. We propose $\textit{Sporadic Gradient Tracking}$ ($\texttt{Spod-GT}$), the first DFL algorithm that incorporates these factors over general directed graphs by allowing (i) client-specific gradient computation frequencies and (ii) heterogeneous and asymmetric communication frequencies. We conduct a rigorous convergence analysis of our methodology with relaxed assumptions on gradient estimation variance and gradient diversity of clients, providing consensus and optimality guarantees for GT over directed graphs despite intermittent client participation. Through numerical experiments on image classification datasets, we demonstrate the efficacy of $\texttt{Spod-GT}$ compared to well-known GT baselines.
Joint Continual Learning of Local Language Models and Cloud Offloading Decisions with Budget Constraints
Jan 29, 2026Locally deployed Small Language Models (SLMs) must continually support diverse tasks under strict memory and computation constraints, making selective reliance on cloud Large Language Models (LLMs) unavoidable. Regulating cloud assistance during continual learning is challenging, as naive reward-based reinforcement learning often yields unstable offloading behavior and exacerbates catastrophic forgetting as task distributions shift. We propose DA-GRPO, a dual-advantage extension of Group Relative Policy Optimization that incorporates cloud-usage constraints directly into advantage computation, avoiding fixed reward shaping and external routing models. This design enables the local model to jointly learn task competence and collaboration behavior, allowing cloud requests to emerge naturally during post-training while respecting a prescribed assistance budget. Experiments on mathematical reasoning and code generation benchmarks show that DA-GRPO improves post-switch accuracy, substantially reduces forgetting, and maintains stable cloud usage compared to prior collaborative and routing-based approaches.
VisualActBench: Can VLMs See and Act like a Human?
Dec 10, 2025Vision-Language Models (VLMs) have achieved impressive progress in perceiving and describing visual environments. However, their ability to proactively reason and act based solely on visual inputs, without explicit textual prompts, remains underexplored. We introduce a new task, Visual Action Reasoning, and propose VisualActBench, a large-scale benchmark comprising 1,074 videos and 3,733 human-annotated actions across four real-world scenarios. Each action is labeled with an Action Prioritization Level (APL) and a proactive-reactive type to assess models' human-aligned reasoning and value sensitivity. We evaluate 29 VLMs on VisualActBench and find that while frontier models like GPT4o demonstrate relatively strong performance, a significant gap remains compared to human-level reasoning, particularly in generating proactive, high-priority actions. Our results highlight limitations in current VLMs' ability to interpret complex context, anticipate outcomes, and align with human decision-making frameworks. VisualActBench establishes a comprehensive foundation for assessing and improving the real-world readiness of proactive, vision-centric AI agents.
Parameter Tracking in Federated Learning with Adaptive Optimization
Feb 04, 2025



In Federated Learning (FL), model training performance is strongly impacted by data heterogeneity across clients. Gradient Tracking (GT) has recently emerged as a solution which mitigates this issue by introducing correction terms to local model updates. To date, GT has only been considered under Stochastic Gradient Descent (SGD)-based model training, while modern FL frameworks increasingly employ adaptive optimizers for improved convergence. In this work, we generalize the GT framework to a more flexible Parameter Tracking (PT) paradigm and propose two novel adaptive optimization algorithms, {\tt FAdamET} and {\tt FAdamGT}, that integrate PT into Adam-based FL. We provide a rigorous convergence analysis of these algorithms under non-convex settings. Our experimental results demonstrate that both proposed algorithms consistently outperform existing methods when evaluating total communication cost and total computation cost across varying levels of data heterogeneity, showing the effectiveness of correcting first-order information in federated adaptive optimization.
Deep Learning Aided Broadcast Codes with Feedback
Oct 22, 2024



Deep learning aided codes have been shown to improve code performance in feedback codes in high noise regimes due to the ability to leverage non-linearity in code design. In the additive white Gaussian broadcast channel (AWGN-BC), the addition of feedback may allow the capacity region to extend far beyond the capacity region of the channel without feedback, enabling higher data rates. On the other hand, there are limited deep-learning aided implementations of broadcast codes. In this work, we extend two classes of deep-learning assisted feedback codes to the AWGN-BC channel; the first being an RNN-based architecture and the second being a lightweight MLP-based architecture. Both codes are trained using a global model, and then they are trained using a more realistic vertical federated learning based framework. We first show that in most cases, using an AWGN-BC code outperforms a linear-based concatenated scheme. Second, we show in some regimes, the lightweight architecture far exceeds the RNN-based code, but in especially unreliable conditions, the RNN-based code dominates. The results show the promise of deep-learning aided broadcast codes in unreliable channels, and future research directions are discussed.
SePPO: Semi-Policy Preference Optimization for Diffusion Alignment
Oct 07, 2024



