 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
AMER: Automatic Behavior Modeling and Interaction Exploration in Recommender System
Jun 10, 2020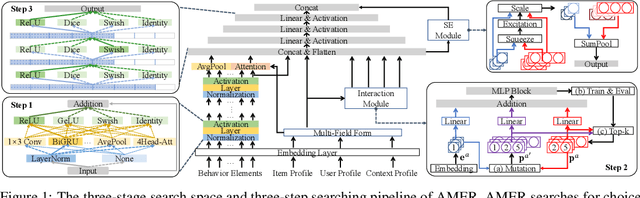
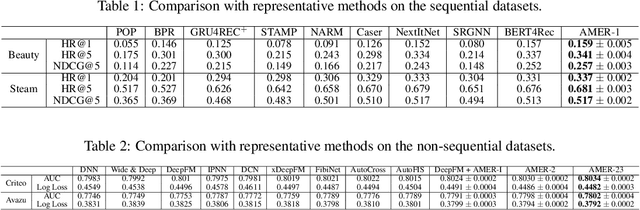
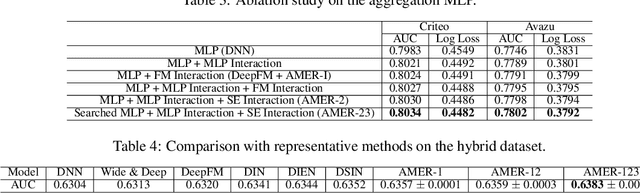
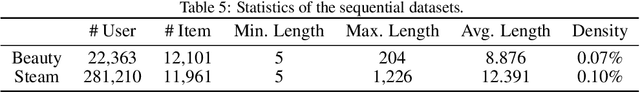
User behavior and feature interactions are crucial in deep learning-based recommender systems. There has been a diverse set of behavior modeling and interaction exploration methods in the literature. Nevertheless, the design of task-aware recommender systems still requires feature engineering and architecture engineering from domain experts. In this work, we introduce AMER, namely Automatic behavior Modeling and interaction Exploration in Recommender systems with Neural Architecture Search (NAS). The core contributions of AMER include the three-stage search space and the tailored three-step searching pipeline. In the first step, AMER searches for residual blocks that incorporate commonly used operations in the block-wise search space of stage 1 to model sequential patterns in user behavior. In the second step, it progressively investigates useful low-order and high-order feature interactions in the non-sequential interaction space of stage 2. Finally, an aggregation multi-layer perceptron (MLP) with shortcut connection is selected from flexible dimension settings of stage~3 to combine features extracted from the previous steps. For efficient and effective NAS, AMER employs the one-shot random search in all three steps. Further analysis reveals that AMER's search space could cover most of the representative behavior extraction and interaction investigation methods, which demonstrates the universality of our design. The extensive experimental results over various scenarios reveal that AMER could outperform competitive baselines with elaborate feature engineering and architecture engineering, indicating both effectiveness and robustness of the proposed method.