 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Random Forest Ensemble of Intuitionistic Fuzzy Decision Trees
Mar 17, 2024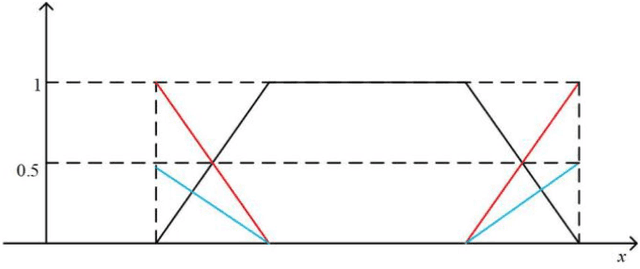
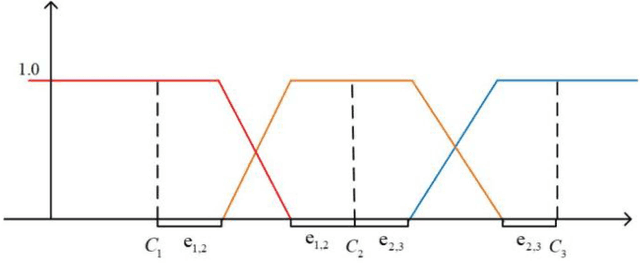

Classification is essential to the applications in the field of data mining, artificial intelligence, and fault detection. There exists a strong need in developing accurate, suitable, and efficient classification methods and algorithms with broad applicability. Random forest is a general algorithm that is often used for classification under complex conditions. Although it has been widely adopted, its combination with diverse fuzzy theory is still worth exploring. In this paper, we propose the intuitionistic fuzzy random forest (IFRF), a new random forest ensemble of intuitionistic fuzzy decision trees (IFDT). Such trees in forest use intuitionistic fuzzy information gain to select features and consider hesitation in information transmission. The proposed method enjoys the power of the randomness from bootstrapped sampling and feature selection, the flexibility of fuzzy logic and fuzzy sets, and the robustness of multiple classifier systems. Extensive experiments demonstrate that the IFRF has competitative and superior performance compared to other state-of-the-art fuzzy and ensemble algorithms. IFDT is more suitable for ensemble learning with outstanding classification accuracy. This study is the first to propose a random forest ensemble based on the intuitionistic fuzzy theory.
Tree-Based Hard Attention with Self-Motivation for Large Language Models
Feb 14, 2024



While large language models (LLMs) excel at understanding and generating plain text, they are not specifically tailored to handle hierarchical text structures. Extracting the task-desired property from their natural language responses typically necessitates additional processing steps. In fact, selectively comprehending the hierarchical structure of large-scale text is pivotal to understanding its substance. Aligning LLMs more closely with the classification or regression values of specific task through prompting also remains challenging. To this end, we propose a novel framework called Tree-Based Hard Attention with Self-Motivation for Large Language Models (TEAROOM). TEAROOM incorporates a tree-based hard attention mechanism for LLMs to process hierarchically structured text inputs. By leveraging prompting, it enables a frozen LLM to selectively focus on relevant leaves in relation to the root, generating a tailored symbolic representation of their relationship. Moreover, TEAROOM comprises a self-motivation strategy for another LLM equipped with a trainable adapter and a linear layer. The selected symbolic outcomes are integrated into another prompt, along with the predictive value of the task. We iteratively feed output values back into the prompt, enabling the trainable LLM to progressively approximate the golden truth. TEAROOM outperforms existing state-of-the-art methods in experimental evaluations across three benchmark datasets, showing its effectiveness in estimating task-specific properties. Through comprehensive experiments and analysis, we have validated the ability of TEAROOM to gradually approach the underlying golden truth through multiple inferences.
