 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Last Human-Written Paper: Agent-Native Research Artifacts
Apr 27, 2026Scientific publication compresses a branching, iterative research process into a linear narrative, discarding the majority of what was discovered along the way. This compilation imposes two structural costs: a Storytelling Tax, where failed experiments, rejected hypotheses, and the branching exploration process are discarded to fit a linear narrative; and an Engineering Tax, where the gap between reviewer-sufficient prose and agent-sufficient specification leaves critical implementation details unwritten. Tolerable for human readers, these costs become critical when AI agents must understand, reproduce, and extend published work. We introduce the Agent-Native Research Artifact (Ara), a protocol that replaces the narrative paper with a machine-executable research package structured around four layers: scientific logic, executable code with full specifications, an exploration graph that preserves the failures compilation discards, and evidence grounding every claim in raw outputs. Three mechanisms support the ecosystem: a Live Research Manager that captures decisions and dead ends during ordinary development; an Ara Compiler that translates legacy PDFs and repos into Aras; and an Ara-native review system that automates objective checks so human reviewers can focus on significance, novelty, and taste. On PaperBench and RE-Bench, Ara raises question-answering accuracy from 72.4% to 93.7% and reproduction success from 57.4% to 64.4%. On RE-Bench's five open-ended extension tasks, preserved failure traces in Ara accelerate progress, but can also constrain a capable agent from stepping outside the prior-run box depending on the agent's capabilities.
ORACLE-SWE: Quantifying the Contribution of Oracle Information Signals on SWE Agents
Apr 09, 2026Recent advances in language model (LM) agents have significantly improved automated software engineering (SWE). Prior work has proposed various agentic workflows and training strategies as well as analyzed failure modes of agentic systems on SWE tasks, focusing on several contextual information signals: Reproduction Test, Regression Test, Edit Location, Execution Context, and API Usage. However, the individual contribution of each signal to overall success remains underexplored, particularly their ideal contribution when intermediate information is perfectly obtained. To address this gap, we introduce Oracle-SWE, a unified method to isolate and extract oracle information signals from SWE benchmarks and quantify the impact of each signal on agent performance. To further validate the pattern, we evaluate the performance gain of signals extracted by strong LMs when provided to a base agent, approximating real-world task-resolution settings. These evaluations aim to guide research prioritization for autonomous coding systems.
RepoLaunch: Automating Build&Test Pipeline of Code Repositories on ANY Language and ANY Platform
Mar 05, 2026Building software repositories typically requires significant manual effort. Recent advances in large language model (LLM) agents have accelerated automation in software engineering (SWE). We introduce RepoLaunch, the first agent capable of automatically resolving dependencies, compiling source code, and extracting test results for repositories across arbitrary programming languages and operating systems. To demonstrate its utility, we further propose a fully automated pipeline for SWE dataset creation, where task design is the only human intervention. RepoLaunch automates the remaining steps, enabling scalable benchmarking and training of coding agents and LLMs. Notably, several works on agentic benchmarking and training have recently adopted RepoLaunch for automated task generation.
Sphinx: Benchmarking and Modeling for LLM-Driven Pull Request Review
Jan 06, 2026Pull request (PR) review is essential for ensuring software quality, yet automating this task remains challenging due to noisy supervision, limited contextual understanding, and inadequate evaluation metrics. We present Sphinx, a unified framework for LLM-based PR review that addresses these limitations through three key components: (1) a structured data generation pipeline that produces context-rich, semantically grounded review comments by comparing pseudo-modified and merged code; (2) a checklist-based evaluation benchmark that assesses review quality based on structured coverage of actionable verification points, moving beyond surface-level metrics like BLEU; and (3) Checklist Reward Policy Optimization (CRPO), a novel training paradigm that uses rule-based, interpretable rewards to align model behavior with real-world review practices. Extensive experiments show that models trained with Sphinx achieve state-of-the-art performance on review completeness and precision, outperforming both proprietary and open-source baselines by up to 40\% in checklist coverage. Together, Sphinx enables the development of PR review models that are not only fluent but also context-aware, technically precise, and practically deployable in real-world development workflows. The data will be released after review.
