 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveFormer: Frequency-Time Decoupled Vision Modeling with Wave Equation
Jan 13, 2026Vision modeling has advanced rapidly with Transformers, whose attention mechanisms capture visual dependencies but lack a principled account of how semantic information propagates spatially. We revisit this problem from a wave-based perspective: feature maps are treated as spatial signals whose evolution over an internal propagation time (aligned with network depth) is governed by an underdamped wave equation. In this formulation, spatial frequency-from low-frequency global layout to high-frequency edges and textures-is modeled explicitly, and its interaction with propagation time is controlled rather than implicitly fixed. We derive a closed-form, frequency-time decoupled solution and implement it as the Wave Propagation Operator (WPO), a lightweight module that models global interactions in O(N log N) time-far lower than attention. Building on WPO, we propose a family of WaveFormer models as drop-in replacements for standard ViTs and CNNs, achieving competitive accuracy across image classification, object detection, and semantic segmentation, while delivering up to 1.6x higher throughput and 30% fewer FLOPs than attention-based alternatives. Furthermore, our results demonstrate that wave propagation introduces a complementary modeling bias to heat-based methods, effectively capturing both global coherence and high-frequency details essential for rich visual semantics. Codes are available at: https://github.com/ZishanShu/WaveFormer.
Predicting Parkinson's Disease Progression Using Statistical and Neural Mixed Effects Models: A Comparative Study on Longitudinal Biomarkers
Jul 26, 2025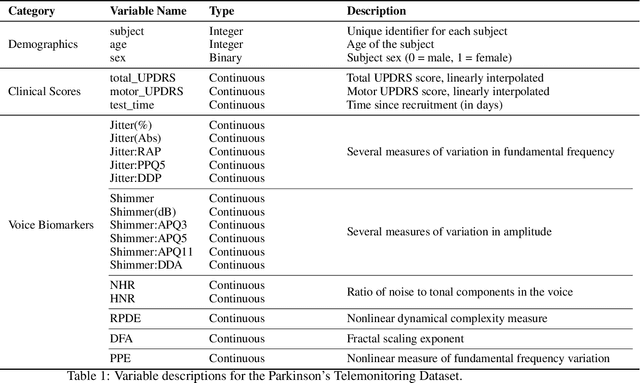
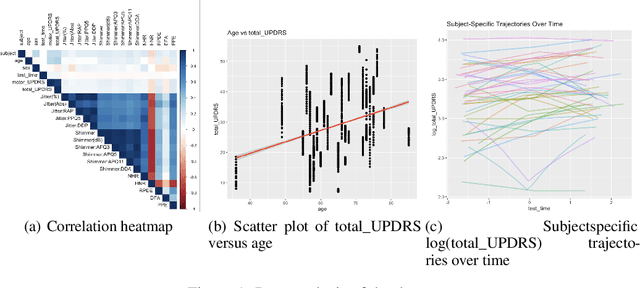
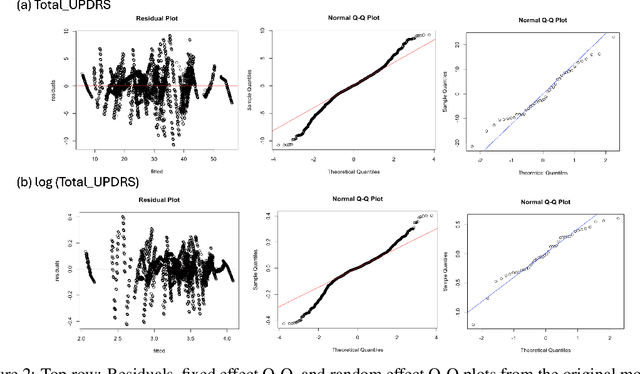

Predicting Parkinson's Disease (PD) progression is crucial, and voice biomarkers offer a non-invasive method for tracking symptom severity (UPDRS scores) through telemonitoring. Analyzing this longitudinal data is challenging due to within-subject correlations and complex, nonlinear patient-specific progression patterns. This study benchmarks LMMs against two advanced hybrid approaches: the Generalized Neural Network Mixed Model (GNMM) (Mandel 2021), which embeds a neural network within a GLMM structure, and the Neural Mixed Effects (NME) model (Wortwein 2023), allowing nonlinear subject-specific parameters throughout the network. Using the Oxford Parkinson's telemonitoring voice dataset, we evaluate these models' performance in predicting Total UPDRS to offer practical guidance for PD research and clinical applications.
