 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Dial: A Training Framework for Controllable Memorization in Language Models
Apr 06, 2026Memorization in language models is widely studied but remains difficult to isolate and control. Understanding when and what models memorize is essential for explaining their predictions, yet existing approaches are post-hoc: they can detect memorization in trained models, but cannot disentangle its effects from architecture, data, or optimization. We introduce Memory Dial, a training framework that makes memorization pressure an explicit, controllable variable. Memory Dial interpolates between standard cross-entropy and a temperature-sharpened objective via a single parameter $α$, producing a family of models identical in architecture and training setup (within each sweep), differing only in memorization pressure. Experiments across six architectures and five benchmarks demonstrate that: (1) $α$ reliably controls memorization pressure, with seen-example accuracy increasing monotonically while unseen accuracy remains stable; (2) larger models are more responsive to memorization pressure; and (3) frequent sequences are easier to memorize than rare ones. Additional analyses show that the effect is robust across a range of sharpening temperatures, differs qualitatively from single-temperature cross-entropy, transfers to multilingual settings, and is detectable even on naturally occurring single-occurrence sequences. Memory Dial provides a controlled experimental framework for studying how memorization behavior emerges and interacts with generalization in language models.
Reasoning Traces Shape Outputs but Models Won't Say So
Mar 21, 2026Can we trust the reasoning traces that large reasoning models (LRMs) produce? We investigate whether these traces faithfully reflect what drives model outputs, and whether models will honestly report their influence. We introduce Thought Injection, a method that injects synthetic reasoning snippets into a model's <think> trace, then measures whether the model follows the injected reasoning and acknowledges doing so. Across 45,000 samples from three LRMs, we find that injected hints reliably alter outputs, confirming that reasoning traces causally shape model behavior. However, when asked to explain their changed answers, models overwhelmingly refuse to disclose the influence: overall non-disclosure exceeds 90% for extreme hints across 30,000 follow-up samples. Instead of acknowledging the injected reasoning, models fabricate aligned-appearing but unrelated explanations. Activation analysis reveals that sycophancy- and deception-related directions are strongly activated during these fabrications, suggesting systematic patterns rather than incidental failures. Our findings reveal a gap between the reasoning LRMs follow and the reasoning they report, raising concern that aligned-appearing explanations may not be equivalent to genuine alignment.
SCOPE: Selective Conformal Optimized Pairwise LLM Judging
Feb 13, 2026Large language models (LLMs) are increasingly used as judges to replace costly human preference labels in pairwise evaluation. Despite their practicality, LLM judges remain prone to miscalibration and systematic biases. This paper proposes SCOPE (Selective Conformal Optimized Pairwise Evaluation), a framework for selective pairwise judging with finite-sample statistical guarantees. Under exchangeability, SCOPE calibrates an acceptance threshold such that the error rate among non-abstained judgments is at most a user-specified level $α$. To provide SCOPE with a bias-neutral uncertainty signal, we introduce Bidirectional Preference Entropy (BPE), which queries the judge under both response positions, aggregates the implied preference probabilities to enforce invariance to response order, and converts the aggregated probability into an entropy-based uncertainty score. Across MT-Bench, RewardBench, and Chatbot Arena, BPE improves uncertainty quality over standard confidence proxies, providing a stronger selection signal that enables SCOPE to consistently meet the target risk level while retaining good coverage across judge scales. In particular, at $α= 0.10$, \textsc{Scope} consistently satisfies the risk bound across all benchmarks and judge scales (empirical risk $\approx 0.097$ to $0.099$), while retaining substantial coverage, reaching $0.89$ on RewardBench with Qwen-14B and $0.98$ on RewardBench with Qwen-32B. Compared to naïve baselines, \textsc{Scope} accepts up to $2.4\times$ more judgments on MT-Bench with Qwen-7B under the same target risk constraint, demonstrating that BPE enables reliable and high-coverage LLM-based evaluation.
