 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoWeaver: Evaluating and Evolving Skills for Agentic Long Video Generation
Jun 06, 2026Recent agent frameworks such as Claude Code, Codex, and OpenClaw are strong at tool use and orchestration, but whether they can handle long video generation, a long-horizon multimodal task, remains underexplored. Unlike earlier video agents whose pipeline is handcrafted, these frameworks can build and refine their own workflows. We introduce VideoWeaver, an agent harness and benchmark that evaluates and evolves skills for long video generation, where an agent turns a single instruction into a long video by composing foundation skills into its own workflow rather than following a predefined pipeline. The benchmark has 16 task categories and 285 cases, with references spanning text, image, audio, video, and their combinations. Because errors can arise at any stage and not just in the final video, we propose an agent-as-judge that inspects both the execution trace and the final video, grounding its scores in evidence such as metadata and intermediate files. Using this feedback, we further design a skill evolution algorithm that refines and merges the agent's skills. Across multiple frameworks and models, we find that an explicit composition skill improves the generation process over using foundation skills alone, that skill evolution further improves output quality, and that performance varies notably across harness and model choices. The proposed agent-as-judge also aligns well with human judgments, especially on process metrics. Code and dataset is available at https://github.com/JianhuiWei7/VideoWeaver
How Far Are Video Models from True Multimodal Reasoning?
Apr 21, 2026Despite remarkable progress toward general-purpose video models, a critical question remains unanswered: how far are these models from achieving true multimodal reasoning? Existing benchmarks fail to address this question rigorously, as they remain constrained by straightforward task designs and fragmented evaluation metrics that neglect complex multimodal reasoning. To bridge this gap, we introduce CLVG-Bench, an evaluation framework designed to probe video models' zero-shot reasoning capabilities via Context Learning in Video Generation. CLVG-Bench comprises more than 1,000 high-quality, manually annotated metadata across 6 categories and 47 subcategories, covering complex scenarios including physical simulation, logical reasoning, and interactive contexts. To enable rigorous and scalable assessment, we further propose an Adaptive Video Evaluator (AVE) that aligns with human expert perception using minimal annotations, delivering interpretable textual feedback across diverse video context tasks. Extensive experiments reveal a striking answer to our central question: while state-of-the-art (SOTA) video models, such as Seedance 2.0, demonstrate competence on certain understanding and reasoning subtasks, they fall substantially short with logically grounded and interactive generation tasks (achieving success rates <25% and ~0%, respectively), exposing multimodal reasoning and physical grounding as critical bottlenecks. By systematically quantifying these limitations, the proposed method provides actionable feedbacks and a clear roadmap toward truly robust, general-purpose video models. CLVG-Bench and code are released here.
A Versatile Multimodal Agent for Multimedia Content Generation
Jan 06, 2026With the advancement of AIGC (AI-generated content) technologies, an increasing number of generative models are revolutionizing fields such as video editing, music generation, and even film production. However, due to the limitations of current AIGC models, most models can only serve as individual components within specific application scenarios and are not capable of completing tasks end-to-end in real-world applications. In real-world applications, editing experts often work with a wide variety of images and video inputs, producing multimodal outputs -- a video typically includes audio, text, and other elements. This level of integration across multiple modalities is something current models are unable to achieve effectively. However, the rise of agent-based systems has made it possible to use AI tools to tackle complex content generation tasks. To deal with the complex scenarios, in this paper, we propose a MultiMedia-Agent designed to automate complex content creation. Our agent system includes a data generation pipeline, a tool library for content creation, and a set of metrics for evaluating preference alignment. Notably, we introduce the skill acquisition theory to model the training data curation and agent training. We designed a two-stage correlation strategy for plan optimization, including self-correlation and model preference correlation. Additionally, we utilized the generated plans to train the MultiMedia-Agent via a three stage approach including base/success plan finetune and preference optimization. The comparison results demonstrate that the our approaches are effective and the MultiMedia-Agent can generate better multimedia content compared to novel models.
