 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Relevance Assessment for Web-Scale Search Evaluation at Pinterest
Sep 03, 2025



Relevance evaluation plays a crucial role in personalized search systems to ensure that search results align with a user's queries and intent. While human annotation is the traditional method for relevance evaluation, its high cost and long turnaround time limit its scalability. In this work, we present our approach at Pinterest Search to automate relevance evaluation for online experiments using fine-tuned LLMs. We rigorously validate the alignment between LLM-generated judgments and human annotations, demonstrating that LLMs can provide reliable relevance measurement for experiments while greatly improving the evaluation efficiency. Leveraging LLM-based labeling further unlocks the opportunities to expand the query set, optimize sampling design, and efficiently assess a wider range of search experiences at scale. This approach leads to higher-quality relevance metrics and significantly reduces the Minimum Detectable Effect (MDE) in online experiment measurements.
Aggressive Post-Training Compression on Extremely Large Language Models
Sep 30, 2024The increasing size and complexity of Large Language Models (LLMs) pose challenges for their deployment on personal computers and mobile devices. Aggressive post-training model compression is necessary to reduce the models' size, but it often results in significant accuracy loss. To address this challenge, we propose a novel network pruning technology that utilizes over 0.7 sparsity and less than 8 bits of quantization. Our approach enables the compression of prevailing LLMs within a couple of hours while maintaining a relatively small accuracy loss. In experimental evaluations, our method demonstrates effectiveness and potential for practical deployment. By making LLMs available on domestic devices, our work can facilitate a new era of natural language processing applications with wide-ranging impacts.
Proof of Quality: A Costless Paradigm for Trustless Generative AI Model Inference on Blockchains
May 28, 2024
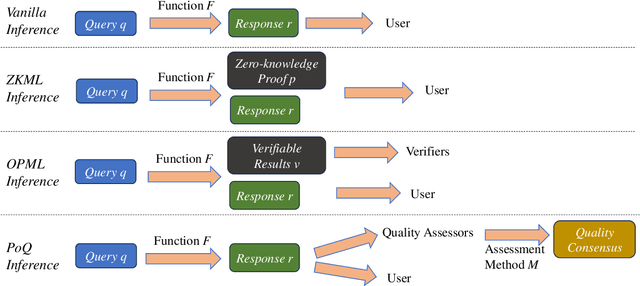


Generative AI models, such as GPT-4 and Stable Diffusion, have demonstrated powerful and disruptive capabilities in natural language and image tasks. However, deploying these models in decentralized environments remains challenging. Unlike traditional centralized deployment, systematically guaranteeing the integrity of AI model services in fully decentralized environments, particularly on trustless blockchains, is both crucial and difficult. In this paper, we present a new inference paradigm called \emph{proof of quality} (PoQ) to enable the deployment of arbitrarily large generative models on blockchain architecture. Unlike traditional approaches based on validating inference procedures, such as ZKML or OPML, our PoQ paradigm focuses on the outcome quality of model inference. Using lightweight BERT-based cross-encoders as our underlying quality evaluation model, we design and implement PQML, the first practical protocol for real-world NLP generative model inference on blockchains, tailored for popular open-source models such as Llama 3 and Mixtral. Our analysis demonstrates that our protocol is robust against adversarial but rational participants in ecosystems, where lazy or dishonest behavior results in fewer benefits compared to well-behaving participants. The computational overhead of validating the quality evaluation is minimal, allowing quality validators to complete the quality check within a second, even using only a CPU. Preliminary simulation results show that PoQ consensus is generated in milliseconds, 1,000 times faster than any existing scheme.
GENET: Unleashing the Power of Side Information for Recommendation via Hypergraph Pre-training
Nov 22, 2023



Recommendation with side information has drawn significant research interest due to its potential to mitigate user feedback sparsity. However, existing models struggle with generalization across diverse domains and types of side information. In particular, three challenges have not been addressed, and they are (1) the diverse formats of side information, including text sequences. (2) The diverse semantics of side information that describes items and users from multi-level in a context different from recommendation systems. (3) The diverse correlations in side information to measure similarity over multiple objects beyond pairwise relations. In this paper, we introduce GENET (Generalized hypErgraph pretraiNing on sidE informaTion), which pre-trains user and item representations on feedback-irrelevant side information and fine-tunes the representations on user feedback data. GENET leverages pre-training as a means to prevent side information from overshadowing critical ID features and feedback signals. It employs a hypergraph framework to accommodate various types of diverse side information. During pre-training, GENET integrates tasks for hyperlink prediction and self-supervised contrast to capture fine-grained semantics at both local and global levels. Additionally, it introduces a unique strategy to enhance pre-training robustness by perturbing positive samples while maintaining high-order relations. Extensive experiments demonstrate that GENET exhibits strong generalization capabilities, outperforming the SOTA method by up to 38% in TOP-N recommendation and Sequential recommendation tasks on various datasets with different side information.