A Case Study on Evaluating Genetic Algorithms for Early Building Design Optimization: Comparison with Random and Grid Searches
Apr 10, 2025



In early-stage architectural design, optimization algorithms are essential for efficiently exploring large and complex design spaces under tight computational constraints. While prior research has benchmarked various optimization methods, their findings often lack generalizability to real-world, domain-specific problems, particularly in early building design optimization for energy performance. This study evaluates the effectiveness of Genetic Algorithms (GAs) for early design optimization, focusing on their ability to find near-optimal solutions within limited timeframes. Using a constrained case study, we compare a simple GA to two baseline methods, Random Search (RS) and Grid Search (GS), with each algorithm tested 10 times to enhance the reliability of the conclusions. Our findings show that while RS may miss optimal solutions due to its stochastic nature, it was unexpectedly effective under tight computational limits. Despite being more systematic, GS was outperformed by RS, likely due to the irregular design search space. This suggests that, under strict computational constraints, lightweight methods like RS can sometimes outperform more complex approaches like GA. As this study is limited to a single case under specific constraints, future research should investigate a broader range of design scenarios and computational settings to validate and generalize the findings. Additionally, the potential of Random Search or hybrid optimization methods should be further investigated, particularly in contexts with strict computational limitations.
Point Cloud-Assisted Neural Image Compression
Dec 16, 2024High-efficient image compression is a critical requirement. In several scenarios where multiple modalities of data are captured by different sensors, the auxiliary information from other modalities are not fully leveraged by existing image-only codecs, leading to suboptimal compression efficiency. In this paper, we increase image compression performance with the assistance of point cloud, which is widely adopted in the area of autonomous driving. We first unify the data representation for both modalities to facilitate data processing. Then, we propose the point cloud-assisted neural image codec (PCA-NIC) to enhance the preservation of image texture and structure by utilizing the high-dimensional point cloud information. We further introduce a multi-modal feature fusion transform module (MMFFT) to capture more representative image features, remove redundant information between channels and modalities that are not relevant to the image content. Our work is the first to improve image compression performance using point cloud and achieves state-of-the-art performance.
AI's Spatial Intelligence: Evaluating AI's Understanding of Spatial Transformations in PSVT:R and Augmented Reality
Nov 19, 2024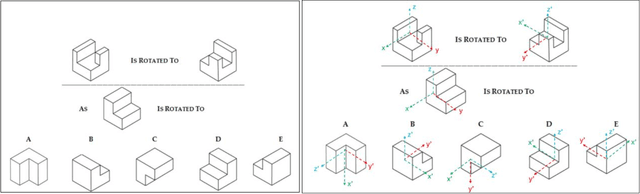
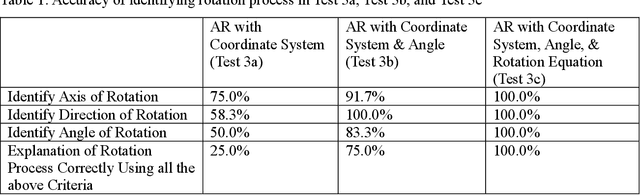
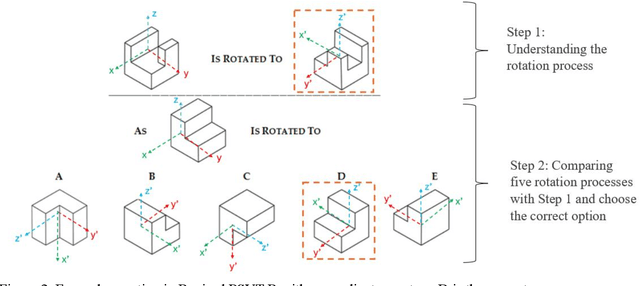
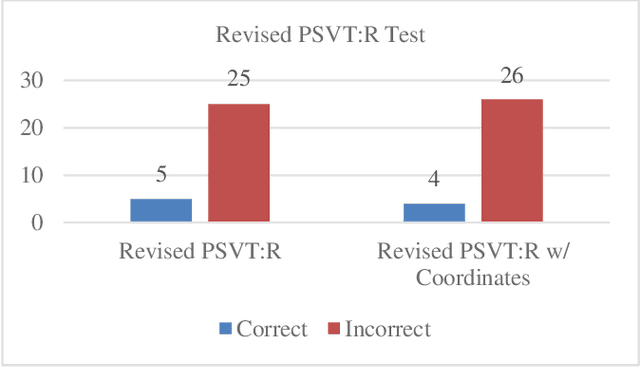
