 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulSeek: Exploring the Use of Social Cues in LLM-based Information Seeking
Jan 03, 2026Social cues, which convey others' presence, behaviors, or identities, play a crucial role in human information seeking by helping individuals judge relevance and trustworthiness. However, existing LLM-based search systems primarily rely on semantic features, creating a misalignment with the socialized cognition underlying natural information seeking. To address this gap, we explore how the integration of social cues into LLM-based search influences users' perceptions, experiences, and behaviors. Focusing on social media platforms that are beginning to adopt LLM-based search, we integrate design workshops, the implementation of the prototype system (SoulSeek), a between-subjects study, and mixed-method analyses to examine both outcome- and process-level findings. The workshop informs the prototype's cue-integrated design. The study shows that social cues improve perceived outcomes and experiences, promote reflective information behaviors, and reveal limits of current LLM-based search. We propose design implications emphasizing better social-knowledge understanding, personalized cue settings, and controllable interactions.
Generalization of Diffusion Models Arises with a Balanced Representation Space
Dec 24, 2025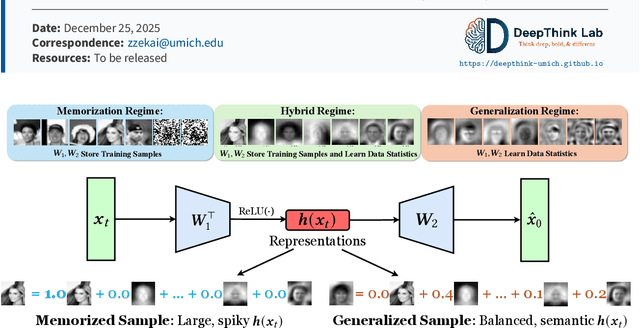
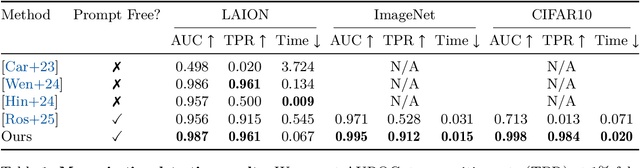
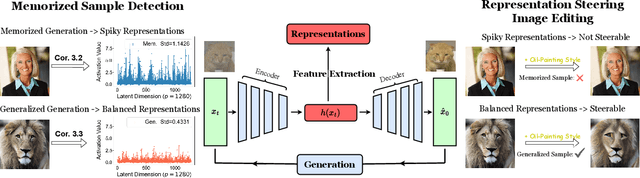

Diffusion models excel at generating high-quality, diverse samples, yet they risk memorizing training data when overfit to the training objective. We analyze the distinctions between memorization and generalization in diffusion models through the lens of representation learning. By investigating a two-layer ReLU denoising autoencoder (DAE), we prove that (i) memorization corresponds to the model storing raw training samples in the learned weights for encoding and decoding, yielding localized "spiky" representations, whereas (ii) generalization arises when the model captures local data statistics, producing "balanced" representations. Furthermore, we validate these theoretical findings on real-world unconditional and text-to-image diffusion models, demonstrating that the same representation structures emerge in deep generative models with significant practical implications. Building on these insights, we propose a representation-based method for detecting memorization and a training-free editing technique that allows precise control via representation steering. Together, our results highlight that learning good representations is central to novel and meaningful generative modeling.