HARL: Hierarchical Adaptive Reinforcement Learning Based Auto Scheduler for Neural Networks
Nov 21, 2022



To efficiently perform inference with neural networks, the underlying tensor programs require sufficient tuning efforts before being deployed into production environments. Usually, enormous tensor program candidates need to be sufficiently explored to find the one with the best performance. This is necessary to make the neural network products meet the high demand of real-world applications such as natural language processing, auto-driving, etc. Auto-schedulers are being developed to avoid the need for human intervention. However, due to the gigantic search space and lack of intelligent search guidance, current auto-schedulers require hours to days of tuning time to find the best-performing tensor program for the entire neural network. In this paper, we propose HARL, a reinforcement learning (RL) based auto-scheduler specifically designed for efficient tensor program exploration. HARL uses a hierarchical RL architecture in which learning-based decisions are made at all different levels of search granularity. It also automatically adjusts exploration configurations in real-time for faster performance convergence. As a result, HARL improves the tensor operator performance by 22% and the search speed by 4.3x compared to the state-of-the-art auto-scheduler. Inference performance and search speed are also significantly improved on end-to-end neural networks.
TransMask: A Compact and Fast Speech Separation Model Based on Transformer
Feb 19, 2021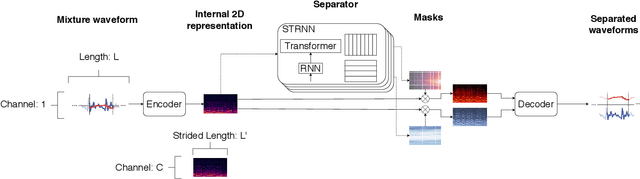
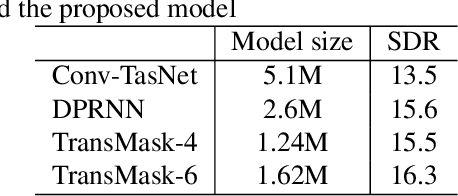
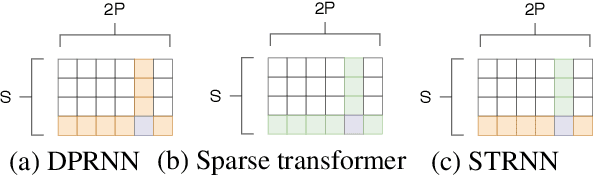
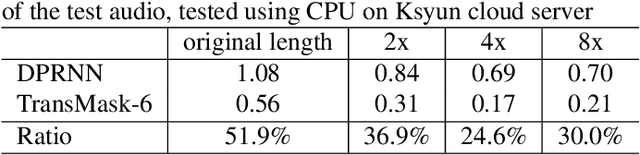
Speech separation is an important problem in speech processing, which targets to separate and generate clean speech from a mixed audio containing speech from different speakers. Empowered by the deep learning technologies over sequence-to-sequence domain, recent neural speech separation models are now capable of generating highly clean speech audios. To make these models more practical by reducing the model size and inference time while maintaining high separation quality, we propose a new transformer-based speech separation approach, called TransMask. By fully un-leashing the power of self-attention on long-term dependency exception, we demonstrate the size of TransMask is more than 60% smaller and the inference is more than 2 times faster than state-of-the-art solutions. TransMask fully utilizes the parallelism during inference, and achieves nearly linear inference time within reasonable input audio lengths. It also outperforms existing solutions on output speech audio quality, achieving SDR above 16 over Librimix benchmark.
