 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Power of Unlabeled Data: A Self-supervised Learning Framework for Cyber Attack Detection in Smart Grids
May 22, 2024



Modern power grids are undergoing significant changes driven by information and communication technologies (ICTs), and evolving into smart grids with higher efficiency and lower operation cost. Using ICTs, however, comes with an inevitable side effect that makes the power system more vulnerable to cyber attacks. In this paper, we propose a self-supervised learning-based framework to detect and identify various types of cyber attacks. Different from existing approaches, the proposed framework does not rely on large amounts of well-curated labeled data but makes use of the massive unlabeled data in the wild which are easily accessible. Specifically, the proposed framework adopts the BERT model from the natural language processing domain and learns generalizable and effective representations from the unlabeled sensing data, which capture the distinctive patterns of different attacks. Using the learned representations, together with a very small amount of labeled data, we can train a task-specific classifier to detect various types of cyber attacks. Meanwhile, real-world training datasets are usually imbalanced, i.e., there are only a limited number of data samples containing attacks. In order to cope with such data imbalance, we propose a new loss function, separate mean error (SME), which pays equal attention to the large and small categories to better train the model. Experiment results in a 5-area power grid system with 37 buses demonstrate the superior performance of our framework over existing approaches, especially when a very limited portion of labeled data are available, e.g., as low as 0.002\%. We believe such a framework can be easily adopted to detect a variety of cyber attacks in other power grid scenarios.
YOLO-ReT: Towards High Accuracy Real-time Object Detection on Edge GPUs
Oct 26, 2021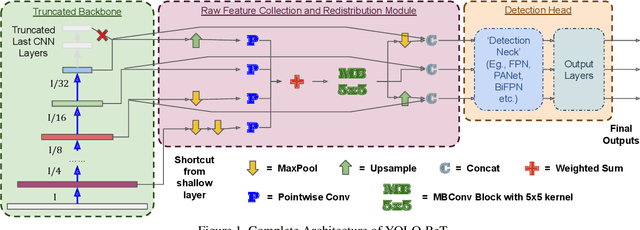
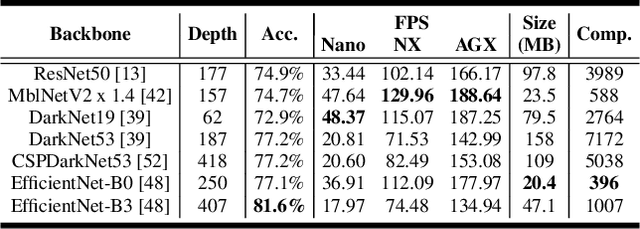
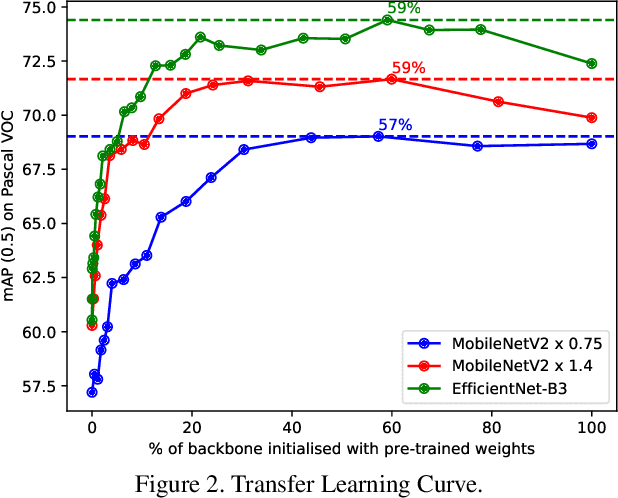
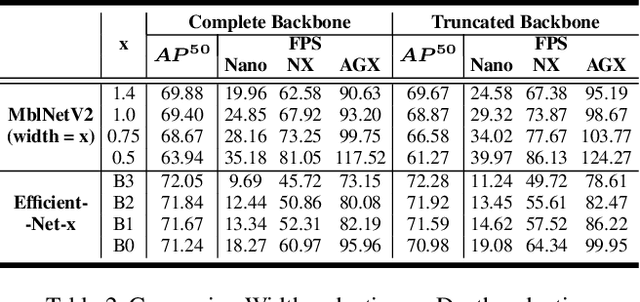
Performance of object detection models has been growing rapidly on two major fronts, model accuracy and efficiency. However, in order to map deep neural network (DNN) based object detection models to edge devices, one typically needs to compress such models significantly, thus compromising the model accuracy. In this paper, we propose a novel edge GPU friendly module for multi-scale feature interaction by exploiting missing combinatorial connections between various feature scales in existing state-of-the-art methods. Additionally, we propose a novel transfer learning backbone adoption inspired by the changing translational information flow across various tasks, designed to complement our feature interaction module and together improve both accuracy as well as execution speed on various edge GPU devices available in the market. For instance, YOLO-ReT with MobileNetV2x0.75 backbone runs real-time on Jetson Nano, and achieves 68.75 mAP on Pascal VOC and 34.91 mAP on COCO, beating its peers by 3.05 mAP and 0.91 mAP respectively, while executing faster by 3.05 FPS. Furthermore, introducing our multi-scale feature interaction module in YOLOv4-tiny and YOLOv4-tiny (3l) improves their performance to 41.5 and 48.1 mAP respectively on COCO, outperforming the original versions by 1.3 and 0.9 mAP.