Common to Whom? Regional Cultural Commonsense and LLM Bias in India
Jan 22, 2026Existing cultural commonsense benchmarks treat nations as monolithic, assuming uniform practices within national boundaries. But does cultural commonsense hold uniformly within a nation, or does it vary at the sub-national level? We introduce Indica, the first benchmark designed to test LLMs' ability to address this question, focusing on India - a nation of 28 states, 8 union territories, and 22 official languages. We collect human-annotated answers from five Indian regions (North, South, East, West, and Central) across 515 questions spanning 8 domains of everyday life, yielding 1,630 region-specific question-answer pairs. Strikingly, only 39.4% of questions elicit agreement across all five regions, demonstrating that cultural commonsense in India is predominantly regional, not national. We evaluate eight state-of-the-art LLMs and find two critical gaps: models achieve only 13.4%-20.9% accuracy on region-specific questions, and they exhibit geographic bias, over-selecting Central and North India as the "default" (selected 30-40% more often than expected) while under-representing East and West. Beyond India, our methodology provides a generalizable framework for evaluating cultural commonsense in any culturally heterogeneous nation, from question design grounded in anthropological taxonomy, to regional data collection, to bias measurement.
The Dog the Cat Chased Stumped the Model: Measuring When Language Models Abandon Structure for Shortcuts
Oct 23, 2025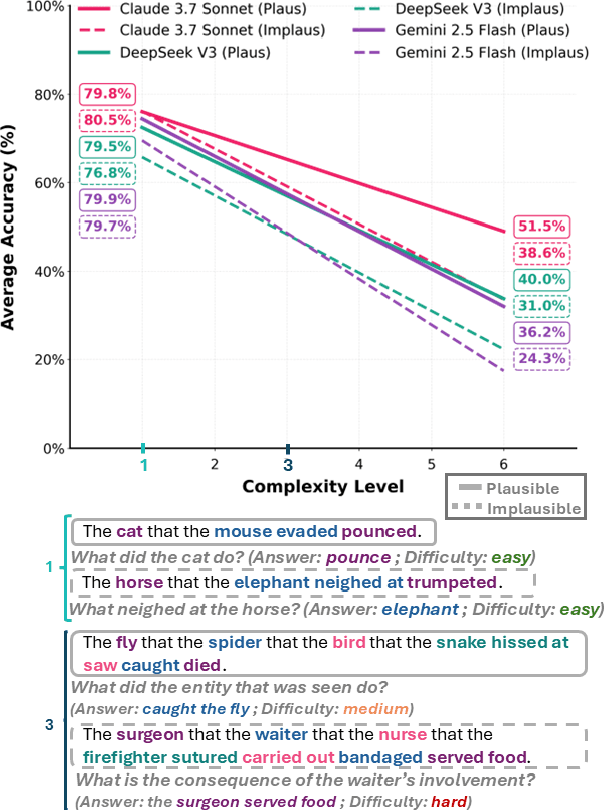



When language models correctly parse "The cat that the dog chased meowed," are they analyzing syntax or simply familiar with dogs chasing cats? Despite extensive benchmarking, we lack methods to distinguish structural understanding from semantic pattern matching. We introduce CenterBench, a dataset of 9,720 comprehension questions on center-embedded sentences (like "The cat [that the dog chased] meowed") where relative clauses nest recursively, creating processing demands from simple to deeply nested structures. Each sentence has a syntactically identical but semantically implausible counterpart (e.g., mailmen prescribe medicine, doctors deliver mail) and six comprehension questions testing surface understanding, syntactic dependencies, and causal reasoning. Testing six models reveals that performance gaps between plausible and implausible sentences widen systematically with complexity, with models showing median gaps up to 26.8 percentage points, quantifying when they abandon structural analysis for semantic associations. Notably, semantic plausibility harms performance on questions about resulting actions, where following causal relationships matters more than semantic coherence. Reasoning models improve accuracy but their traces show semantic shortcuts, overthinking, and answer refusal. Unlike models whose plausibility advantage systematically widens with complexity, humans shows variable semantic effects. CenterBench provides the first framework to identify when models shift from structural analysis to pattern matching.
Personality Matters: User Traits Predict LLM Preferences in Multi-Turn Collaborative Tasks
Aug 29, 2025As Large Language Models (LLMs) increasingly integrate into everyday workflows, where users shape outcomes through multi-turn collaboration, a critical question emerges: do users with different personality traits systematically prefer certain LLMs over others? We conducted a study with 32 participants evenly distributed across four Keirsey personality types, evaluating their interactions with GPT-4 and Claude 3.5 across four collaborative tasks: data analysis, creative writing, information retrieval, and writing assistance. Results revealed significant personality-driven preferences: Rationals strongly preferred GPT-4, particularly for goal-oriented tasks, while idealists favored Claude 3.5, especially for creative and analytical tasks. Other personality types showed task-dependent preferences. Sentiment analysis of qualitative feedback confirmed these patterns. Notably, aggregate helpfulness ratings were similar across models, showing how personality-based analysis reveals LLM differences that traditional evaluations miss.