WorldGenBench: A World-Knowledge-Integrated Benchmark for Reasoning-Driven Text-to-Image Generation
May 02, 2025Recent advances in text-to-image (T2I) generation have achieved impressive results, yet existing models still struggle with prompts that require rich world knowledge and implicit reasoning: both of which are critical for producing semantically accurate, coherent, and contextually appropriate images in real-world scenarios. To address this gap, we introduce \textbf{WorldGenBench}, a benchmark designed to systematically evaluate T2I models' world knowledge grounding and implicit inferential capabilities, covering both the humanities and nature domains. We propose the \textbf{Knowledge Checklist Score}, a structured metric that measures how well generated images satisfy key semantic expectations. Experiments across 21 state-of-the-art models reveal that while diffusion models lead among open-source methods, proprietary auto-regressive models like GPT-4o exhibit significantly stronger reasoning and knowledge integration. Our findings highlight the need for deeper understanding and inference capabilities in next-generation T2I systems. Project Page: \href{https://dwanzhang-ai.github.io/WorldGenBench/}{https://dwanzhang-ai.github.io/WorldGenBench/}
CoCoT: Contrastive Chain-of-Thought Prompting for Large Multimodal Models with Multiple Image Inputs
Jan 05, 2024When exploring the development of Artificial General Intelligence (AGI), a critical task for these models involves interpreting and processing information from multiple image inputs. However, Large Multimodal Models (LMMs) encounter two issues in such scenarios: (1) a lack of fine-grained perception, and (2) a tendency to blend information across multiple images. We first extensively investigate the capability of LMMs to perceive fine-grained visual details when dealing with multiple input images. The research focuses on two aspects: first, image-to-image matching (to evaluate whether LMMs can effectively reason and pair relevant images), and second, multi-image-to-text matching (to assess whether LMMs can accurately capture and summarize detailed image information). We conduct evaluations on a range of both open-source and closed-source large models, including GPT-4V, Gemini, OpenFlamingo, and MMICL. To enhance model performance, we further develop a Contrastive Chain-of-Thought (CoCoT) prompting approach based on multi-input multimodal models. This method requires LMMs to compare the similarities and differences among multiple image inputs, and then guide the models to answer detailed questions about multi-image inputs based on the identified similarities and differences. Our experimental results showcase CoCoT's proficiency in enhancing the multi-image comprehension capabilities of large multimodal models.
An In-depth Survey of Large Language Model-based Artificial Intelligence Agents
Sep 23, 2023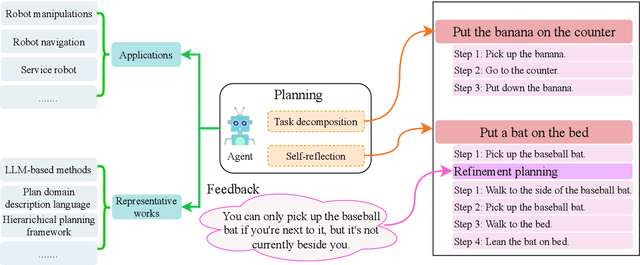
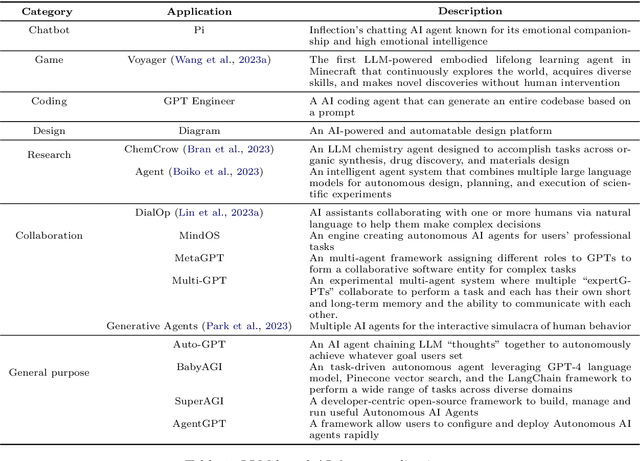
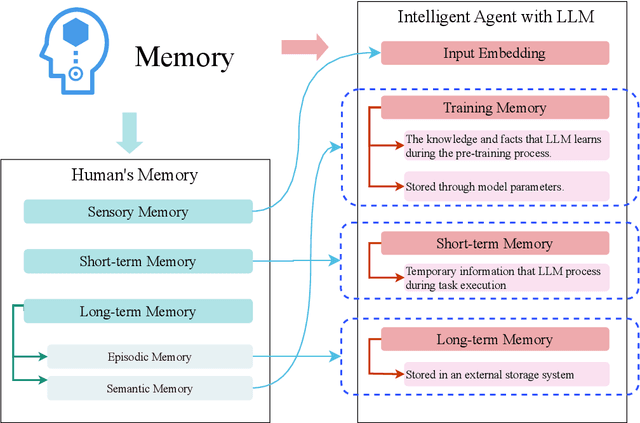
Due to the powerful capabilities demonstrated by large language model (LLM), there has been a recent surge in efforts to integrate them with AI agents to enhance their performance. In this paper, we have explored the core differences and characteristics between LLM-based AI agents and traditional AI agents. Specifically, we first compare the fundamental characteristics of these two types of agents, clarifying the significant advantages of LLM-based agents in handling natural language, knowledge storage, and reasoning capabilities. Subsequently, we conducted an in-depth analysis of the key components of AI agents, including planning, memory, and tool use. Particularly, for the crucial component of memory, this paper introduced an innovative classification scheme, not only departing from traditional classification methods but also providing a fresh perspective on the design of an AI agent's memory system. We firmly believe that in-depth research and understanding of these core components will lay a solid foundation for the future advancement of AI agent technology. At the end of the paper, we provide directional suggestions for further research in this field, with the hope of offering valuable insights to scholars and researchers in the field.