Sphinx: Benchmarking and Modeling for LLM-Driven Pull Request Review
Jan 06, 2026Pull request (PR) review is essential for ensuring software quality, yet automating this task remains challenging due to noisy supervision, limited contextual understanding, and inadequate evaluation metrics. We present Sphinx, a unified framework for LLM-based PR review that addresses these limitations through three key components: (1) a structured data generation pipeline that produces context-rich, semantically grounded review comments by comparing pseudo-modified and merged code; (2) a checklist-based evaluation benchmark that assesses review quality based on structured coverage of actionable verification points, moving beyond surface-level metrics like BLEU; and (3) Checklist Reward Policy Optimization (CRPO), a novel training paradigm that uses rule-based, interpretable rewards to align model behavior with real-world review practices. Extensive experiments show that models trained with Sphinx achieve state-of-the-art performance on review completeness and precision, outperforming both proprietary and open-source baselines by up to 40\% in checklist coverage. Together, Sphinx enables the development of PR review models that are not only fluent but also context-aware, technically precise, and practically deployable in real-world development workflows. The data will be released after review.
JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation
Dec 28, 2025This paper presents JavisGPT, the first unified multimodal large language model (MLLM) for Joint Audio-Video (JAV) comprehension and generation. JavisGPT adopts a concise encoder-LLM-decoder architecture, featuring a SyncFusion module for spatio-temporal audio-video fusion and synchrony-aware learnable queries to bridge a pretrained JAV-DiT generator. This design enables temporally coherent video-audio understanding and generation from multimodal instructions. We design an effective three-stage training pipeline consisting of multimodal pretraining, audio-video fine-tuning, and large-scale instruction-tuning, to progressively build multimodal comprehension and generation from existing vision-language models. To support this, we further construct JavisInst-Omni, a high-quality instruction dataset with over 200K GPT-4o-curated audio-video-text dialogues that span diverse and multi-level comprehension and generation scenarios. Extensive experiments on JAV comprehension and generation benchmarks show that JavisGPT outperforms existing MLLMs, particularly in complex and temporally synchronized settings.
VisualActBench: Can VLMs See and Act like a Human?
Dec 10, 2025Vision-Language Models (VLMs) have achieved impressive progress in perceiving and describing visual environments. However, their ability to proactively reason and act based solely on visual inputs, without explicit textual prompts, remains underexplored. We introduce a new task, Visual Action Reasoning, and propose VisualActBench, a large-scale benchmark comprising 1,074 videos and 3,733 human-annotated actions across four real-world scenarios. Each action is labeled with an Action Prioritization Level (APL) and a proactive-reactive type to assess models' human-aligned reasoning and value sensitivity. We evaluate 29 VLMs on VisualActBench and find that while frontier models like GPT4o demonstrate relatively strong performance, a significant gap remains compared to human-level reasoning, particularly in generating proactive, high-priority actions. Our results highlight limitations in current VLMs' ability to interpret complex context, anticipate outcomes, and align with human decision-making frameworks. VisualActBench establishes a comprehensive foundation for assessing and improving the real-world readiness of proactive, vision-centric AI agents.
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