Coarse-to-Fine Hierarchical Alignment for UAV-based Human Detection using Diffusion Models
Dec 15, 2025Training object detectors demands extensive, task-specific annotations, yet this requirement becomes impractical in UAV-based human detection due to constantly shifting target distributions and the scarcity of labeled images. As a remedy, synthetic simulators are adopted to generate annotated data, with a low annotation cost. However, the domain gap between synthetic and real images hinders the model from being effectively applied to the target domain. Accordingly, we introduce Coarse-to-Fine Hierarchical Alignment (CFHA), a three-stage diffusion-based framework designed to transform synthetic data for UAV-based human detection, narrowing the domain gap while preserving the original synthetic labels. CFHA explicitly decouples global style and local content domain discrepancies and bridges those gaps using three modules: (1) Global Style Transfer -- a diffusion model aligns color, illumination, and texture statistics of synthetic images to the realistic style, using only a small real reference set; (2) Local Refinement -- a super-resolution diffusion model is used to facilitate fine-grained and photorealistic details for the small objects, such as human instances, preserving shape and boundary integrity; (3) Hallucination Removal -- a module that filters out human instances whose visual attributes do not align with real-world data to make the human appearance closer to the target distribution. Extensive experiments on public UAV Sim2Real detection benchmarks demonstrate that our methods significantly improve the detection accuracy compared to the non-transformed baselines. Specifically, our method achieves up to $+14.1$ improvement of mAP50 on Semantic-Drone benchmark. Ablation studies confirm the complementary roles of the global and local stages and highlight the importance of hierarchical alignment. The code is released at \href{https://github.com/liwd190019/CFHA}{this url}.
UniCoN: Universal Conditional Networks for Multi-Age Embryonic Cartilage Segmentation with Sparsely Annotated Data
Oct 16, 2024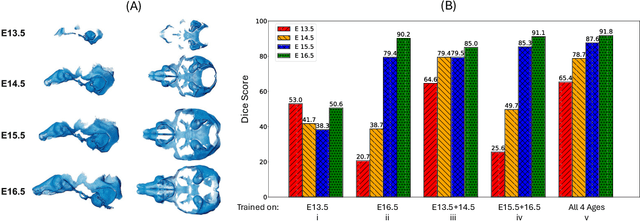
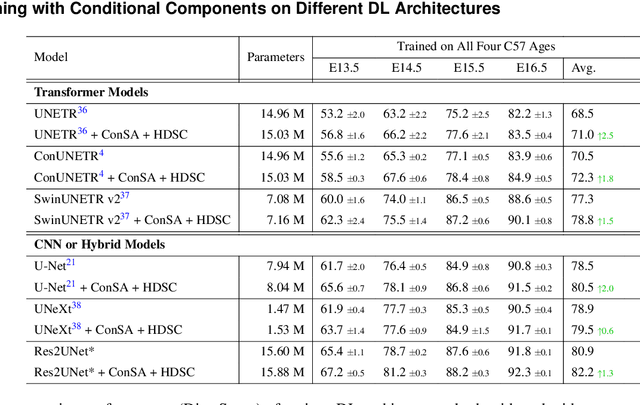
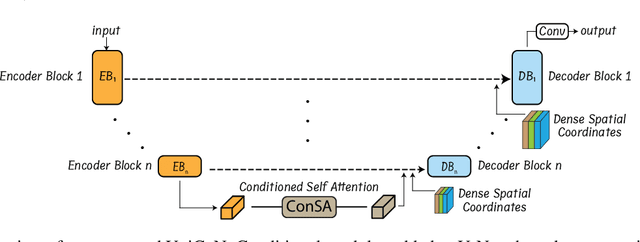
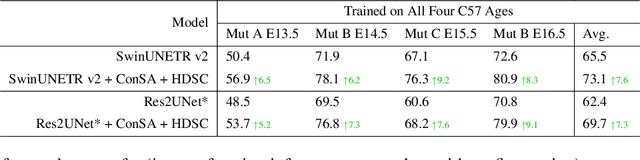
Osteochondrodysplasia, affecting 2-3% of newborns globally, is a group of bone and cartilage disorders that often result in head malformations, contributing to childhood morbidity and reduced quality of life. Current research on this disease using mouse models faces challenges since it involves accurately segmenting the developing cartilage in 3D micro-CT images of embryonic mice. Tackling this segmentation task with deep learning (DL) methods is laborious due to the big burden of manual image annotation, expensive due to the high acquisition costs of 3D micro-CT images, and difficult due to embryonic cartilage's complex and rapidly changing shapes. While DL approaches have been proposed to automate cartilage segmentation, most such models have limited accuracy and generalizability, especially across data from different embryonic age groups. To address these limitations, we propose novel DL methods that can be adopted by any DL architectures -- including CNNs, Transformers, or hybrid models -- which effectively leverage age and spatial information to enhance model performance. Specifically, we propose two new mechanisms, one conditioned on discrete age categories and the other on continuous image crop locations, to enable an accurate representation of cartilage shape changes across ages and local shape details throughout the cranial region. Extensive experiments on multi-age cartilage segmentation datasets show significant and consistent performance improvements when integrating our conditional modules into popular DL segmentation architectures. On average, we achieve a 1.7% Dice score increase with minimal computational overhead and a 7.5% improvement on unseen data. These results highlight the potential of our approach for developing robust, universal models capable of handling diverse datasets with limited annotated data, a key challenge in DL-based medical image analysis.
