 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Large-Scale Transformer-Based Models: A Case Study on BERT
Paper and Code
Feb 27, 2020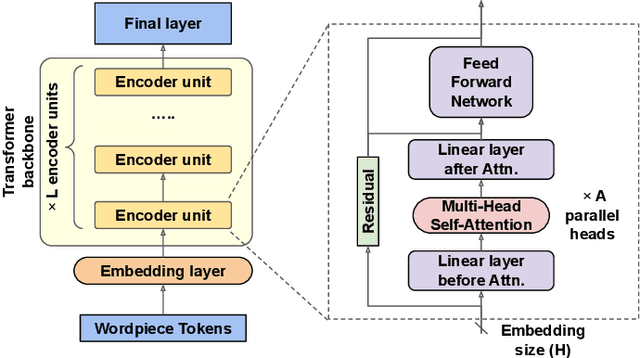
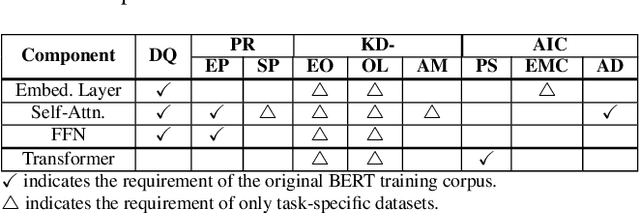
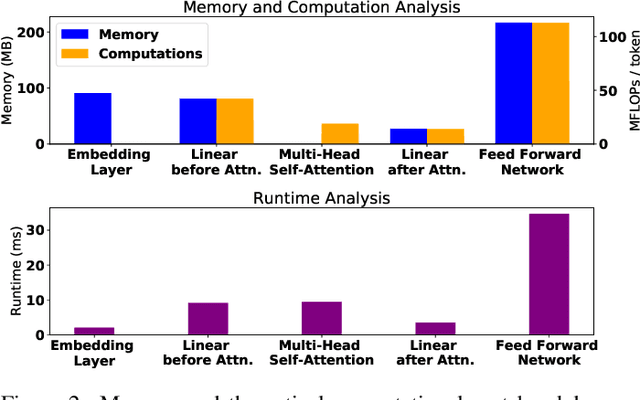
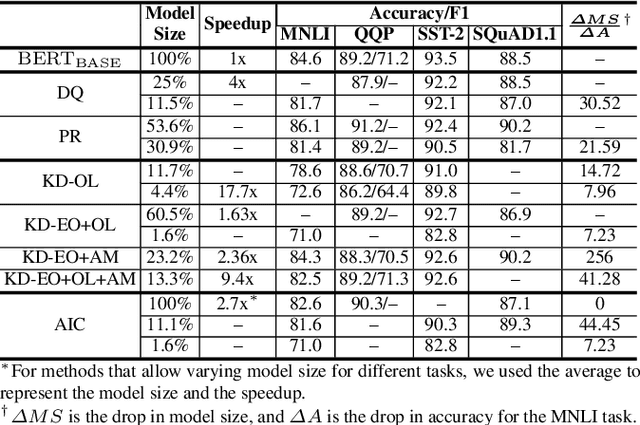
Transformer-based models pre-trained on large-scale corpora achieve state-of-the-art accuracy for natural language processing tasks, but are too resource-hungry and compute-intensive to suit low-capability devices or applications with strict latency requirements. One potential remedy is model compression, which has attracted extensive attention. This paper summarizes the branches of research on compressing Transformers, focusing on the especially popular BERT model. BERT's complex architecture means that a compression technique that is highly effective on one part of the model, e.g., attention layers, may be less successful on another part, e.g., fully connected layers. In this systematic study, we identify the state of the art in compression for each part of BERT, clarify current best practices for compressing large-scale Transformer models, and provide insights into the inner workings of various methods. Our categorization and analysis also shed light on promising future research directions for achieving a lightweight, accurate, and generic natural language processing model.