Nov 11, 2025While specialized AI models excel at isolated video tasks like generation or understanding, real-world applications demand complex, iterative workflows that combine these capabilities. To bridge this gap, we introduce UniVA, an open-source, omni-capable multi-agent framework for next-generation video generalists that unifies video understanding, segmentation, editing, and generation into cohesive workflows. UniVA employs a Plan-and-Act dual-agent architecture that drives a highly automated and proactive workflow: a planner agent interprets user intentions and decomposes them into structured video-processing steps, while executor agents execute these through modular, MCP-based tool servers (for analysis, generation, editing, tracking, etc.). Through a hierarchical multi-level memory (global knowledge, task context, and user-specific preferences), UniVA sustains long-horizon reasoning, contextual continuity, and inter-agent communication, enabling interactive and self-reflective video creation with full traceability. This design enables iterative and any-conditioned video workflows (e.g., text/image/video-conditioned generation $\rightarrow$ multi-round editing $\rightarrow$ object segmentation $\rightarrow$ compositional synthesis) that were previously cumbersome to achieve with single-purpose models or monolithic video-language models. We also introduce UniVA-Bench, a benchmark suite of multi-step video tasks spanning understanding, editing, segmentation, and generation, to rigorously evaluate such agentic video systems. Both UniVA and UniVA-Bench are fully open-sourced, aiming to catalyze research on interactive, agentic, and general-purpose video intelligence for the next generation of multimodal AI systems. (https://univa.online/)
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
WorldGenBench: A World-Knowledge-Integrated Benchmark for Reasoning-Driven Text-to-Image Generation
May 02, 2025Recent advances in text-to-image (T2I) generation have achieved impressive results, yet existing models still struggle with prompts that require rich world knowledge and implicit reasoning: both of which are critical for producing semantically accurate, coherent, and contextually appropriate images in real-world scenarios. To address this gap, we introduce \textbf{WorldGenBench}, a benchmark designed to systematically evaluate T2I models' world knowledge grounding and implicit inferential capabilities, covering both the humanities and nature domains. We propose the \textbf{Knowledge Checklist Score}, a structured metric that measures how well generated images satisfy key semantic expectations. Experiments across 21 state-of-the-art models reveal that while diffusion models lead among open-source methods, proprietary auto-regressive models like GPT-4o exhibit significantly stronger reasoning and knowledge integration. Our findings highlight the need for deeper understanding and inference capabilities in next-generation T2I systems. Project Page: \href{https://dwanzhang-ai.github.io/WorldGenBench/}{https://dwanzhang-ai.github.io/WorldGenBench/}
Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning (v1)
Apr 04, 2025
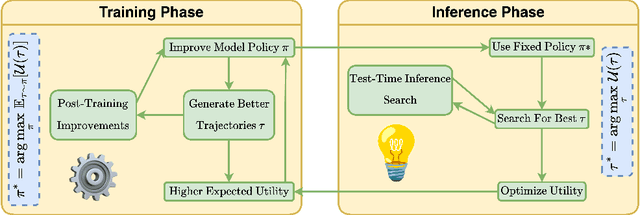
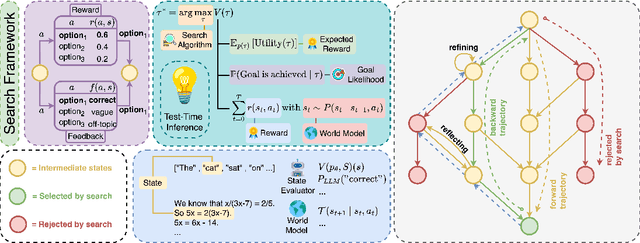
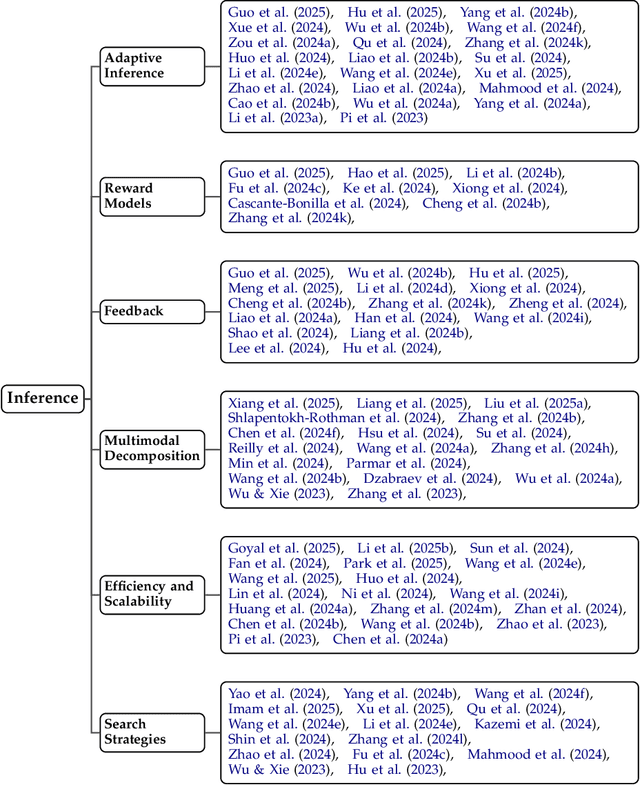
Reasoning is central to human intelligence, enabling structured problem-solving across diverse tasks. Recent advances in large language models (LLMs) have greatly enhanced their reasoning abilities in arithmetic, commonsense, and symbolic domains. However, effectively extending these capabilities into multimodal contexts-where models must integrate both visual and textual inputs-continues to be a significant challenge. Multimodal reasoning introduces complexities, such as handling conflicting information across modalities, which require models to adopt advanced interpretative strategies. Addressing these challenges involves not only sophisticated algorithms but also robust methodologies for evaluating reasoning accuracy and coherence. This paper offers a concise yet insightful overview of reasoning techniques in both textual and multimodal LLMs. Through a thorough and up-to-date comparison, we clearly formulate core reasoning challenges and opportunities, highlighting practical methods for post-training optimization and test-time inference. Our work provides valuable insights and guidance, bridging theoretical frameworks and practical implementations, and sets clear directions for future research.