Disttack: Graph Adversarial Attacks Toward Distributed GNN Training
May 10, 2024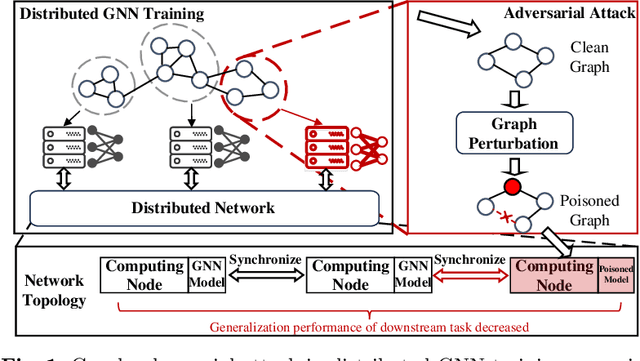
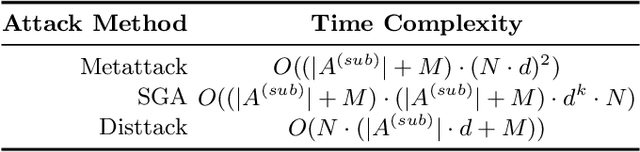
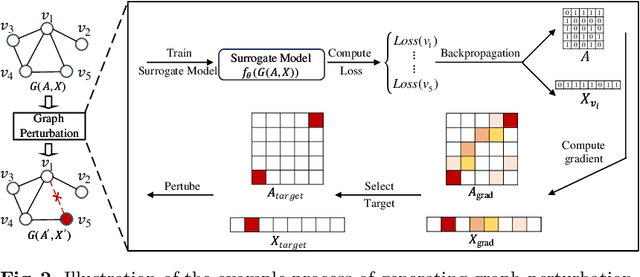
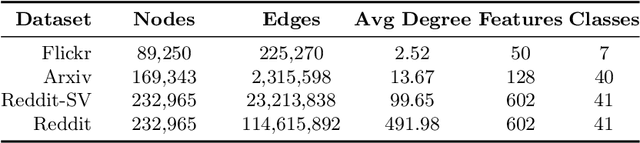
Graph Neural Networks (GNNs) have emerged as potent models for graph learning. Distributing the training process across multiple computing nodes is the most promising solution to address the challenges of ever-growing real-world graphs. However, current adversarial attack methods on GNNs neglect the characteristics and applications of the distributed scenario, leading to suboptimal performance and inefficiency in attacking distributed GNN training. In this study, we introduce Disttack, the first framework of adversarial attacks for distributed GNN training that leverages the characteristics of frequent gradient updates in a distributed system. Specifically, Disttack corrupts distributed GNN training by injecting adversarial attacks into one single computing node. The attacked subgraphs are precisely perturbed to induce an abnormal gradient ascent in backpropagation, disrupting gradient synchronization between computing nodes and thus leading to a significant performance decline of the trained GNN. We evaluate Disttack on four large real-world graphs by attacking five widely adopted GNNs. Compared with the state-of-the-art attack method, experimental results demonstrate that Disttack amplifies the model accuracy degradation by 2.75$\times$ and achieves speedup by 17.33$\times$ on average while maintaining unnoticeability.