Logographic Information Aids Learning Better Representations for Natural Language Inference
Nov 03, 2022
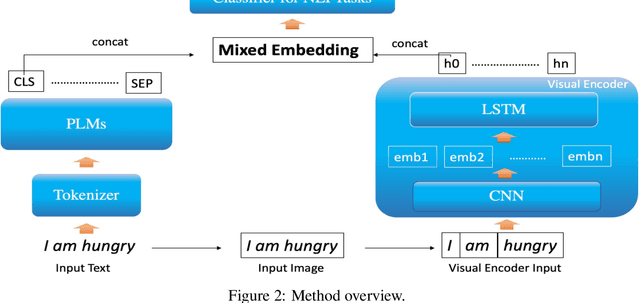
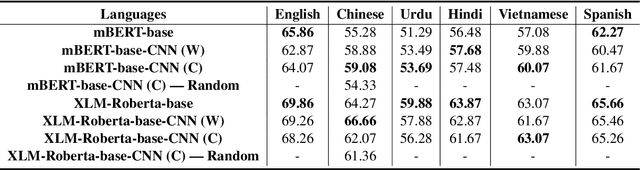
Statistical language models conventionally implement representation learning based on the contextual distribution of words or other formal units, whereas any information related to the logographic features of written text are often ignored, assuming they should be retrieved relying on the cooccurence statistics. On the other hand, as language models become larger and require more data to learn reliable representations, such assumptions may start to fall back, especially under conditions of data sparsity. Many languages, including Chinese and Vietnamese, use logographic writing systems where surface forms are represented as a visual organization of smaller graphemic units, which often contain many semantic cues. In this paper, we present a novel study which explores the benefits of providing language models with logographic information in learning better semantic representations. We test our hypothesis in the natural language inference (NLI) task by evaluating the benefit of computing multi-modal representations that combine contextual information with glyph information. Our evaluation results in six languages with different typology and writing systems suggest significant benefits of using multi-modal embeddings in languages with logograhic systems, especially for words with less occurence statistics.
Probing Script Knowledge from Pre-Trained Models
Apr 16, 2022
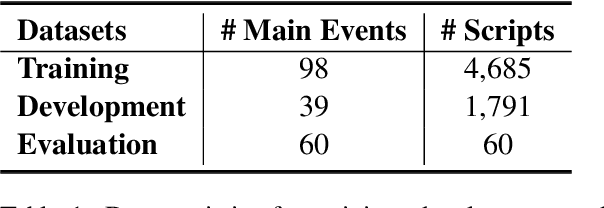
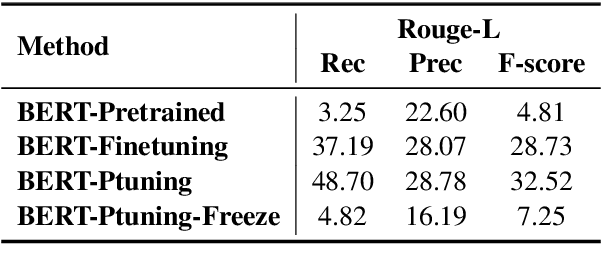
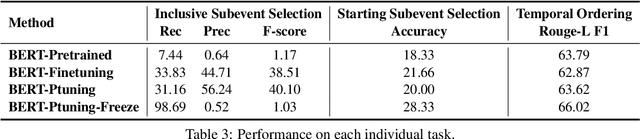
Script knowledge is critical for humans to understand the broad daily tasks and routine activities in the world. Recently researchers have explored the large-scale pre-trained language models (PLMs) to perform various script related tasks, such as story generation, temporal ordering of event, future event prediction and so on. However, it's still not well studied in terms of how well the PLMs capture the script knowledge. To answer this question, we design three probing tasks: inclusive sub-event selection, starting sub-event selection and temporal ordering to investigate the capabilities of PLMs with and without fine-tuning. The three probing tasks can be further used to automatically induce a script for each main event given all the possible sub-events. Taking BERT as a case study, by analyzing its performance on script induction as well as each individual probing task, we conclude that the stereotypical temporal knowledge among the sub-events is well captured in BERT, however the inclusive or starting sub-event knowledge is barely encoded.