Spatial intelligence is important in Architecture, Construction, Science, Technology, Engineering, and Mathematics (STEM), and Medicine. Understanding three-dimensional (3D) spatial rotations can involve verbal descriptions and visual or interactive examples, illustrating how objects change orientation in 3D space. Recent studies show Artificial Intelligence (AI) with language and vision capabilities still face limitations in spatial reasoning. In this paper, we have studied generative AI's spatial capabilities of understanding rotations of objects utilizing its image and language processing features. We examined the spatial intelligence of the GPT-4 model with vision in understanding spatial rotation process with diagrams based on the Revised Purdue Spatial Visualization Test: Visualization of Rotations (Revised PSVT:R). Next, we incorporated a layer of coordinate system axes on Revised PSVT:R to study the variations in GPT-4's performance. We also examined GPT-4's understanding of 3D rotations in Augmented Reality (AR) scenes that visualize spatial rotations of an object in 3D space and observed increased accuracy of GPT-4's understanding of the rotations by adding supplementary textual information depicting the rotation process or mathematical representations of the rotation (e.g., matrices). The results indicate that while GPT-4 as a major current Generative AI model lacks the understanding of a spatial rotation process, it has the potential to understand the rotation process with additional information that can be provided by methods such as AR. By combining the potentials in spatial intelligence of AI with AR's interactive visualization abilities, we expect to offer enhanced guidance for students' spatial learning activities. Such spatial guidance can benefit understanding spatial transformations and additionally support processes like assembly, fabrication, and manufacturing.
Disttack: Graph Adversarial Attacks Toward Distributed GNN Training
May 10, 2024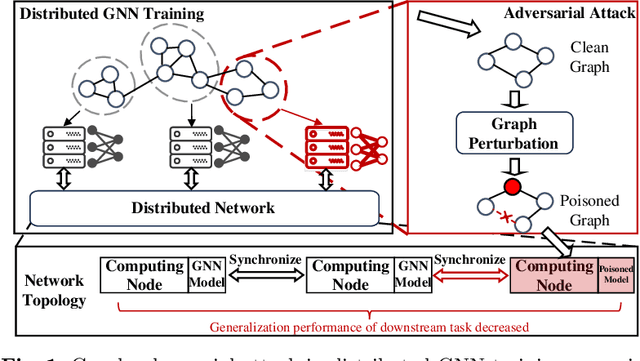
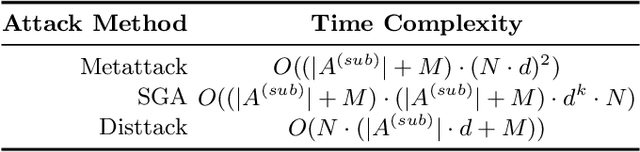
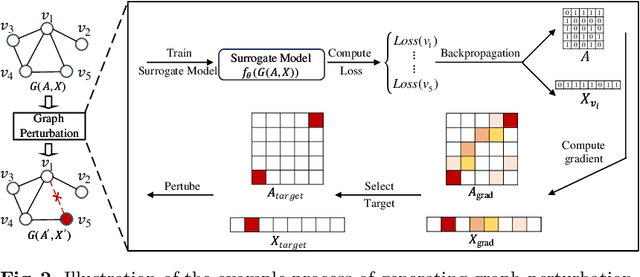
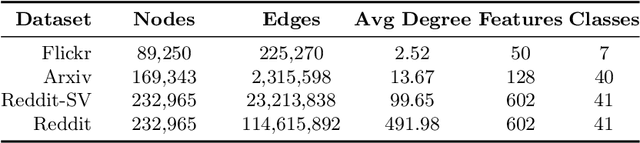
Graph Neural Networks (GNNs) have emerged as potent models for graph learning. Distributing the training process across multiple computing nodes is the most promising solution to address the challenges of ever-growing real-world graphs. However, current adversarial attack methods on GNNs neglect the characteristics and applications of the distributed scenario, leading to suboptimal performance and inefficiency in attacking distributed GNN training. In this study, we introduce Disttack, the first framework of adversarial attacks for distributed GNN training that leverages the characteristics of frequent gradient updates in a distributed system. Specifically, Disttack corrupts distributed GNN training by injecting adversarial attacks into one single computing node. The attacked subgraphs are precisely perturbed to induce an abnormal gradient ascent in backpropagation, disrupting gradient synchronization between computing nodes and thus leading to a significant performance decline of the trained GNN. We evaluate Disttack on four large real-world graphs by attacking five widely adopted GNNs. Compared with the state-of-the-art attack method, experimental results demonstrate that Disttack amplifies the model accuracy degradation by 2.75$\times$ and achieves speedup by 17.33$\times$ on average while maintaining unnoticeability.