Revisiting Edge Perturbation for Graph Neural Network in Graph Data Augmentation and Attack
Mar 10, 2024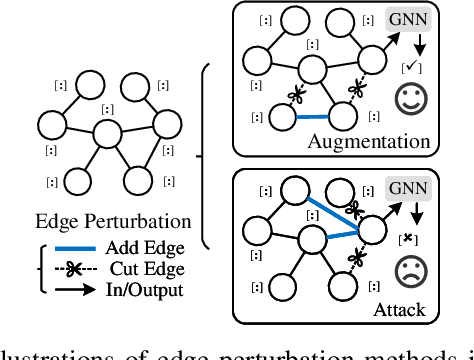
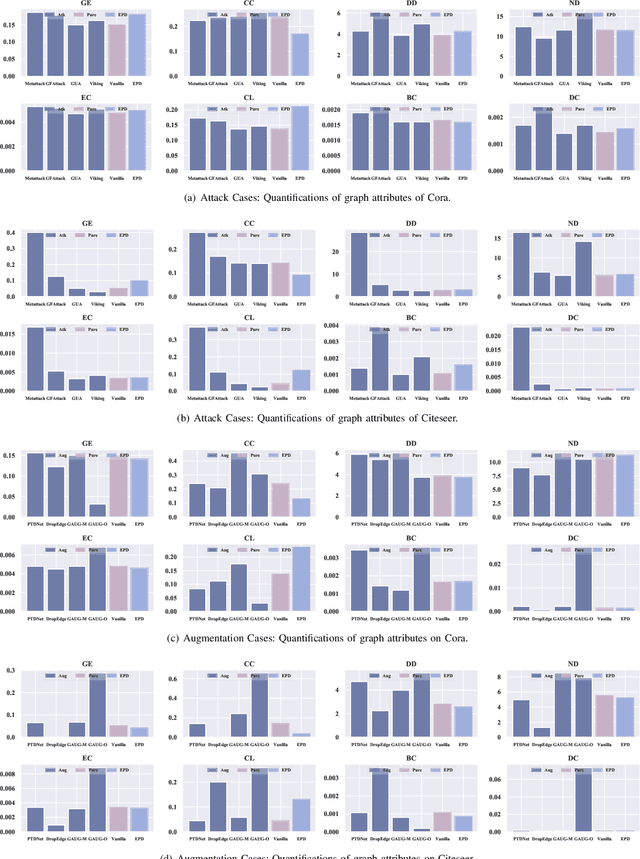
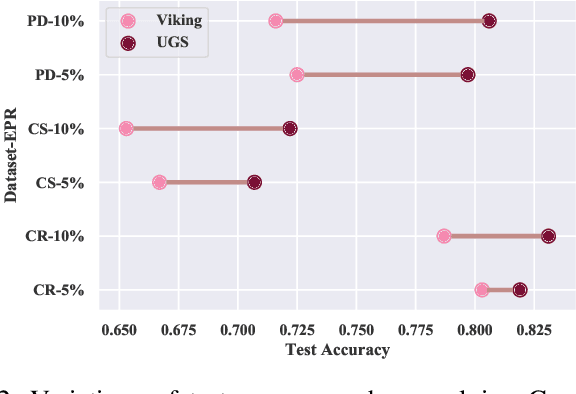
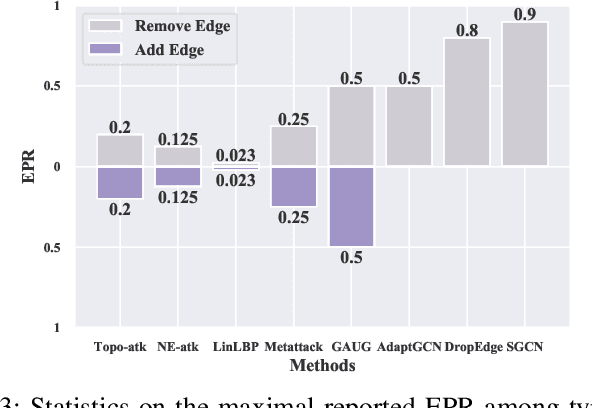
Edge perturbation is a basic method to modify graph structures. It can be categorized into two veins based on their effects on the performance of graph neural networks (GNNs), i.e., graph data augmentation and attack. Surprisingly, both veins of edge perturbation methods employ the same operations, yet yield opposite effects on GNNs' accuracy. A distinct boundary between these methods in using edge perturbation has never been clearly defined. Consequently, inappropriate perturbations may lead to undesirable outcomes, necessitating precise adjustments to achieve desired effects. Therefore, questions of ``why edge perturbation has a two-faced effect?'' and ``what makes edge perturbation flexible and effective?'' still remain unanswered. In this paper, we will answer these questions by proposing a unified formulation and establishing a clear boundary between two categories of edge perturbation methods. Specifically, we conduct experiments to elucidate the differences and similarities between these methods and theoretically unify the workflow of these methods by casting it to one optimization problem. Then, we devise Edge Priority Detector (EPD) to generate a novel priority metric, bridging these methods up in the workflow. Experiments show that EPD can make augmentation or attack flexibly and achieve comparable or superior performance to other counterparts with less time overhead.