Reinforcement learning from human feedback (RLHF) methods are emerging as a way to fine-tune diffusion models (DMs) for visual generation. However, commonly used on-policy strategies are limited by the generalization capability of the reward model, while off-policy approaches require large amounts of difficult-to-obtain paired human-annotated data, particularly in visual generation tasks. To address the limitations of both on- and off-policy RLHF, we propose a preference optimization method that aligns DMs with preferences without relying on reward models or paired human-annotated data. Specifically, we introduce a Semi-Policy Preference Optimization (SePPO) method. SePPO leverages previous checkpoints as reference models while using them to generate on-policy reference samples, which replace "losing images" in preference pairs. This approach allows us to optimize using only off-policy "winning images." Furthermore, we design a strategy for reference model selection that expands the exploration in the policy space. Notably, we do not simply treat reference samples as negative examples for learning. Instead, we design an anchor-based criterion to assess whether the reference samples are likely to be winning or losing images, allowing the model to selectively learn from the generated reference samples. This approach mitigates performance degradation caused by the uncertainty in reference sample quality. We validate SePPO across both text-to-image and text-to-video benchmarks. SePPO surpasses all previous approaches on the text-to-image benchmarks and also demonstrates outstanding performance on the text-to-video benchmarks. Code will be released in https://github.com/DwanZhang-AI/SePPO.
Unlocking the Potential of Model Calibration in Federated Learning
Sep 07, 2024



Over the past several years, various federated learning (FL) methodologies have been developed to improve model accuracy, a primary performance metric in machine learning. However, to utilize FL in practical decision-making scenarios, beyond considering accuracy, the trained model must also have a reliable confidence in each of its predictions, an aspect that has been largely overlooked in existing FL research. Motivated by this gap, we propose Non-Uniform Calibration for Federated Learning (NUCFL), a generic framework that integrates FL with the concept of model calibration. The inherent data heterogeneity in FL environments makes model calibration particularly difficult, as it must ensure reliability across diverse data distributions and client conditions. Our NUCFL addresses this challenge by dynamically adjusting the model calibration objectives based on statistical relationships between each client's local model and the global model in FL. In particular, NUCFL assesses the similarity between local and global model relationships, and controls the penalty term for the calibration loss during client-side local training. By doing so, NUCFL effectively aligns calibration needs for the global model in heterogeneous FL settings while not sacrificing accuracy. Extensive experiments show that NUCFL offers flexibility and effectiveness across various FL algorithms, enhancing accuracy as well as model calibration.
Constant Modulus Waveform Design with Interference Exploitation for DFRC Systems: A Block-Level Optimization Approach
Jun 27, 2024