GENET: Unleashing the Power of Side Information for Recommendation via Hypergraph Pre-training
Nov 22, 2023



Recommendation with side information has drawn significant research interest due to its potential to mitigate user feedback sparsity. However, existing models struggle with generalization across diverse domains and types of side information. In particular, three challenges have not been addressed, and they are (1) the diverse formats of side information, including text sequences. (2) The diverse semantics of side information that describes items and users from multi-level in a context different from recommendation systems. (3) The diverse correlations in side information to measure similarity over multiple objects beyond pairwise relations. In this paper, we introduce GENET (Generalized hypErgraph pretraiNing on sidE informaTion), which pre-trains user and item representations on feedback-irrelevant side information and fine-tunes the representations on user feedback data. GENET leverages pre-training as a means to prevent side information from overshadowing critical ID features and feedback signals. It employs a hypergraph framework to accommodate various types of diverse side information. During pre-training, GENET integrates tasks for hyperlink prediction and self-supervised contrast to capture fine-grained semantics at both local and global levels. Additionally, it introduces a unique strategy to enhance pre-training robustness by perturbing positive samples while maintaining high-order relations. Extensive experiments demonstrate that GENET exhibits strong generalization capabilities, outperforming the SOTA method by up to 38% in TOP-N recommendation and Sequential recommendation tasks on various datasets with different side information.
An Automatic Design Framework of Swarm Pattern Formation based on Multi-objective Genetic Programming
Nov 01, 2019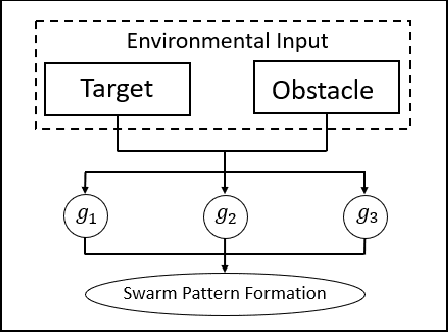
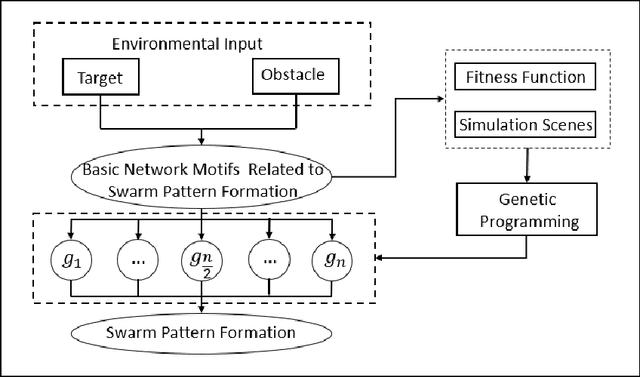
Most existing swarm pattern formation methods depend on a predefined gene regulatory network (GRN) structure that requires designers' priori knowledge, which is difficult to adapt to complex and changeable environments. To dynamically adapt to the complex and changeable environments, we propose an automatic design framework of swarm pattern formation based on multi-objective genetic programming. The proposed framework does not need to define the structure of the GRN-based model in advance, and it applies some basic network motifs to automatically structure the GRN-based model. In addition, a multi-objective genetic programming (MOGP) combines with NSGA-II, namely MOGP-NSGA-II, to balance the complexity and accuracy of the GRN-based model. In evolutionary process, an MOGP-NSGA-II and differential evolution (DE) are applied to optimize the structures and parameters of the GRN-based model in parallel. Simulation results demonstrate that the proposed framework can effectively evolve some novel GRN-based models, and these GRN-based models not only have a simpler structure and a better performance, but also are robust to the complex and changeable environments.