ConUNETR: A Conditional Transformer Network for 3D Micro-CT Embryonic Cartilage Segmentation
Feb 06, 2024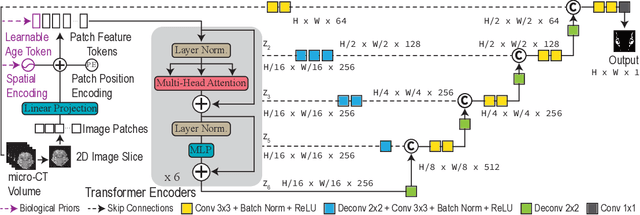
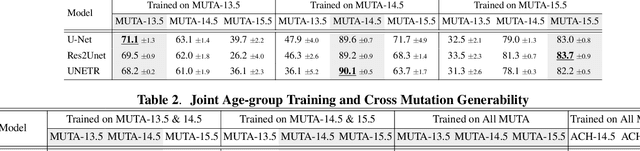

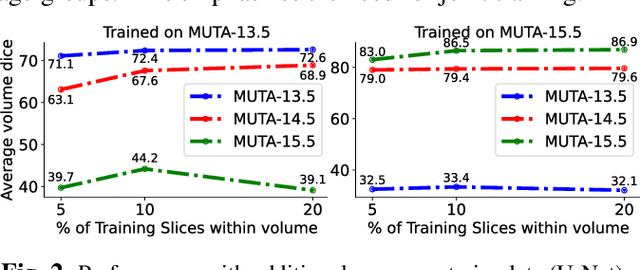
Studying the morphological development of cartilaginous and osseous structures is critical to the early detection of life-threatening skeletal dysmorphology. Embryonic cartilage undergoes rapid structural changes within hours, introducing biological variations and morphological shifts that limit the generalization of deep learning-based segmentation models that infer across multiple embryonic age groups. Obtaining individual models for each age group is expensive and less effective, while direct transfer (predicting an age unseen during training) suffers a potential performance drop due to morphological shifts. We propose a novel Transformer-based segmentation model with improved biological priors that better distills morphologically diverse information through conditional mechanisms. This enables a single model to accurately predict cartilage across multiple age groups. Experiments on the mice cartilage dataset show the superiority of our new model compared to other competitive segmentation models. Additional studies on a separate mice cartilage dataset with a distinct mutation show that our model generalizes well and effectively captures age-based cartilage morphology patterns.
TLMCM Network for Medical Image Hierarchical Multi-Label Classification
Nov 11, 2023


Medical Image Hierarchical Multi-Label Classification (MI-HMC) is of paramount importance in modern healthcare, presenting two significant challenges: data imbalance and \textit{hierarchy constraint}. Existing solutions involve complex model architecture design or domain-specific preprocessing, demanding considerable expertise or effort in implementation. To address these limitations, this paper proposes Transfer Learning with Maximum Constraint Module (TLMCM) network for the MI-HMC task. The TLMCM network offers a novel approach to overcome the aforementioned challenges, outperforming existing methods based on the Area Under the Average Precision and Recall Curve($AU\overline{(PRC)}$) metric. In addition, this research proposes two novel accuracy metrics, $EMR$ and $HammingAccuracy$, which have not been extensively explored in the context of the MI-HMC task. Experimental results demonstrate that the TLMCM network achieves high multi-label prediction accuracy($80\%$-$90\%$) for MI-HMC tasks, making it a valuable contribution to healthcare domain applications.