Time Series Domain Adaptation via Sparse Associative Structure Alignment
Dec 22, 2020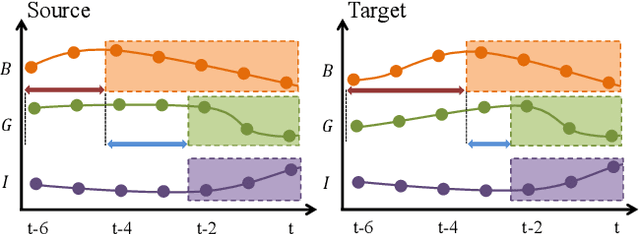

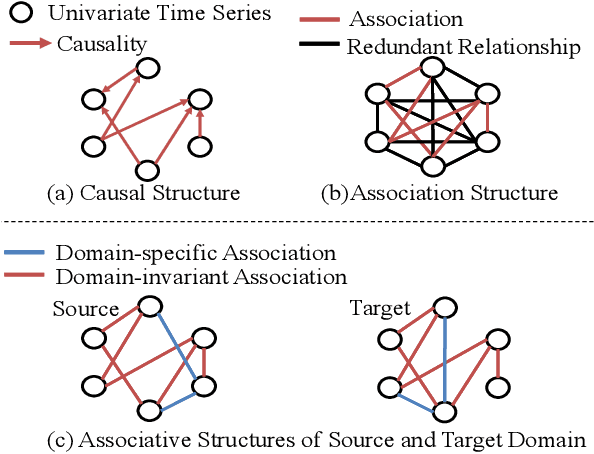

Domain adaptation on time series data is an important but challenging task. Most of the existing works in this area are based on the learning of the domain-invariant representation of the data with the help of restrictions like MMD. However, such extraction of the domain-invariant representation is a non-trivial task for time series data, due to the complex dependence among the timestamps. In detail, in the fully dependent time series, a small change of the time lags or the offsets may lead to difficulty in the domain invariant extraction. Fortunately, the stability of the causality inspired us to explore the domain invariant structure of the data. To reduce the difficulty in the discovery of causal structure, we relax it to the sparse associative structure and propose a novel sparse associative structure alignment model for domain adaptation. First, we generate the segment set to exclude the obstacle of offsets. Second, the intra-variables and inter-variables sparse attention mechanisms are devised to extract associative structure time-series data with considering time lags. Finally, the associative structure alignment is used to guide the transfer of knowledge from the source domain to the target one. Experimental studies not only verify the good performance of our methods on three real-world datasets but also provide some insightful discoveries on the transferred knowledge.
Speech Fusion to Face: Bridging the Gap Between Human's Vocal Characteristics and Facial Imaging
Jun 10, 2020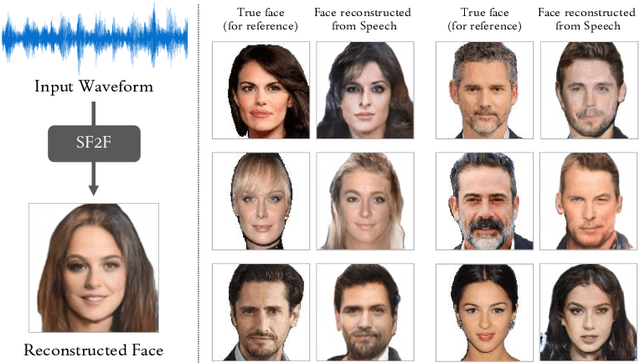
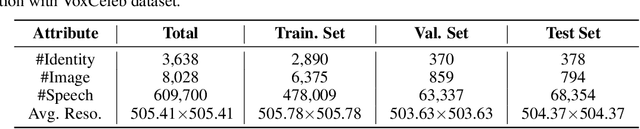
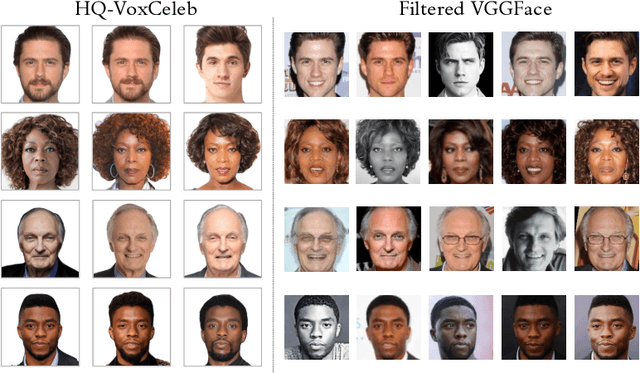

While deep learning technologies are now capable of generating realistic images confusing humans, the research efforts are turning to the synthesis of images for more concrete and application-specific purposes. Facial image generation based on vocal characteristics from speech is one of such important yet challenging tasks. It is the key enabler to influential use cases of image generation, especially for business in public security and entertainment. Existing solutions to the problem of speech2face renders limited image quality and fails to preserve facial similarity due to the lack of quality dataset for training and appropriate integration of vocal features. In this paper, we investigate these key technical challenges and propose Speech Fusion to Face, or SF2F in short, attempting to address the issue of facial image quality and the poor connection between vocal feature domain and modern image generation models. By adopting new strategies on data model and training, we demonstrate dramatic performance boost over state-of-the-art solution, by doubling the recall of individual identity, and lifting the quality score from 15 to 19 based on the mutual information score with VGGFace classifier.