G-flocking: Flocking Model Optimization based on Genetic Framework
Jul 27, 2019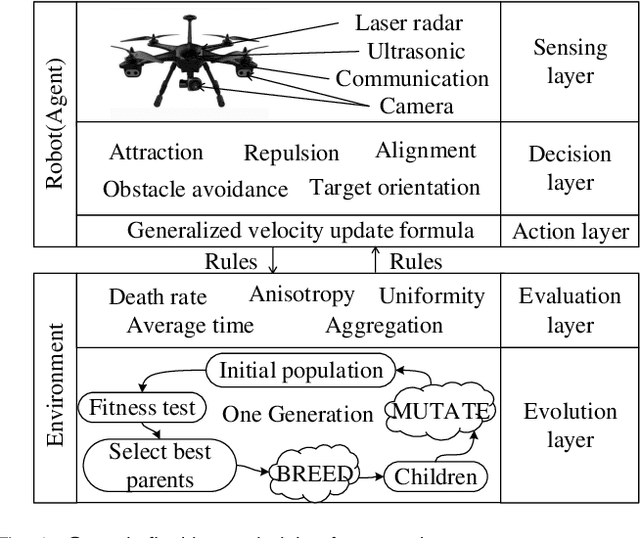
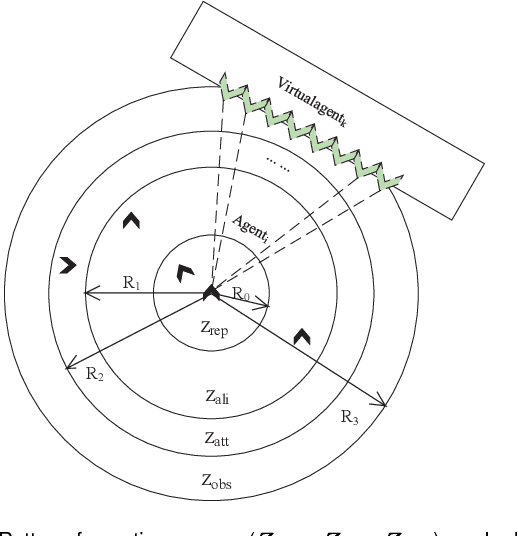
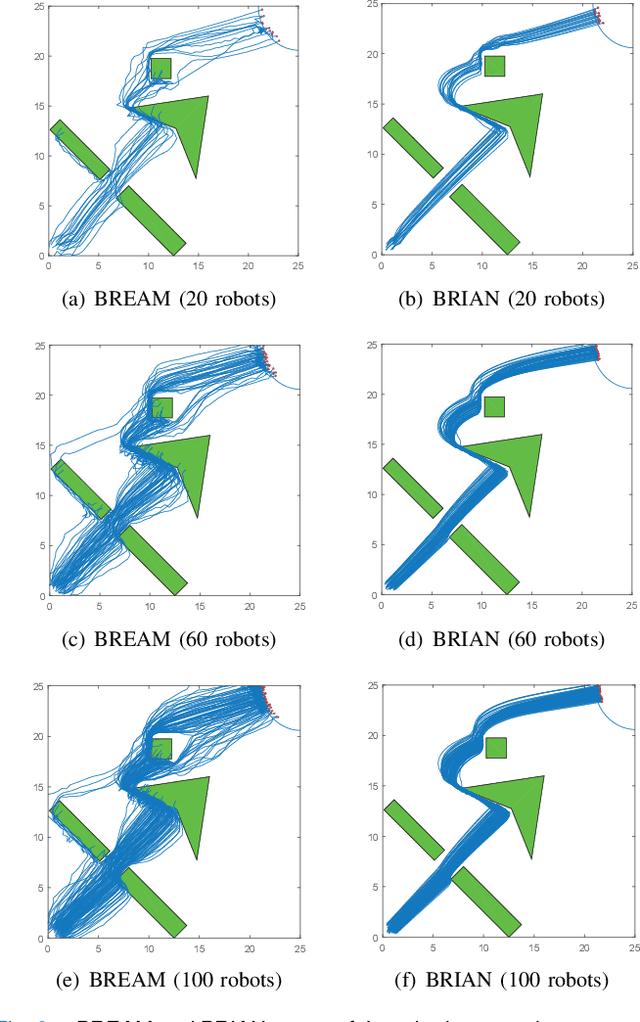
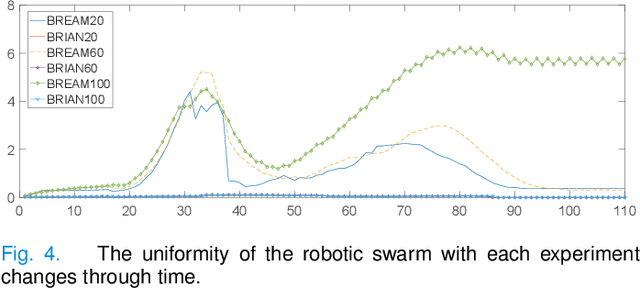
Flocking model has been widely used to control robotic swarm. However, with the increasing scalability, there exist complex conflicts for robotic swarm in autonomous navigation, brought by internal pattern maintenance, external environment changes, and target area orientation, which results in poor stability and adaptability. Hence, optimizing the flocking model for robotic swarm in autonomous navigation is an important and meaningful research domain.