Detaching and Boosting: Dual Engine for Scale-Invariant Self-Supervised Monocular Depth Estimation
Oct 08, 2022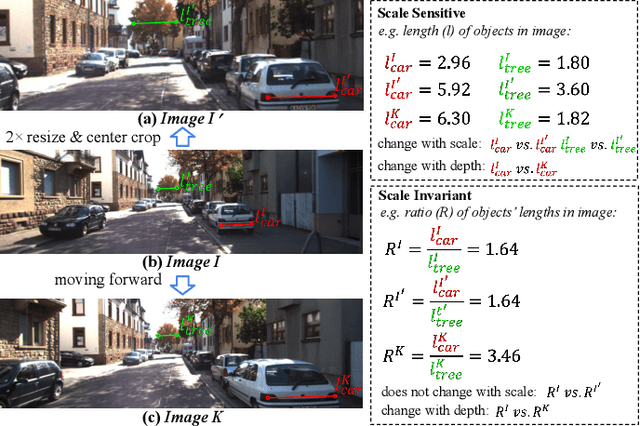
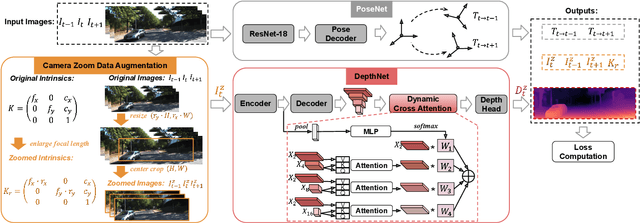
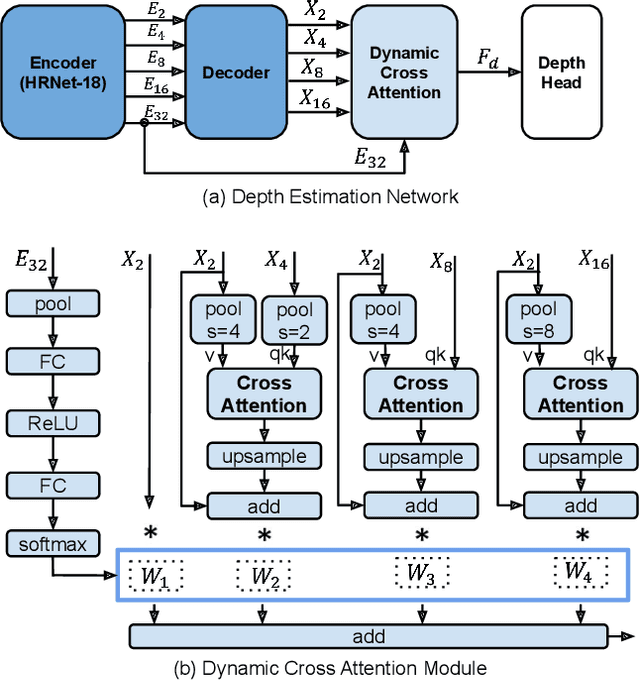
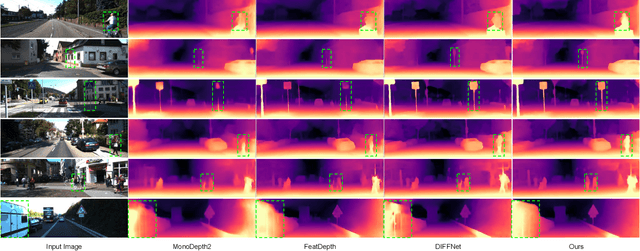
Monocular depth estimation (MDE) in the self-supervised scenario has emerged as a promising method as it refrains from the requirement of ground truth depth. Despite continuous efforts, MDE is still sensitive to scale changes especially when all the training samples are from one single camera. Meanwhile, it deteriorates further since camera movement results in heavy coupling between the predicted depth and the scale change. In this paper, we present a scale-invariant approach for self-supervised MDE, in which scale-sensitive features (SSFs) are detached away while scale-invariant features (SIFs) are boosted further. To be specific, a simple but effective data augmentation by imitating the camera zooming process is proposed to detach SSFs, making the model robust to scale changes. Besides, a dynamic cross-attention module is designed to boost SIFs by fusing multi-scale cross-attention features adaptively. Extensive experiments on the KITTI dataset demonstrate that the detaching and boosting strategies are mutually complementary in MDE and our approach achieves new State-of-The-Art performance against existing works from 0.097 to 0.090 w.r.t absolute relative error. The code will be made public soon.
