 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Reinforcement Learning for Honesty Alignment in Language Models on Deductive Reasoning
Nov 12, 2025Reinforcement learning with verifiable rewards (RLVR) has recently emerged as a promising framework for aligning language models with complex reasoning objectives. However, most existing methods optimize only for final task outcomes, leaving models vulnerable to collapse when negative rewards dominate early training. This challenge is especially pronounced in honesty alignment, where models must not only solve answerable queries but also identify when conclusions cannot be drawn from the given premises. Deductive reasoning provides an ideal testbed because it isolates reasoning capability from reliance on external factual knowledge. To investigate honesty alignment, we curate two multi-step deductive reasoning datasets from graph structures, one for linear algebra and one for logical inference, and introduce unanswerable cases by randomly perturbing an edge in half of the instances. We find that GRPO, with or without supervised fine tuning initialization, struggles on these tasks. Through extensive experiments across three models, we evaluate stabilization strategies and show that curriculum learning provides some benefit but requires carefully designed in distribution datasets with controllable difficulty. To address these limitations, we propose Anchor, a reinforcement learning method that injects ground truth trajectories into rollouts, preventing early training collapse. Our results demonstrate that this method stabilizes learning and significantly improves the overall reasoning performance, underscoring the importance of training dynamics for enabling reliable deductive reasoning in aligned language models.
PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time
Jun 06, 2025Large Language Model (LLM) empowered agents have recently emerged as advanced paradigms that exhibit impressive capabilities in a wide range of domains and tasks. Despite their potential, current LLM agents often adopt a one-size-fits-all approach, lacking the flexibility to respond to users' varying needs and preferences. This limitation motivates us to develop PersonaAgent, the first personalized LLM agent framework designed to address versatile personalization tasks. Specifically, PersonaAgent integrates two complementary components - a personalized memory module that includes episodic and semantic memory mechanisms; a personalized action module that enables the agent to perform tool actions tailored to the user. At the core, the persona (defined as unique system prompt for each user) functions as an intermediary: it leverages insights from personalized memory to control agent actions, while the outcomes of these actions in turn refine the memory. Based on the framework, we propose a test-time user-preference alignment strategy that simulate the latest n interactions to optimize the persona prompt, ensuring real-time user preference alignment through textual loss feedback between simulated and ground-truth responses. Experimental evaluations demonstrate that PersonaAgent significantly outperforms other baseline methods by not only personalizing the action space effectively but also scaling during test-time real-world applications. These results underscore the feasibility and potential of our approach in delivering tailored, dynamic user experiences.
SePPO: Semi-Policy Preference Optimization for Diffusion Alignment
Oct 07, 2024



Reinforcement learning from human feedback (RLHF) methods are emerging as a way to fine-tune diffusion models (DMs) for visual generation. However, commonly used on-policy strategies are limited by the generalization capability of the reward model, while off-policy approaches require large amounts of difficult-to-obtain paired human-annotated data, particularly in visual generation tasks. To address the limitations of both on- and off-policy RLHF, we propose a preference optimization method that aligns DMs with preferences without relying on reward models or paired human-annotated data. Specifically, we introduce a Semi-Policy Preference Optimization (SePPO) method. SePPO leverages previous checkpoints as reference models while using them to generate on-policy reference samples, which replace "losing images" in preference pairs. This approach allows us to optimize using only off-policy "winning images." Furthermore, we design a strategy for reference model selection that expands the exploration in the policy space. Notably, we do not simply treat reference samples as negative examples for learning. Instead, we design an anchor-based criterion to assess whether the reference samples are likely to be winning or losing images, allowing the model to selectively learn from the generated reference samples. This approach mitigates performance degradation caused by the uncertainty in reference sample quality. We validate SePPO across both text-to-image and text-to-video benchmarks. SePPO surpasses all previous approaches on the text-to-image benchmarks and also demonstrates outstanding performance on the text-to-video benchmarks. Code will be released in https://github.com/DwanZhang-AI/SePPO.
DivScene: Benchmarking LVLMs for Object Navigation with Diverse Scenes and Objects
Oct 03, 2024

