 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
DIVE: Scaling Diversity in Agentic Task Synthesis for Generalizable Tool Use
Mar 10, 2026Recent work synthesizes agentic tasks for post-training tool-using LLMs, yet robust generalization under shifts in tasks and toolsets remains an open challenge. We trace this brittleness to insufficient diversity in synthesized tasks. Scaling diversity is difficult because training requires tasks to remain executable and verifiable, while generalization demands coverage of diverse tool types, toolset combinations, and heterogeneous tool-use patterns. We propose DIVE, an evidence-driven recipe that inverts synthesis order, executing diverse, real-world tools first and reverse-deriving tasks strictly entailed by the resulting traces, thereby providing grounding by construction. DIVE scales structural diversity along two controllable axes, tool-pool coverage and per-task toolset variety, and an Evidence Collection--Task Derivation loop further induces rich multi-step tool-use patterns across 373 tools in five domains. Training Qwen3-8B on DIVE data (48k SFT + 3.2k RL) improves by +22 average points across 9 OOD benchmarks and outperforms the strongest 8B baseline by +68. Remarkably, controlled scaling analysis reveals that diversity scaling consistently outperforms quantity scaling for OOD generalization, even with 4x less data.
HER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
Jan 29, 2026LLM role-playing, i.e., using LLMs to simulate specific personas, has emerged as a key capability in various applications, such as companionship, content creation, and digital games. While current models effectively capture character tones and knowledge, simulating the inner thoughts behind their behaviors remains a challenge. Towards cognitive simulation in LLM role-play, previous efforts mainly suffer from two deficiencies: data with high-quality reasoning traces, and reliable reward signals aligned with human preferences. In this paper, we propose HER, a unified framework for cognitive-level persona simulation. HER introduces dual-layer thinking, which distinguishes characters' first-person thinking from LLMs' third-person thinking. To bridge these gaps, we curate reasoning-augmented role-playing data via reverse engineering and construct human-aligned principles and reward models. Leveraging these resources, we train \method models based on Qwen3-32B via supervised and reinforcement learning. Extensive experiments validate the effectiveness of our approach. Notably, our models significantly outperform the Qwen3-32B baseline, achieving a 30.26 improvement on the CoSER benchmark and a 14.97 gain on the Minimax Role-Play Bench. Our datasets, principles, and models will be released to facilitate future research.
OctoBench: Benchmarking Scaffold-Aware Instruction Following in Repository-Grounded Agentic Coding
Jan 16, 2026Modern coding scaffolds turn LLMs into capable software agents, but their ability to follow scaffold-specified instructions remains under-examined, especially when constraints are heterogeneous and persist across interactions. To fill this gap, we introduce OctoBench, which benchmarks scaffold-aware instruction following in repository-grounded agentic coding. OctoBench includes 34 environments and 217 tasks instantiated under three scaffold types, and is paired with 7,098 objective checklist items. To disentangle solving the task from following the rules, we provide an automated observation-and-scoring toolkit that captures full trajectories and performs fine-grained checks. Experiments on eight representative models reveal a systematic gap between task-solving and scaffold-aware compliance, underscoring the need for training and evaluation that explicitly targets heterogeneous instruction following. We release the benchmark to support reproducible benchmarking and to accelerate the development of more scaffold-aware coding agents.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