Private Model Compression via Knowledge Distillation
Nov 13, 2018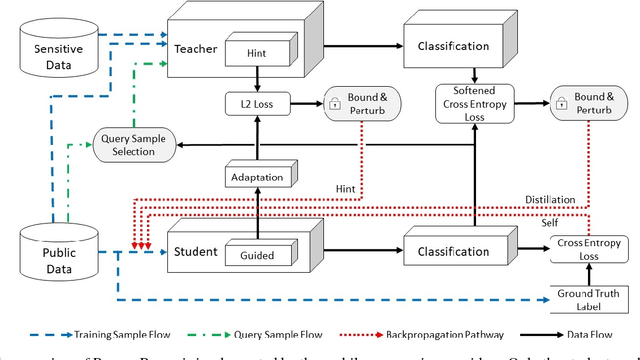
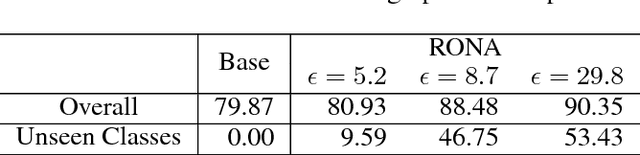
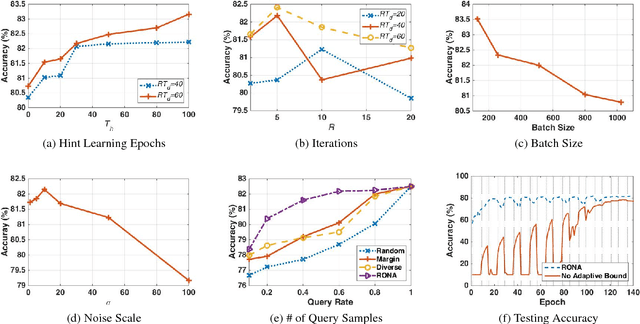
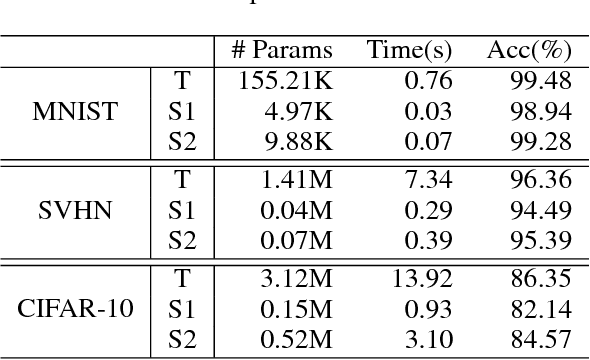
The soaring demand for intelligent mobile applications calls for deploying powerful deep neural networks (DNNs) on mobile devices. However, the outstanding performance of DNNs notoriously relies on increasingly complex models, which in turn is associated with an increase in computational expense far surpassing mobile devices' capacity. What is worse, app service providers need to collect and utilize a large volume of users' data, which contain sensitive information, to build the sophisticated DNN models. Directly deploying these models on public mobile devices presents prohibitive privacy risk. To benefit from the on-device deep learning without the capacity and privacy concerns, we design a private model compression framework RONA. Following the knowledge distillation paradigm, we jointly use hint learning, distillation learning, and self learning to train a compact and fast neural network. The knowledge distilled from the cumbersome model is adaptively bounded and carefully perturbed to enforce differential privacy. We further propose an elegant query sample selection method to reduce the number of queries and control the privacy loss. A series of empirical evaluations as well as the implementation on an Android mobile device show that RONA can not only compress cumbersome models efficiently but also provide a strong privacy guarantee. For example, on SVHN, when a meaningful $(9.83,10^{-6})$-differential privacy is guaranteed, the compact model trained by RONA can obtain 20$\times$ compression ratio and 19$\times$ speed-up with merely 0.97% accuracy loss.