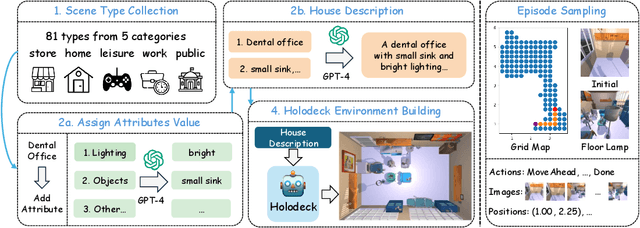

Object navigation in unknown environments is crucial for deploying embodied agents in real-world applications. While we have witnessed huge progress due to large-scale scene datasets, faster simulators, and stronger models, previous studies mainly focus on limited scene types and target objects. In this paper, we study a new task of navigating to diverse target objects in a large number of scene types. To benchmark the problem, we present a large-scale scene dataset, DivScene, which contains 4,614 scenes across 81 different types. With the dataset, we build an end-to-end embodied agent, NatVLM, by fine-tuning a Large Vision Language Model (LVLM) through imitation learning. The LVLM is trained to take previous observations from the environment and generate the next actions. We also introduce CoT explanation traces of the action prediction for better performance when tuning LVLMs. Our extensive experiments find that we can build a performant LVLM-based agent through imitation learning on the shortest paths constructed by a BFS planner without any human supervision. Our agent achieves a success rate that surpasses GPT-4o by over 20%. Meanwhile, we carry out various analyses showing the generalization ability of our agent.
Cognitive Kernel: An Open-source Agent System towards Generalist Autopilots
Sep 16, 2024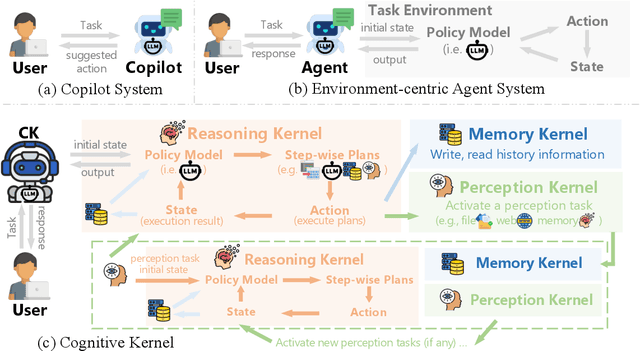



We introduce Cognitive Kernel, an open-source agent system towards the goal of generalist autopilots. Unlike copilot systems, which primarily rely on users to provide essential state information (e.g., task descriptions) and assist users by answering questions or auto-completing contents, autopilot systems must complete tasks from start to finish independently, which requires the system to acquire the state information from the environments actively. To achieve this, an autopilot system should be capable of understanding user intents, actively gathering necessary information from various real-world sources, and making wise decisions. Cognitive Kernel adopts a model-centric design. In our implementation, the central policy model (a fine-tuned LLM) initiates interactions with the environment using a combination of atomic actions, such as opening files, clicking buttons, saving intermediate results to memory, or calling the LLM itself. This differs from the widely used environment-centric design, where a task-specific environment with predefined actions is fixed, and the policy model is limited to selecting the correct action from a given set of options. Our design facilitates seamless information flow across various sources and provides greater flexibility. We evaluate our system in three use cases: real-time information management, private information management, and long-term memory management. The results demonstrate that Cognitive Kernel achieves better or comparable performance to other closed-source systems in these scenarios. Cognitive Kernel is fully dockerized, ensuring everyone can deploy it privately and securely. We open-source the system and the backbone model to encourage further research on LLM-driven autopilot systems.
Abstraction-of-Thought Makes Language Models Better Reasoners
Jun 18, 2024
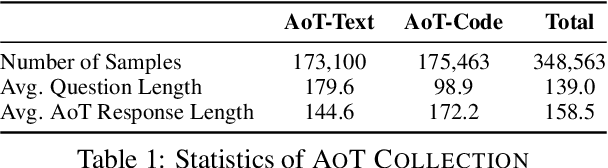

