 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Persistent Effects of Lexicality in Large Language Models
Jun 03, 2026Representations extracted from large language models (LLMs) play an important role in many downstream applications. However, the structure of these representations is often influenced by lexical overlap rather than semantic content. Our understanding of the relationship between this lexical influence and semantic content, and its implications for downstream tasks, remains limited. In this work, we investigate representations to quantify the effect of lexical overlap relative to semantic content. We consider several adversarial semantic stress tests and further connect our findings to the information theory perspective. We find that lexical influence extends across the depth of models, consistently across architectures, training regimes, and objective functions, including the models trained for semantic similarity. Moreover, we observe a mid-depth region in which both lexical and semantic signals degrade simultaneously, indicating a transitional regime where representations are poor for both surface form and meaning. We further demonstrate the effect of lexical influence on downstream uses of LLMs using summarization and model editing as a case study.
LLMs Underperform Graph-Based Parsers on Supervised Relation Extraction for Complex Graphs
Apr 09, 2026Relation extraction represents a fundamental component in the process of creating knowledge graphs, among other applications. Large language models (LLMs) have been adopted as a promising tool for relation extraction, both in supervised and in-context learning settings. However, in this work we show that their performance still lags behind much smaller architectures when the linguistic graph underlying a text has great complexity. To demonstrate this, we evaluate four LLMs against a graph-based parser on six relation extraction datasets with sentence graphs of varying sizes and complexities. Our results show that the graph-based parser increasingly outperforms the LLMs, as the number of relations in the input documents increases. This makes the much lighter graph-based parser a superior choice in the presence of complex linguistic graphs.
LangFIR: Discovering Sparse Language-Specific Features from Monolingual Data for Language Steering
Apr 04, 2026Large language models (LLMs) show strong multilingual capabilities, yet reliably controlling the language of their outputs remains difficult. Representation-level steering addresses this by adding language-specific vectors to model activations at inference time, but identifying language-specific directions in the residual stream often relies on multilingual or parallel data that can be expensive to obtain. Sparse autoencoders (SAEs) decompose residual activations into interpretable, sparse feature directions and offer a natural basis for this search, yet existing SAE-based approaches face the same data constraint. We introduce LangFIR (Language Feature Identification via Random-token Filtering), a method that discovers language-specific SAE features using only a small amount of monolingual data and random-token sequences. Many SAE features consistently activated by target-language inputs do not encode language identity. Random-token sequences surface these language-agnostic features, allowing LangFIR to filter them out and isolate a sparse set of language-specific features. We show that these features are extremely sparse, highly selective for their target language, and causally important: directional ablation increases cross-entropy loss only for the corresponding language. Using these features to construct steering vectors for multilingual generation control, LangFIR achieves the best average accuracy BLEU across three models (Gemma 3 1B, Gemma 3 4B, and Llama 3.1 8B), three datasets, and twelve target languages, outperforming the strongest monolingual baseline by up to and surpassing methods that rely on parallel data. Our results suggest that language identity in multilingual LLMs is localized in a sparse set of feature directions discoverable with monolingual data. Code is available at https://anonymous.4open.science/r/LangFIR-C0F5/.
SCOPE: Selective Conformal Optimized Pairwise LLM Judging
Feb 13, 2026Large language models (LLMs) are increasingly used as judges to replace costly human preference labels in pairwise evaluation. Despite their practicality, LLM judges remain prone to miscalibration and systematic biases. This paper proposes SCOPE (Selective Conformal Optimized Pairwise Evaluation), a framework for selective pairwise judging with finite-sample statistical guarantees. Under exchangeability, SCOPE calibrates an acceptance threshold such that the error rate among non-abstained judgments is at most a user-specified level $α$. To provide SCOPE with a bias-neutral uncertainty signal, we introduce Bidirectional Preference Entropy (BPE), which queries the judge under both response positions, aggregates the implied preference probabilities to enforce invariance to response order, and converts the aggregated probability into an entropy-based uncertainty score. Across MT-Bench, RewardBench, and Chatbot Arena, BPE improves uncertainty quality over standard confidence proxies, providing a stronger selection signal that enables SCOPE to consistently meet the target risk level while retaining good coverage across judge scales. In particular, at $α= 0.10$, \textsc{Scope} consistently satisfies the risk bound across all benchmarks and judge scales (empirical risk $\approx 0.097$ to $0.099$), while retaining substantial coverage, reaching $0.89$ on RewardBench with Qwen-14B and $0.98$ on RewardBench with Qwen-32B. Compared to naïve baselines, \textsc{Scope} accepts up to $2.4\times$ more judgments on MT-Bench with Qwen-7B under the same target risk constraint, demonstrating that BPE enables reliable and high-coverage LLM-based evaluation.
Vector Quantized Latent Concepts: A Scalable Alternative to Clustering-Based Concept Discovery
Feb 02, 2026Deep Learning models encode rich semantic information in their hidden representations. However, it remains challenging to understand which parts of this information models actually rely on when making predictions. A promising line of post-hoc concept-based explanation methods relies on clustering token representations. However, commonly used approaches such as hierarchical clustering are computationally infeasible for large-scale datasets, and K-Means often yields shallow or frequency-dominated clusters. We propose the vector quantized latent concept (VQLC) method, a framework built upon the vector quantized-variational autoencoder (VQ-VAE) architecture that learns a discrete codebook mapping continuous representations to concept vectors. We perform thorough evaluations and show that VQLC improves scalability while maintaining comparable quality of human-understandable explanations.
Multi-Granular Node Pruning for Circuit Discovery
Dec 11, 2025Circuit discovery aims to identify minimal subnetworks that are responsible for specific behaviors in large language models (LLMs). Existing approaches primarily rely on iterative edge pruning, which is computationally expensive and limited to coarse-grained units such as attention heads or MLP blocks, overlooking finer structures like individual neurons. We propose a node-level pruning framework for circuit discovery that addresses both scalability and granularity limitations. Our method introduces learnable masks across multiple levels of granularity, from entire blocks to individual neurons, within a unified optimization objective. Granularity-specific sparsity penalties guide the pruning process, allowing a comprehensive compression in a single fine-tuning run. Empirically, our approach identifies circuits that are smaller in nodes than those discovered by prior methods; moreover, we demonstrate that many neurons deemed important by coarse methods are actually irrelevant, while still maintaining task performance. Furthermore, our method has a significantly lower memory footprint, 5-10x, as it does not require keeping intermediate activations in the memory to work.
Understanding Syntactic Generalization in Structure-inducing Language Models
Aug 11, 2025