Semantic Is Enough: Only Semantic Information For NeRF Reconstruction
Mar 24, 2024



Recent research that combines implicit 3D representation with semantic information, like Semantic-NeRF, has proven that NeRF model could perform excellently in rendering 3D structures with semantic labels. This research aims to extend the Semantic Neural Radiance Fields (Semantic-NeRF) model by focusing solely on semantic output and removing the RGB output component. We reformulate the model and its training procedure to leverage only the cross-entropy loss between the model semantic output and the ground truth semantic images, removing the colour data traditionally used in the original Semantic-NeRF approach. We then conduct a series of identical experiments using the original and the modified Semantic-NeRF model. Our primary objective is to obverse the impact of this modification on the model performance by Semantic-NeRF, focusing on tasks such as scene understanding, object detection, and segmentation. The results offer valuable insights into the new way of rendering the scenes and provide an avenue for further research and development in semantic-focused 3D scene understanding.
Revisiting Edge Perturbation for Graph Neural Network in Graph Data Augmentation and Attack
Mar 10, 2024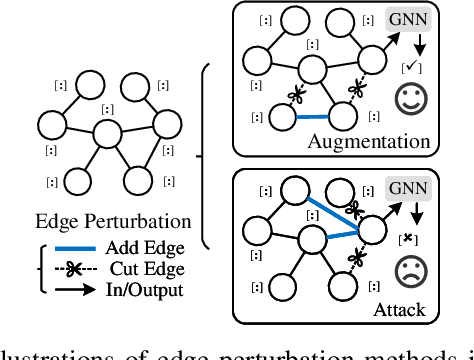
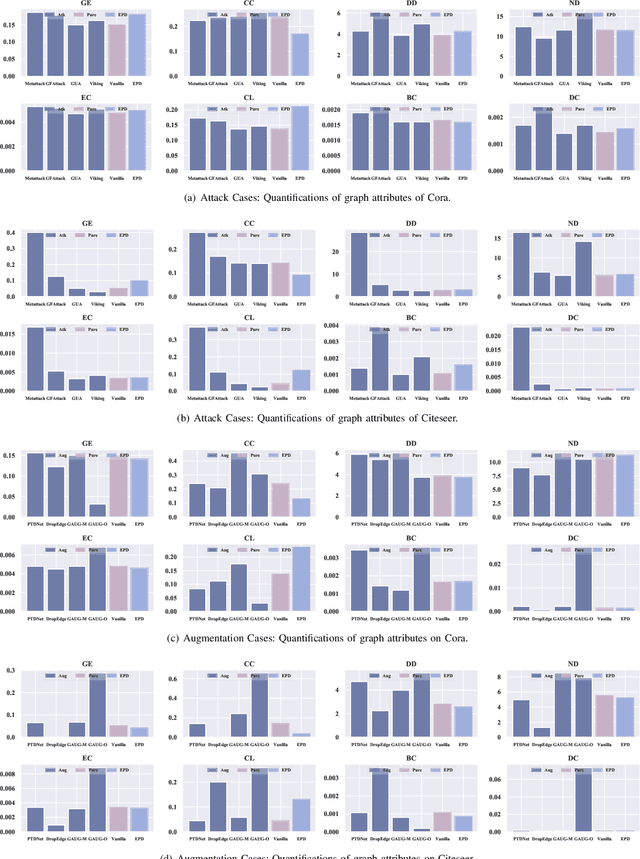
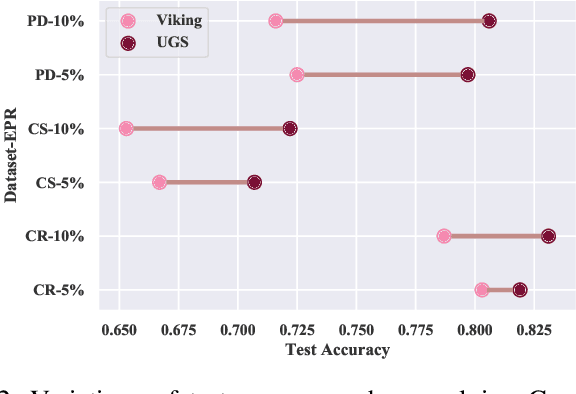
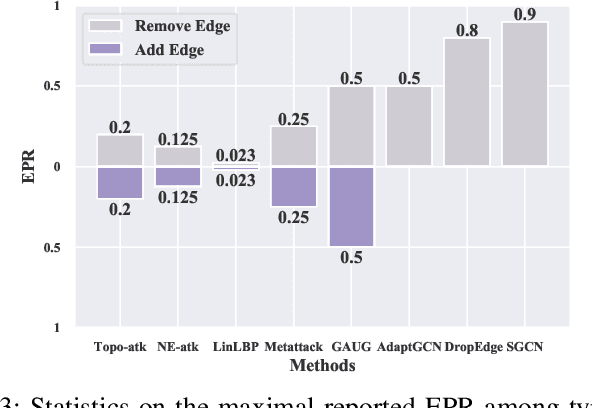
Edge perturbation is a basic method to modify graph structures. It can be categorized into two veins based on their effects on the performance of graph neural networks (GNNs), i.e., graph data augmentation and attack. Surprisingly, both veins of edge perturbation methods employ the same operations, yet yield opposite effects on GNNs' accuracy. A distinct boundary between these methods in using edge perturbation has never been clearly defined. Consequently, inappropriate perturbations may lead to undesirable outcomes, necessitating precise adjustments to achieve desired effects. Therefore, questions of ``why edge perturbation has a two-faced effect?'' and ``what makes edge perturbation flexible and effective?'' still remain unanswered. In this paper, we will answer these questions by proposing a unified formulation and establishing a clear boundary between two categories of edge perturbation methods. Specifically, we conduct experiments to elucidate the differences and similarities between these methods and theoretically unify the workflow of these methods by casting it to one optimization problem. Then, we devise Edge Priority Detector (EPD) to generate a novel priority metric, bridging these methods up in the workflow. Experiments show that EPD can make augmentation or attack flexibly and achieve comparable or superior performance to other counterparts with less time overhead.
Incremental Bayesian Learning for Fail-Operational Control in Autonomous Driving