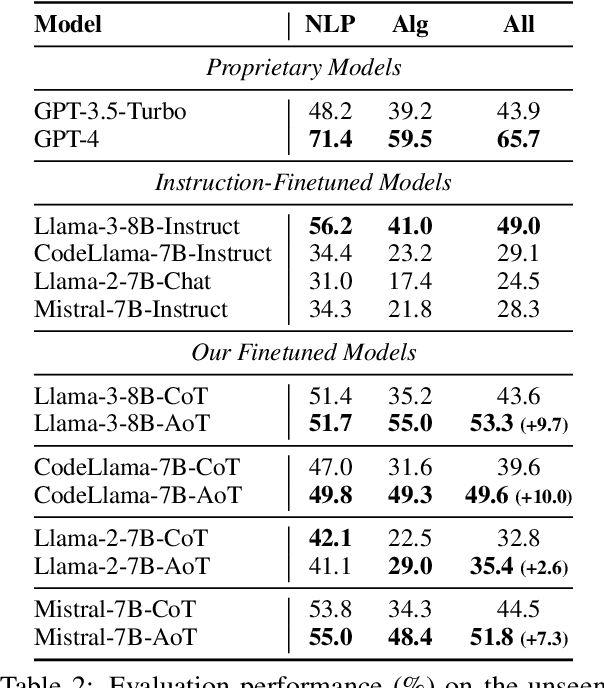
Abstract reasoning, the ability to reason from the abstract essence of a problem, serves as a key to generalization in human reasoning. However, eliciting language models to perform reasoning with abstraction remains unexplored. This paper seeks to bridge this gap by introducing a novel structured reasoning format called Abstraction-of-Thought (AoT). The uniqueness of AoT lies in its explicit requirement for varying levels of abstraction within the reasoning process. This approach could elicit language models to first contemplate on the abstract level before incorporating concrete details, which is overlooked by the prevailing step-by-step Chain-of-Thought (CoT) method. To align models with the AoT format, we present AoT Collection, a generic finetuning dataset consisting of 348k high-quality samples with AoT reasoning processes, collected via an automated and scalable pipeline. We finetune a wide range of language models with AoT Collection and conduct extensive evaluations on 23 unseen tasks from the challenging benchmark Big-Bench Hard. Experimental results indicate that models aligned to AoT reasoning format substantially outperform those aligned to CoT in many reasoning tasks.
Fact-and-Reflection (FaR) Improves Confidence Calibration of Large Language Models
Feb 27, 2024For a LLM to be trustworthy, its confidence level should be well-calibrated with its actual performance. While it is now common sense that LLM performances are greatly impacted by prompts, the confidence calibration in prompting LLMs has yet to be thoroughly explored. In this paper, we explore how different prompting strategies influence LLM confidence calibration and how it could be improved. We conduct extensive experiments on six prompting methods in the question-answering context and we observe that, while these methods help improve the expected LLM calibration, they also trigger LLMs to be over-confident when responding to some instances. Inspired by human cognition, we propose Fact-and-Reflection (FaR) prompting, which improves the LLM calibration in two steps. First, FaR elicits the known "facts" that are relevant to the input prompt from the LLM. And then it asks the model to "reflect" over them to generate the final answer. Experiments show that FaR prompting achieves significantly better calibration; it lowers the Expected Calibration Error by 23.5% on our multi-purpose QA tasks. Notably, FaR prompting even elicits the capability of verbally expressing concerns in less confident scenarios, which helps trigger retrieval augmentation for solving these harder instances.
Rewards-in-Context: Multi-objective Alignment of Foundation Models with Dynamic Preference Adjustment
Feb 25, 2024We consider the problem of multi-objective alignment of foundation models with human preferences, which is a critical step towards helpful and harmless AI systems. However, it is generally costly and unstable to fine-tune large foundation models using reinforcement learning (RL), and the multi-dimensionality, heterogeneity, and conflicting nature of human preferences further complicate the alignment process. In this paper, we introduce Rewards-in-Context (RiC), which conditions the response of a foundation model on multiple rewards in its prompt context and applies supervised fine-tuning for alignment. The salient features of RiC are simplicity and adaptivity, as it only requires supervised fine-tuning of a single foundation model and supports dynamic adjustment for user preferences during inference time. Inspired by the analytical solution of an abstracted convex optimization problem, our dynamic inference-time adjustment method approaches the Pareto-optimal solution for multiple objectives. Empirical evidence demonstrates the efficacy of our method in aligning both Large Language Models (LLMs) and diffusion models to accommodate diverse rewards with only around 10% GPU hours compared with multi-objective RL baseline.
Zebra: Extending Context Window with Layerwise Grouped Local-Global Attention
Dec 14, 2023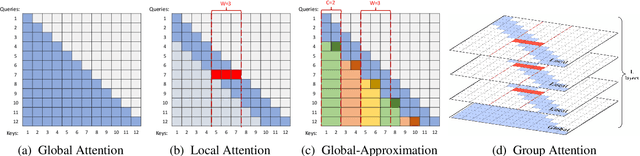