Dual-function radar-communication (DFRC) is a key enabler of location-based services for next-generation communication systems. In this paper, we investigate the problem of designing constant modulus waveforms for DFRC systems. For high-precision radar sensing, we consider joint optimization of the correlation properties and spatial beam pattern. For communication, we employ constructive interference-based block-level precoding (CI-BLP) to leverage distortion induced by multiuser multiple-input multiple-output (MU-MIMO) and radar transmission on a block level. We propose two solution algorithms based on the alternating direction method of multipliers (ADMM) and majorization-minimization (MM) principles, which are effective for small and large block sizes, respectively. The proposed ADMM-based solution decomposes the nonconvex formulated problem into multiple tractable subproblems, each of which admits a closed-form solution. To accelerate convergence of the MM-based solution, we propose an improved majorizing function that leverages a novel diagonal matrix structure. After majorization, we decompose the approximated problem into independent subproblems for parallelization, mitigating the complexity that increases with block size. We then evaluate the performance of the proposed algorithms through a series of numerical experiments. Simulation results demonstrate that the proposed methods can substantially enhance spatial/temporal sidelobe suppression through block-level optimization.
Differential Privacy in Hierarchical Federated Learning: A Formal Analysis and Evaluation
Jan 21, 2024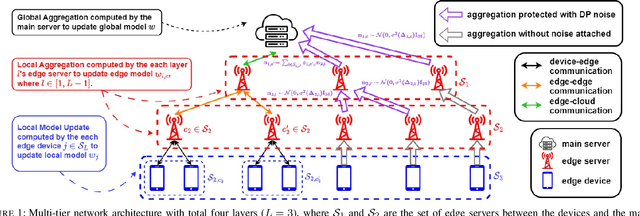
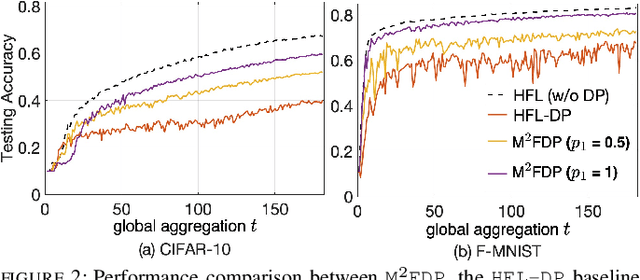
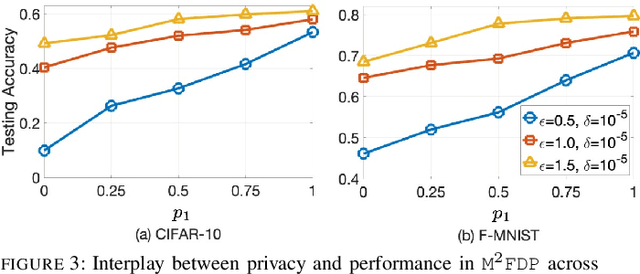
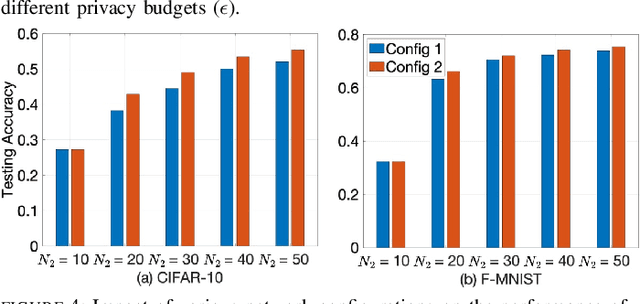
While federated learning (FL) eliminates the transmission of raw data over a network, it is still vulnerable to privacy breaches from the communicated model parameters. In this work, we formalize Differentially Private Hierarchical Federated Learning (DP-HFL), a DP-enhanced FL methodology that seeks to improve the privacy-utility tradeoff inherent in FL. Building upon recent proposals for Hierarchical Differential Privacy (HDP), one of the key concepts of DP-HFL is adapting DP noise injection at different layers of an established FL hierarchy -- edge devices, edge servers, and cloud servers -- according to the trust models within particular subnetworks. We conduct a comprehensive analysis of the convergence behavior of DP-HFL, revealing conditions on parameter tuning under which the model training process converges sublinearly to a stationarity gap, with this gap depending on the network hierarchy, trust model, and target privacy level. Subsequent numerical evaluations demonstrate that DP-HFL obtains substantial improvements in convergence speed over baselines for different privacy budgets, and validate the impact of network configuration on training.
Exploring the Efficacy of ChatGPT in Analyzing Student Teamwork Feedback with an Existing Taxonomy
May 09, 2023



Teamwork is a critical component of many academic and professional settings. In those contexts, feedback between team members is an important element to facilitate successful and sustainable teamwork. However, in the classroom, as the number of teams and team members and frequency of evaluation increase, the volume of comments can become overwhelming for an instructor to read and track, making it difficult to identify patterns and areas for student improvement. To address this challenge, we explored the use of generative AI models, specifically ChatGPT, to analyze student comments in team based learning contexts. Our study aimed to evaluate ChatGPT's ability to accurately identify topics in student comments based on an existing framework consisting of positive and negative comments. Our results suggest that ChatGPT can achieve over 90\% accuracy in labeling student comments, providing a potentially valuable tool for analyzing feedback in team projects. This study contributes to the growing body of research on the use of AI models in educational contexts and highlights the potential of ChatGPT for facilitating analysis of student comments.