SynLogic: Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond
May 26, 2025Recent advances such as OpenAI-o1 and DeepSeek R1 have demonstrated the potential of Reinforcement Learning (RL) to enhance reasoning abilities in Large Language Models (LLMs). While open-source replication efforts have primarily focused on mathematical and coding domains, methods and resources for developing general reasoning capabilities remain underexplored. This gap is partly due to the challenge of collecting diverse and verifiable reasoning data suitable for RL. We hypothesize that logical reasoning is critical for developing general reasoning capabilities, as logic forms a fundamental building block of reasoning. In this work, we present SynLogic, a data synthesis framework and dataset that generates diverse logical reasoning data at scale, encompassing 35 diverse logical reasoning tasks. The SynLogic approach enables controlled synthesis of data with adjustable difficulty and quantity. Importantly, all examples can be verified by simple rules, making them ideally suited for RL with verifiable rewards. In our experiments, we validate the effectiveness of RL training on the SynLogic dataset based on 7B and 32B models. SynLogic leads to state-of-the-art logical reasoning performance among open-source datasets, surpassing DeepSeek-R1-Distill-Qwen-32B by 6 points on BBEH. Furthermore, mixing SynLogic data with mathematical and coding tasks improves the training efficiency of these domains and significantly enhances reasoning generalization. Notably, our mixed training model outperforms DeepSeek-R1-Zero-Qwen-32B across multiple benchmarks. These findings position SynLogic as a valuable resource for advancing the broader reasoning capabilities of LLMs. We open-source both the data synthesis pipeline and the SynLogic dataset at https://github.com/MiniMax-AI/SynLogic.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
An In-depth Survey of Large Language Model-based Artificial Intelligence Agents
Sep 23, 2023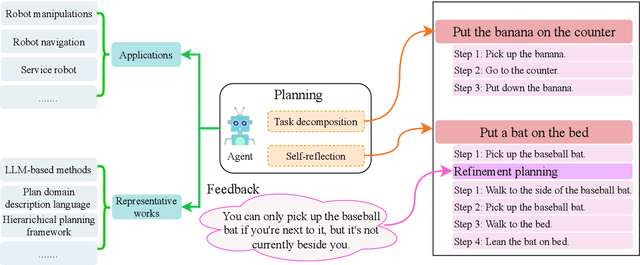
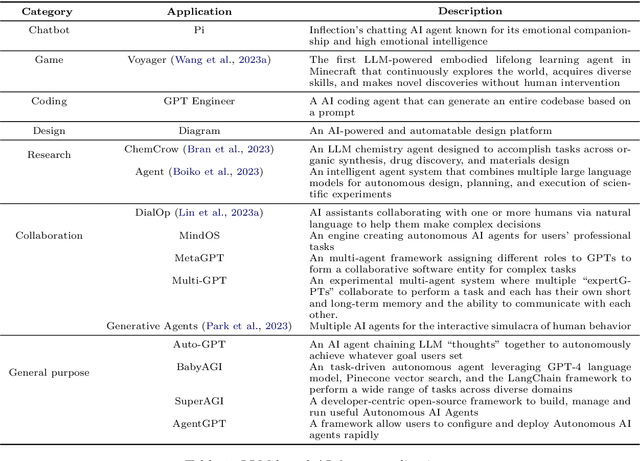
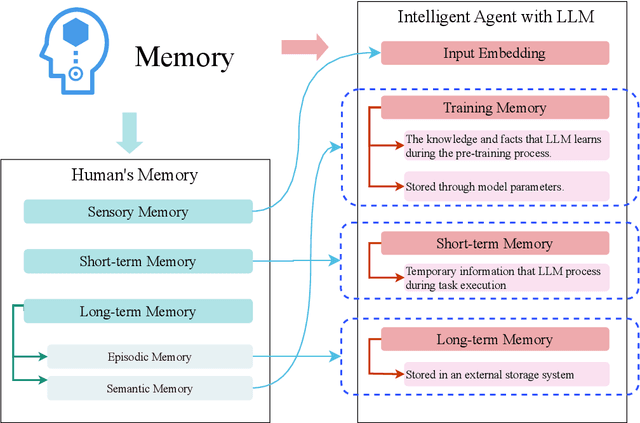
Due to the powerful capabilities demonstrated by large language model (LLM), there has been a recent surge in efforts to integrate them with AI agents to enhance their performance. In this paper, we have explored the core differences and characteristics between LLM-based AI agents and traditional AI agents. Specifically, we first compare the fundamental characteristics of these two types of agents, clarifying the significant advantages of LLM-based agents in handling natural language, knowledge storage, and reasoning capabilities. Subsequently, we conducted an in-depth analysis of the key components of AI agents, including planning, memory, and tool use. Particularly, for the crucial component of memory, this paper introduced an innovative classification scheme, not only departing from traditional classification methods but also providing a fresh perspective on the design of an AI agent's memory system. We firmly believe that in-depth research and understanding of these core components will lay a solid foundation for the future advancement of AI agent technology. At the end of the paper, we provide directional suggestions for further research in this field, with the hope of offering valuable insights to scholars and researchers in the field.