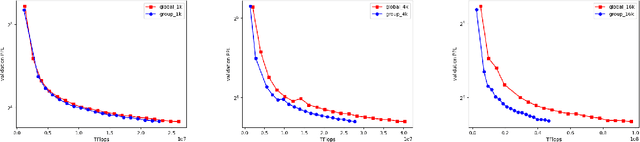
This paper introduces a novel approach to enhance the capabilities of Large Language Models (LLMs) in processing and understanding extensive text sequences, a critical aspect in applications requiring deep comprehension and synthesis of large volumes of information. Recognizing the inherent challenges in extending the context window for LLMs, primarily built on Transformer architecture, we propose a new model architecture, referred to as Zebra. This architecture efficiently manages the quadratic time and memory complexity issues associated with full attention in the Transformer by employing grouped local-global attention layers. Our model, akin to a zebra's alternating stripes, balances local and global attention layers, significantly reducing computational requirements and memory consumption. Comprehensive experiments, including pretraining from scratch, continuation of long context adaptation training, and long instruction tuning, are conducted to evaluate the Zebra's performance. The results show that Zebra achieves comparable or superior performance on both short and long sequence benchmarks, while also enhancing training and inference efficiency.
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
Nov 15, 2023



Retrieval-augmented language models (RALMs) represent a substantial advancement in the capabilities of large language models, notably in reducing factual hallucination by leveraging external knowledge sources. However, the reliability of the retrieved information is not always guaranteed. The retrieval of irrelevant data can lead to misguided responses, and potentially causing the model to overlook its inherent knowledge, even when it possesses adequate information to address the query. Moreover, standard RALMs often struggle to assess whether they possess adequate knowledge, both intrinsic and retrieved, to provide an accurate answer. In situations where knowledge is lacking, these systems should ideally respond with "unknown" when the answer is unattainable. In response to these challenges, we introduces Chain-of-Noting (CoN), a novel approach aimed at improving the robustness of RALMs in facing noisy, irrelevant documents and in handling unknown scenarios. The core idea of CoN is to generate sequential reading notes for retrieved documents, enabling a thorough evaluation of their relevance to the given question and integrating this information to formulate the final answer. We employed ChatGPT to create training data for CoN, which was subsequently trained on an LLaMa-2 7B model. Our experiments across four open-domain QA benchmarks show that RALMs equipped with CoN significantly outperform standard RALMs. Notably, CoN achieves an average improvement of +7.9 in EM score given entirely noisy retrieved documents and +10.5 in rejection rates for real-time questions that fall outside the pre-training knowledge scope.