Not Just Privacy: Improving Performance of Private Deep Learning in Mobile Cloud
Sep 19, 2018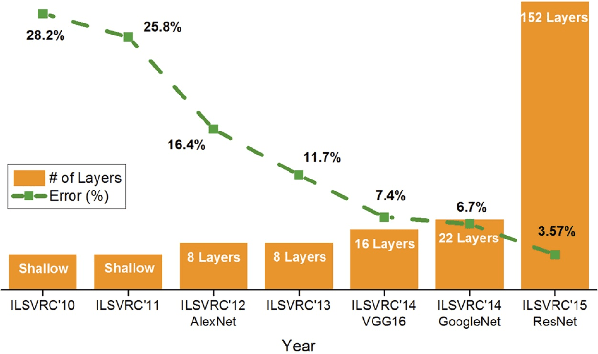
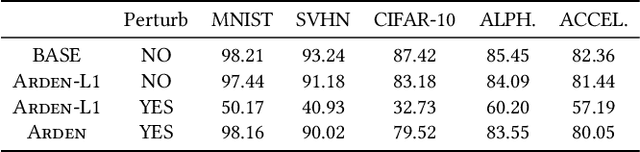
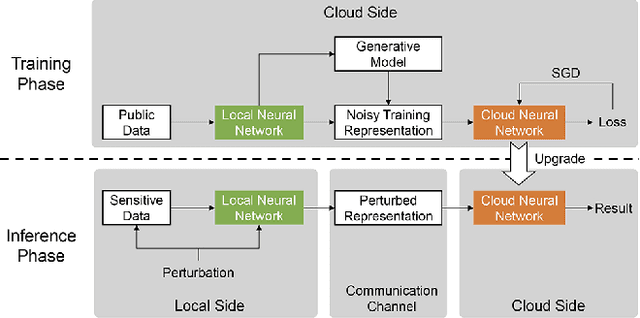
The increasing demand for on-device deep learning services calls for a highly efficient manner to deploy deep neural networks (DNNs) on mobile devices with limited capacity. The cloud-based solution is a promising approach to enabling deep learning applications on mobile devices where the large portions of a DNN are offloaded to the cloud. However, revealing data to the cloud leads to potential privacy risk. To benefit from the cloud data center without the privacy risk, we design, evaluate, and implement a cloud-based framework ARDEN which partitions the DNN across mobile devices and cloud data centers. A simple data transformation is performed on the mobile device, while the resource-hungry training and the complex inference rely on the cloud data center. To protect the sensitive information, a lightweight privacy-preserving mechanism consisting of arbitrary data nullification and random noise addition is introduced, which provides strong privacy guarantee. A rigorous privacy budget analysis is given. Nonetheless, the private perturbation to the original data inevitably has a negative impact on the performance of further inference on the cloud side. To mitigate this influence, we propose a noisy training method to enhance the cloud-side network robustness to perturbed data. Through the sophisticated design, ARDEN can not only preserve privacy but also improve the inference performance. To validate the proposed ARDEN, a series of experiments based on three image datasets and a real mobile application are conducted. The experimental results demonstrate the effectiveness of ARDEN. Finally, we implement ARDEN on a demo system to verify its practicality.