Real-time Locational Marginal Price Forecasting Using Generative Adversarial Network
Nov 09, 2020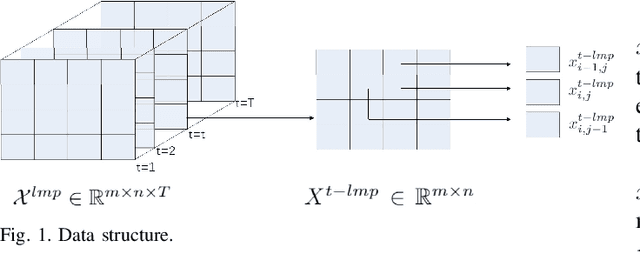
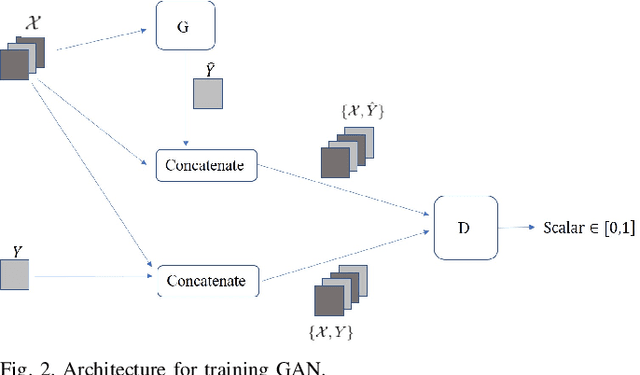
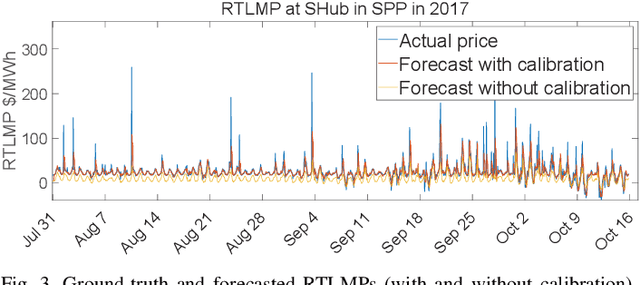
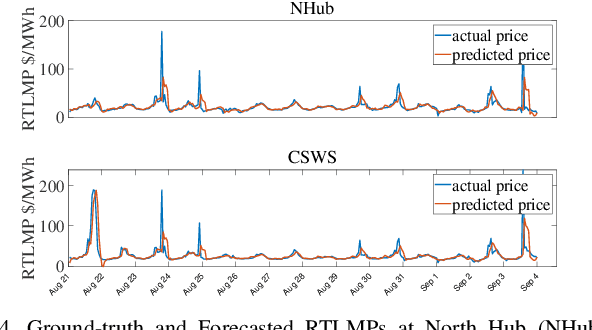
In this paper, we propose a model-free unsupervised learning approach to forecast real-time locational marginal prices (RTLMPs) in wholesale electricity markets. By organizing system-wide hourly RTLMP data into a 3-dimensional (3D) tensor consisting of a series of time-indexed matrices, we formulate the RTLMP forecasting problem as a problem of generating the next matrix with forecasted RTLMPs given the historical RTLMP tensor, and propose a generative adversarial network (GAN) model to forecast RTLMPs. The proposed formulation preserves the spatio-temporal correlations among system-wide RTLMPs in the format of historical RTLMP tensor. The proposed GAN model learns the spatio-temporal correlations using the historical RTLMP tensors and generate RTLMPs that are statistically similar and temporally coherent to the historical RTLMP tensor. The proposed approach forecasts system-wide RTLMPs using only publicly available historical price data, without involving confidential information of system model, such as system parameters, topology, or operating conditions. The effectiveness of the proposed approach is verified through case studies using historical RTLMP data in Southwest Power Pool (SPP).