Causal Mechanism Transfer Network for Time Series Domain Adaptation in Mechanical Systems
Oct 13, 2019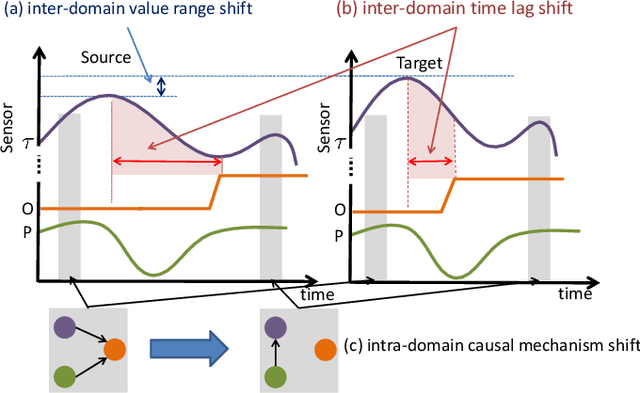
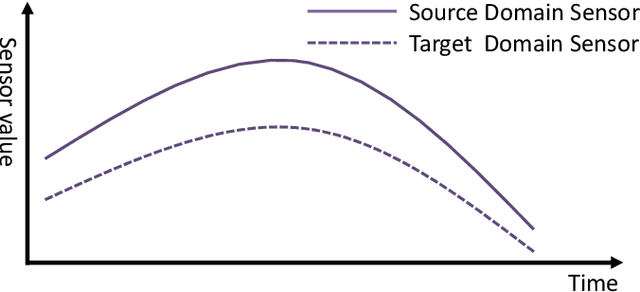
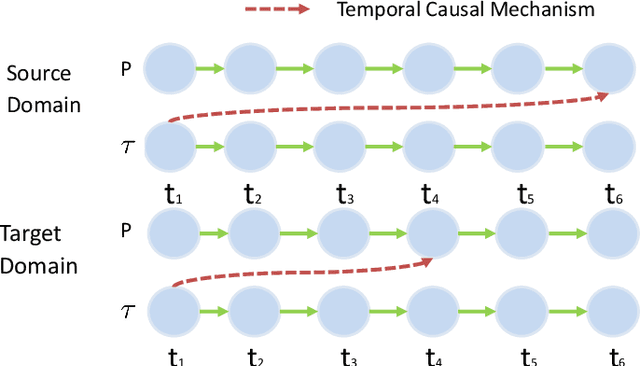
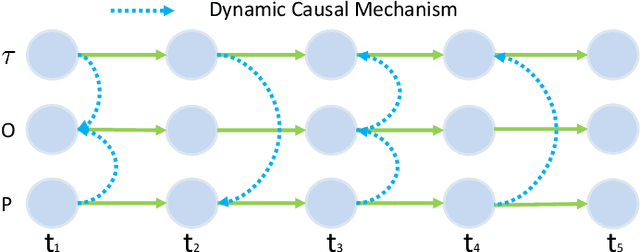
Data-driven models are becoming essential parts in modern mechanical systems, commonly used to capture the behavior of various equipment and varying environmental characteristics. Despite the advantages of these data-driven models on excellent adaptivity to high dynamics and aging equipment, they are usually hungry to massive labels over historical data, mostly contributed by human engineers at an extremely high cost. The label demand is now the major limiting factor to modeling accuracy, hindering the fulfillment of visions for applications. Fortunately, domain adaptation enhances the model generalization by utilizing the labelled source data as well as the unlabelled target data and then we can reuse the model on different domains. However, the mainstream domain adaptation methods cannot achieve ideal performance on time series data, because most of them focus on static samples and even the existing time series domain adaptation methods ignore the properties of time series data, such as temporal causal mechanism. In this paper, we assume that causal mechanism is invariant and present our Causal Mechanism Transfer Network(CMTN) for time series domain adaptation. By capturing and transferring the dynamic and temporal causal mechanism of multivariate time series data and alleviating the time lags and different value ranges among different machines, CMTN allows the data-driven models to exploit existing data and labels from similar systems, such that the resulting model on a new system is highly reliable even with very limited data. We report our empirical results and lessons learned from two real-world case studies, on chiller plant energy optimization and boiler fault detection, which outperforms the existing state-of-the-art method.