Structure-inducing Language Models (SiLM) are trained on a self-supervised language modeling task, and induce a hierarchical sentence representation as a byproduct when processing an input. A wide variety of SiLMs have been proposed. However, these have typically been evaluated on a relatively small scale, and evaluation of these models has systematic gaps and lacks comparability. In this work, we study three different SiLM architectures using both natural language (English) corpora and synthetic bracketing expressions: Structformer (Shen et al., 2021), UDGN (Shen et al., 2022) and GPST (Hu et al., 2024). We compare them with respect to (i) properties of the induced syntactic representations (ii) performance on grammaticality judgment tasks, and (iii) training dynamics. We find that none of the three architectures dominates across all evaluation metrics. However, there are significant differences, in particular with respect to the induced syntactic representations. The Generative Pretrained Structured Transformer (GPST; Hu et al. 2024) performs most consistently across evaluation settings, and outperforms the other models on long-distance dependencies in bracketing expressions. Furthermore, our study shows that small models trained on large amounts of synthetic data provide a useful testbed for evaluating basic model properties.
Dependency Parsing is More Parameter-Efficient with Normalization
May 26, 2025Dependency parsing is the task of inferring natural language structure, often approached by modeling word interactions via attention through biaffine scoring. This mechanism works like self-attention in Transformers, where scores are calculated for every pair of words in a sentence. However, unlike Transformer attention, biaffine scoring does not use normalization prior to taking the softmax of the scores. In this paper, we provide theoretical evidence and empirical results revealing that a lack of normalization necessarily results in overparameterized parser models, where the extra parameters compensate for the sharp softmax outputs produced by high variance inputs to the biaffine scoring function. We argue that biaffine scoring can be made substantially more efficient by performing score normalization. We conduct experiments on six datasets for semantic and syntactic dependency parsing using a one-hop parser. We train N-layer stacked BiLSTMs and evaluate the parser's performance with and without normalizing biaffine scores. Normalizing allows us to beat the state of the art on two datasets, with fewer samples and trainable parameters. Code: https://anonymous.4open.science/r/EfficientSDP-70C1
TALE: A Tool-Augmented Framework for Reference-Free Evaluation of Large Language Models
Apr 10, 2025



As Large Language Models (LLMs) become increasingly integrated into real-world, autonomous applications, relying on static, pre-annotated references for evaluation poses significant challenges in cost, scalability, and completeness. We propose Tool-Augmented LLM Evaluation (TALE), a framework to assess LLM outputs without predetermined ground-truth answers. Unlike conventional metrics that compare to fixed references or depend solely on LLM-as-a-judge knowledge, TALE employs an agent with tool-access capabilities that actively retrieves and synthesizes external evidence. It iteratively generates web queries, collects information, summarizes findings, and refines subsequent searches through reflection. By shifting away from static references, TALE aligns with free-form question-answering tasks common in real-world scenarios. Experimental results on multiple free-form QA benchmarks show that TALE not only outperforms standard reference-based metrics for measuring response accuracy but also achieves substantial to near-perfect agreement with human evaluations. TALE enhances the reliability of LLM evaluations in real-world, dynamic scenarios without relying on static references.
DAFE: LLM-Based Evaluation Through Dynamic Arbitration for Free-Form Question-Answering
Mar 11, 2025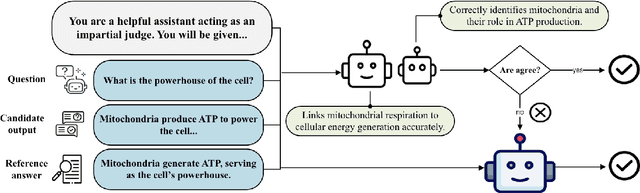



Evaluating Large Language Models (LLMs) free-form generated responses remains a challenge due to their diverse and open-ended nature. Traditional supervised signal-based automatic metrics fail to capture semantic equivalence or handle the variability of open-ended responses, while human evaluation, though reliable, is resource-intensive. Leveraging LLMs as evaluators offers a promising alternative due to their strong language understanding and instruction-following capabilities. Taking advantage of these capabilities, we propose the Dynamic Arbitration Framework for Evaluation (DAFE), which employs two primary LLM-as-judges and engages a third arbitrator only in cases of disagreements. This selective arbitration prioritizes evaluation reliability while reducing unnecessary computational demands compared to conventional majority voting. DAFE utilizes task-specific reference answers with dynamic arbitration to enhance judgment accuracy, resulting in significant improvements in evaluation metrics such as Macro F1 and Cohen's Kappa. Through experiments, including a comprehensive human evaluation, we demonstrate DAFE's ability to provide consistent, scalable, and resource-efficient assessments, establishing it as a robust framework for evaluating free-form model outputs.