Mar 07, 2024



Abrupt maneuvers by surrounding vehicles (SVs) can typically lead to safety concerns and affect the task efficiency of the ego vehicle (EV), especially with model uncertainties stemming from environmental disturbances. This paper presents a real-time fail-operational controller that ensures the asymptotic convergence of an uncertain EV to a safe state, while preserving task efficiency in dynamic environments. An incremental Bayesian learning approach is developed to facilitate online learning and inference of changing environmental disturbances. Leveraging disturbance quantification and constraint transformation, we develop a stochastic fail-operational barrier based on the control barrier function (CBF). With this development, the uncertain EV is able to converge asymptotically from an unsafe state to a defined safe state with probabilistic stability. Subsequently, the stochastic fail-operational barrier is integrated into an efficient fail-operational controller based on quadratic programming (QP). This controller is tailored for the EV operating under control constraints in the presence of environmental disturbances, with both safety and efficiency objectives taken into consideration. We validate the proposed framework in connected cruise control (CCC) tasks, where SVs perform aggressive driving maneuvers. The simulation results demonstrate that our method empowers the EV to swiftly return to a safe state while upholding task efficiency in real time, even under time-varying environmental disturbances.
Multi-3D-Models Registration-Based Augmented Reality (AR) Instructions for Assembly
Nov 29, 2023



This paper introduces a novel, markerless, step-by-step, in-situ 3D Augmented Reality (AR) instruction method and its application - BRICKxAR (Multi 3D Models/M3D) - for small parts assembly. BRICKxAR (M3D) realistically visualizes rendered 3D assembly parts at the assembly location of the physical assembly model (Figure 1). The user controls the assembly process through a user interface. BRICKxAR (M3D) utilizes deep learning-trained 3D model-based registration. Object recognition and tracking become challenging as the assembly model updates at each step. Additionally, not every part in a 3D assembly may be visible to the camera during the assembly. BRICKxAR (M3D) combines multiple assembly phases with a step count to address these challenges. Thus, using fewer phases simplifies the complex assembly process while step count facilitates accurate object recognition and precise visualization of each step. A testing and heuristic evaluation of the BRICKxAR (M3D) prototype and qualitative analysis were conducted with users and experts in visualization and human-computer interaction. Providing robust 3D AR instructions and allowing the handling of the assembly model, BRICKxAR (M3D) has the potential to be used at different scales ranging from manufacturing assembly to construction.