DAIS: Automatic Channel Pruning via Differentiable Annealing Indicator Search
Nov 04, 2020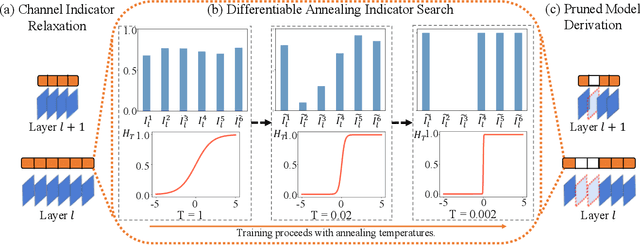
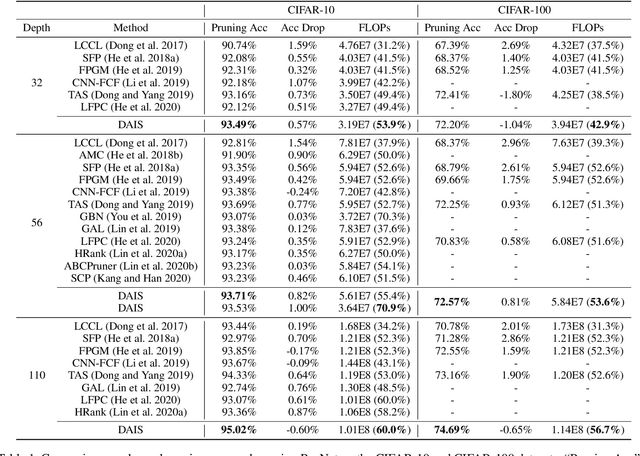
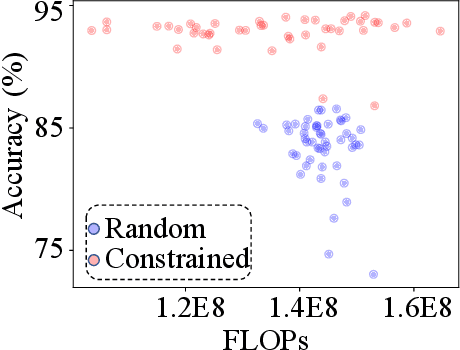
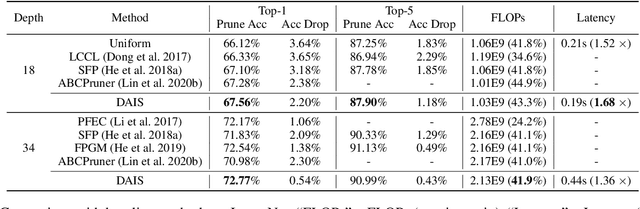
The convolutional neural network has achieved great success in fulfilling computer vision tasks despite large computation overhead against efficient deployment. Structured (channel) pruning is usually applied to reduce the model redundancy while preserving the network structure, such that the pruned network can be easily deployed in practice. However, existing structured pruning methods require hand-crafted rules which may lead to tremendous pruning space. In this paper, we introduce Differentiable Annealing Indicator Search (DAIS) that leverages the strength of neural architecture search in the channel pruning and automatically searches for the effective pruned model with given constraints on computation overhead. Specifically, DAIS relaxes the binarized channel indicators to be continuous and then jointly learns both indicators and model parameters via bi-level optimization. To bridge the non-negligible discrepancy between the continuous model and the target binarized model, DAIS proposes an annealing-based procedure to steer the indicator convergence towards binarized states. Moreover, DAIS designs various regularizations based on a priori structural knowledge to control the pruning sparsity and to improve model performance. Experimental results show that DAIS outperforms state-of-the-art pruning methods on CIFAR-10, CIFAR-100, and ImageNet.