Compressing Large-Scale Transformer-Based Models: A Case Study on BERT
Feb 27, 2020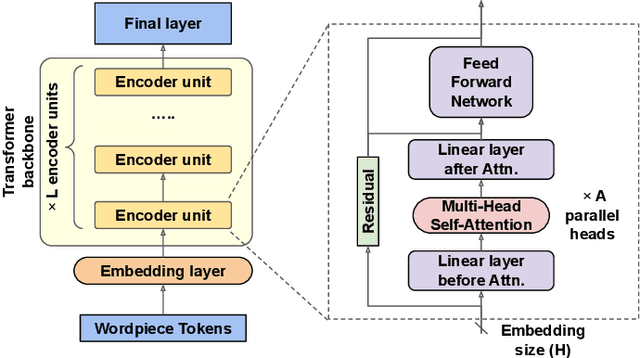
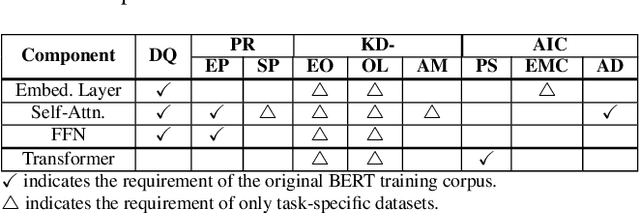
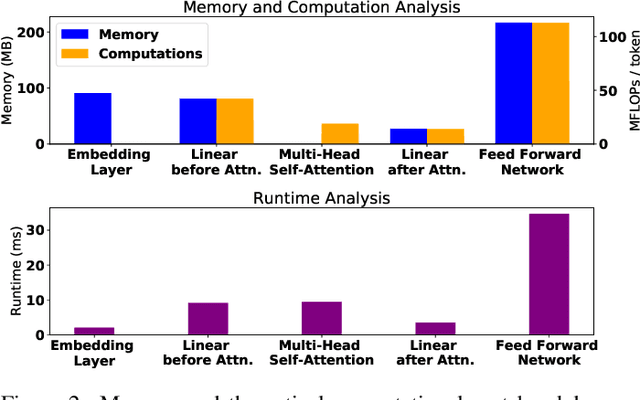
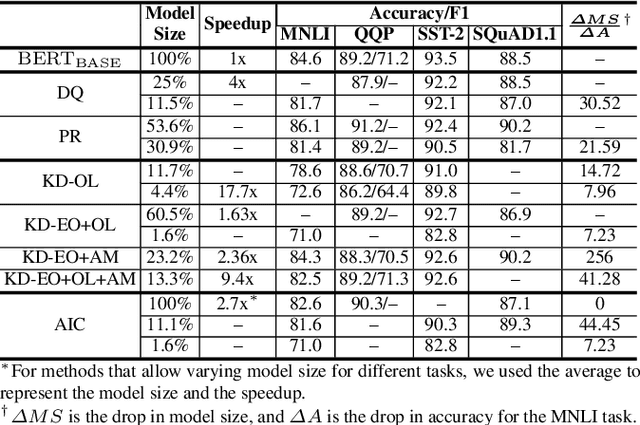
Transformer-based models pre-trained on large-scale corpora achieve state-of-the-art accuracy for natural language processing tasks, but are too resource-hungry and compute-intensive to suit low-capability devices or applications with strict latency requirements. One potential remedy is model compression, which has attracted extensive attention. This paper summarizes the branches of research on compressing Transformers, focusing on the especially popular BERT model. BERT's complex architecture means that a compression technique that is highly effective on one part of the model, e.g., attention layers, may be less successful on another part, e.g., fully connected layers. In this systematic study, we identify the state of the art in compression for each part of BERT, clarify current best practices for compressing large-scale Transformer models, and provide insights into the inner workings of various methods. Our categorization and analysis also shed light on promising future research directions for achieving a lightweight, accurate, and generic natural language processing model.