Causal Discovery with Cascade Nonlinear Additive Noise Models
Jun 03, 2019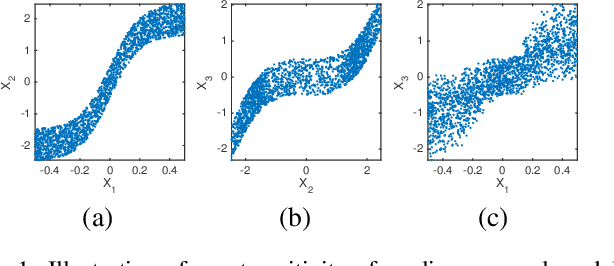
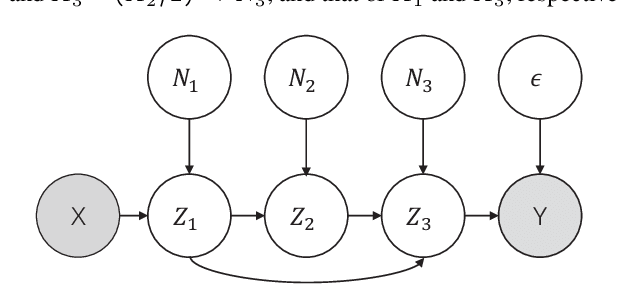
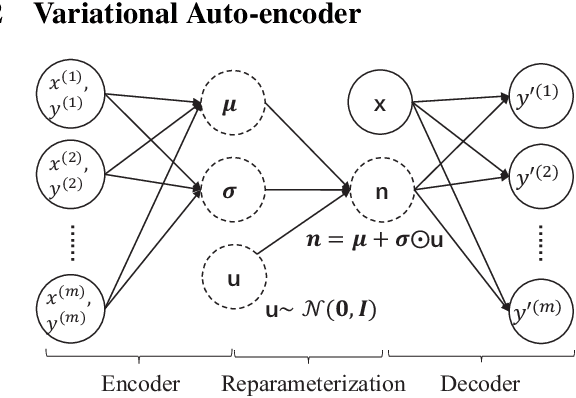
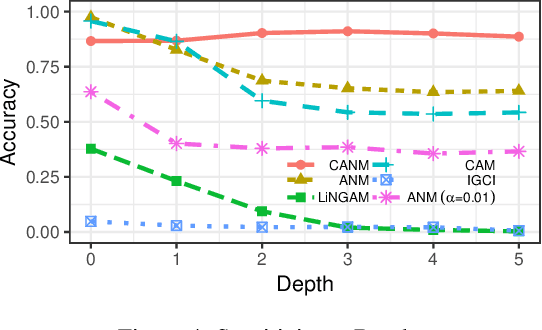
Identification of causal direction between a causal-effect pair from observed data has recently attracted much attention. Various methods based on functional causal models have been proposed to solve this problem, by assuming the causal process satisfies some (structural) constraints and showing that the reverse direction violates such constraints. The nonlinear additive noise model has been demonstrated to be effective for this purpose, but the model class is not transitive--even if each direct causal relation follows this model, indirect causal influences, which result from omitted intermediate causal variables and are frequently encountered in practice, do not necessarily follow the model constraints; as a consequence, the nonlinear additive noise model may fail to correctly discover causal direction. In this work, we propose a cascade nonlinear additive noise model to represent such causal influences--each direct causal relation follows the nonlinear additive noise model but we observe only the initial cause and final effect. We further propose a method to estimate the model, including the unmeasured intermediate variables, from data, under the variational auto-encoder framework. Our theoretical results show that with our model, causal direction is identifiable under suitable technical conditions on the data generation process. Simulation results illustrate the power of the proposed method in identifying indirect causal relations across various settings, and experimental results on real data suggest that the proposed model and method greatly extend the applicability of causal discovery based on functional causal models in nonlinear cases.