Differentiable Feature Aggregation Search for Knowledge Distillation
Aug 02, 2020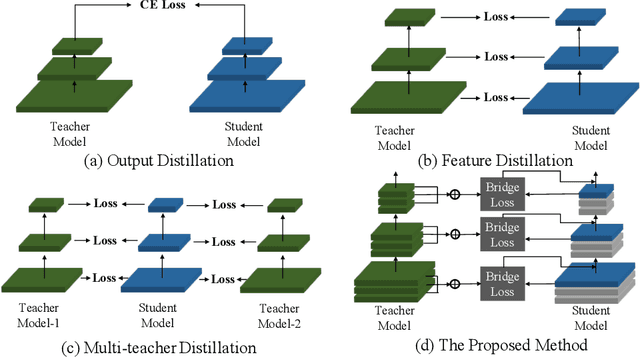
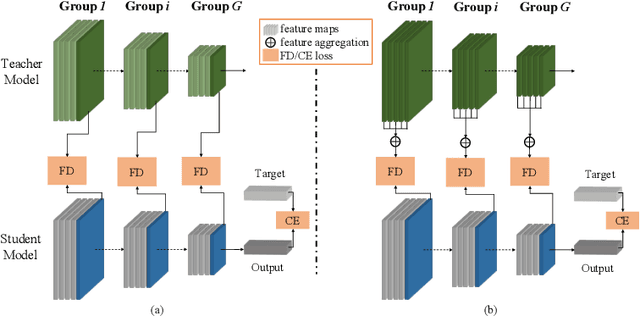

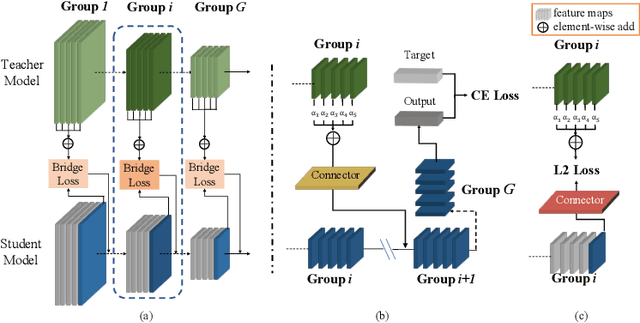
Knowledge distillation has become increasingly important in model compression. It boosts the performance of a miniaturized student network with the supervision of the output distribution and feature maps from a sophisticated teacher network. Some recent works introduce multi-teacher distillation to provide more supervision to the student network. However, the effectiveness of multi-teacher distillation methods are accompanied by costly computation resources. To tackle with both the efficiency and the effectiveness of knowledge distillation, we introduce the feature aggregation to imitate the multi-teacher distillation in the single-teacher distillation framework by extracting informative supervision from multiple teacher feature maps. Specifically, we introduce DFA, a two-stage Differentiable Feature Aggregation search method that motivated by DARTS in neural architecture search, to efficiently find the aggregations. In the first stage, DFA formulates the searching problem as a bi-level optimization and leverages a novel bridge loss, which consists of a student-to-teacher path and a teacher-to-student path, to find appropriate feature aggregations. The two paths act as two players against each other, trying to optimize the unified architecture parameters to the opposite directions while guaranteeing both expressivity and learnability of the feature aggregation simultaneously. In the second stage, DFA performs knowledge distillation with the derived feature aggregation. Experimental results show that DFA outperforms existing methods on CIFAR-100 and CINIC-10 datasets under various teacher-student settings, verifying the effectiveness and robustness of the design.