Causal Mechanism Transfer Network for Time Series Domain Adaptation in Mechanical Systems
Oct 13, 2019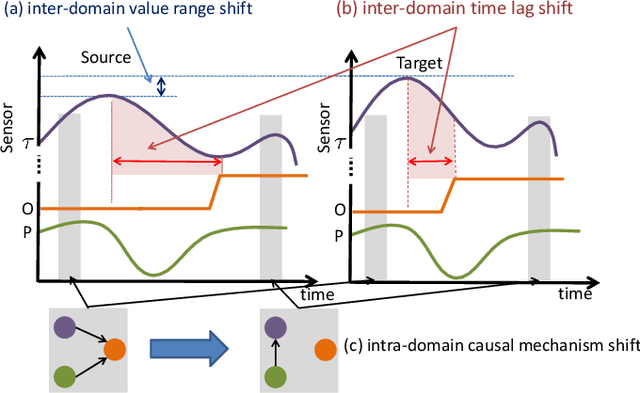
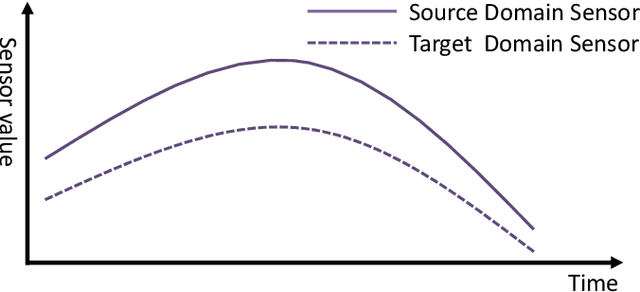
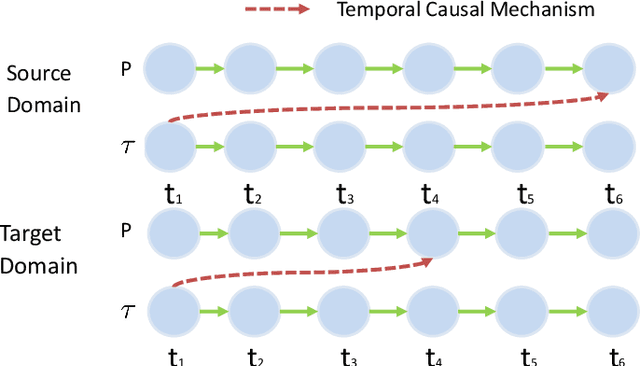
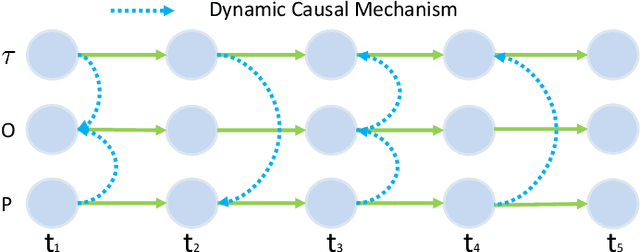
Data-driven models are becoming essential parts in modern mechanical systems, commonly used to capture the behavior of various equipment and varying environmental characteristics. Despite the advantages of these data-driven models on excellent adaptivity to high dynamics and aging equipment, they are usually hungry to massive labels over historical data, mostly contributed by human engineers at an extremely high cost. The label demand is now the major limiting factor to modeling accuracy, hindering the fulfillment of visions for applications. Fortunately, domain adaptation enhances the model generalization by utilizing the labelled source data as well as the unlabelled target data and then we can reuse the model on different domains. However, the mainstream domain adaptation methods cannot achieve ideal performance on time series data, because most of them focus on static samples and even the existing time series domain adaptation methods ignore the properties of time series data, such as temporal causal mechanism. In this paper, we assume that causal mechanism is invariant and present our Causal Mechanism Transfer Network(CMTN) for time series domain adaptation. By capturing and transferring the dynamic and temporal causal mechanism of multivariate time series data and alleviating the time lags and different value ranges among different machines, CMTN allows the data-driven models to exploit existing data and labels from similar systems, such that the resulting model on a new system is highly reliable even with very limited data. We report our empirical results and lessons learned from two real-world case studies, on chiller plant energy optimization and boiler fault detection, which outperforms the existing state-of-the-art method.