Deep Learning Towards Mobile Applications
Sep 10, 2018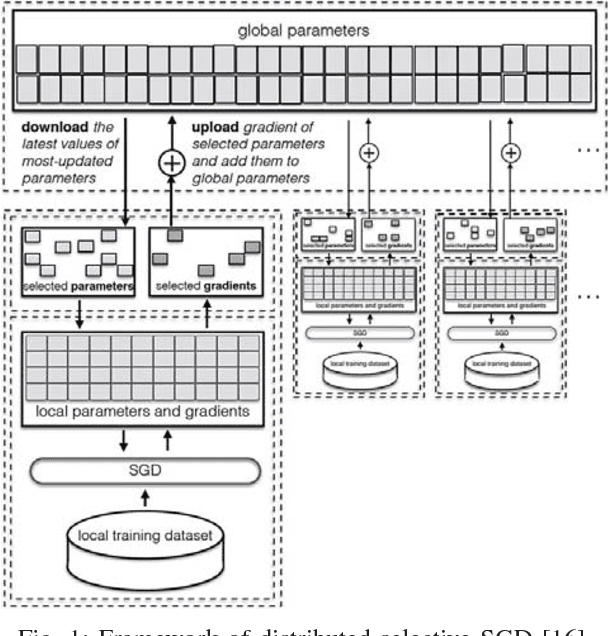
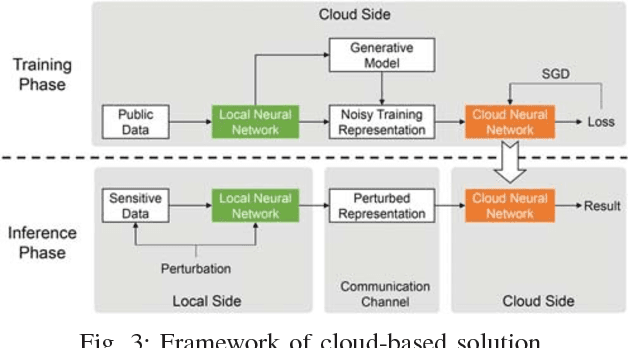
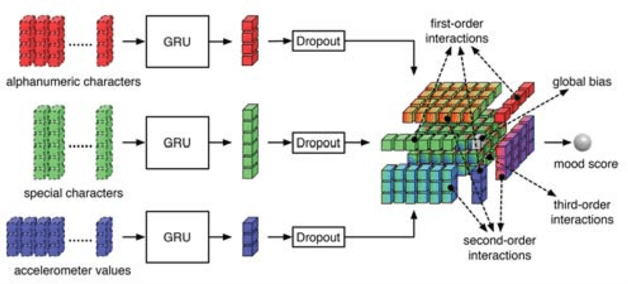
Recent years have witnessed an explosive growth of mobile devices. Mobile devices are permeating every aspect of our daily lives. With the increasing usage of mobile devices and intelligent applications, there is a soaring demand for mobile applications with machine learning services. Inspired by the tremendous success achieved by deep learning in many machine learning tasks, it becomes a natural trend to push deep learning towards mobile applications. However, there exist many challenges to realize deep learning in mobile applications, including the contradiction between the miniature nature of mobile devices and the resource requirement of deep neural networks, the privacy and security concerns about individuals' data, and so on. To resolve these challenges, during the past few years, great leaps have been made in this area. In this paper, we provide an overview of the current challenges and representative achievements about pushing deep learning on mobile devices from three aspects: training with mobile data, efficient inference on mobile devices, and applications of mobile deep learning. The former two aspects cover the primary tasks of deep learning. Then, we go through our two recent applications that apply the data collected by mobile devices to inferring mood disturbance and user identification. Finally, we conclude this paper with the discussion of the future of this area.