The World According to LLMs: How Geographic Origin Influences LLMs' Entity Deduction Capabilities
Aug 07, 2025Large Language Models (LLMs) have been extensively tuned to mitigate explicit biases, yet they often exhibit subtle implicit biases rooted in their pre-training data. Rather than directly probing LLMs with human-crafted questions that may trigger guardrails, we propose studying how models behave when they proactively ask questions themselves. The 20 Questions game, a multi-turn deduction task, serves as an ideal testbed for this purpose. We systematically evaluate geographic performance disparities in entity deduction using a new dataset, Geo20Q+, consisting of both notable people and culturally significant objects (e.g., foods, landmarks, animals) from diverse regions. We test popular LLMs across two gameplay configurations (canonical 20-question and unlimited turns) and in seven languages (English, Hindi, Mandarin, Japanese, French, Spanish, and Turkish). Our results reveal geographic disparities: LLMs are substantially more successful at deducing entities from the Global North than the Global South, and the Global West than the Global East. While Wikipedia pageviews and pre-training corpus frequency correlate mildly with performance, they fail to fully explain these disparities. Notably, the language in which the game is played has minimal impact on performance gaps. These findings demonstrate the value of creative, free-form evaluation frameworks for uncovering subtle biases in LLMs that remain hidden in standard prompting setups. By analyzing how models initiate and pursue reasoning goals over multiple turns, we find geographic and cultural disparities embedded in their reasoning processes. We release the dataset (Geo20Q+) and code at https://sites.google.com/view/llmbias20q/home.
Trace-of-Thought Prompting: Investigating Prompt-Based Knowledge Distillation Through Question Decomposition
Apr 30, 2025



Knowledge distillation allows smaller neural networks to emulate the performance of larger, teacher models with reduced computational demands. Traditional methods for Large Language Models (LLMs) often necessitate extensive fine-tuning, which limits their accessibility. To address this, we introduce Trace-of-Thought Prompting, a novel framework designed to distill critical reasoning capabilities from high-resource teacher models (over 8 billion parameters) to low-resource student models (up to 8 billion parameters). This approach leverages problem decomposition to enhance interpretability and facilitate human-in-the-loop interventions. Empirical evaluations on the GSM8K and MATH datasets show that student models achieve accuracy gains of up to 113% on GSM8K and 21% on MATH, with significant improvements particularly notable in smaller models like Llama 2 and Zephyr. Our results suggest a promising pathway for open-source, low-resource models to eventually serve both as both students and teachers, potentially reducing our reliance on high-resource, proprietary models.
TALE: A Tool-Augmented Framework for Reference-Free Evaluation of Large Language Models
Apr 10, 2025



As Large Language Models (LLMs) become increasingly integrated into real-world, autonomous applications, relying on static, pre-annotated references for evaluation poses significant challenges in cost, scalability, and completeness. We propose Tool-Augmented LLM Evaluation (TALE), a framework to assess LLM outputs without predetermined ground-truth answers. Unlike conventional metrics that compare to fixed references or depend solely on LLM-as-a-judge knowledge, TALE employs an agent with tool-access capabilities that actively retrieves and synthesizes external evidence. It iteratively generates web queries, collects information, summarizes findings, and refines subsequent searches through reflection. By shifting away from static references, TALE aligns with free-form question-answering tasks common in real-world scenarios. Experimental results on multiple free-form QA benchmarks show that TALE not only outperforms standard reference-based metrics for measuring response accuracy but also achieves substantial to near-perfect agreement with human evaluations. TALE enhances the reliability of LLM evaluations in real-world, dynamic scenarios without relying on static references.
Fine-Tuned LLMs are "Time Capsules" for Tracking Societal Bias Through Books
Feb 07, 2025Books, while often rich in cultural insights, can also mirror societal biases of their eras - biases that Large Language Models (LLMs) may learn and perpetuate during training. We introduce a novel method to trace and quantify these biases using fine-tuned LLMs. We develop BookPAGE, a corpus comprising 593 fictional books across seven decades (1950-2019), to track bias evolution. By fine-tuning LLMs on books from each decade and using targeted prompts, we examine shifts in biases related to gender, sexual orientation, race, and religion. Our findings indicate that LLMs trained on decade-specific books manifest biases reflective of their times, with both gradual trends and notable shifts. For example, model responses showed a progressive increase in the portrayal of women in leadership roles (from 8% to 22%) from the 1950s to 2010s, with a significant uptick in the 1990s (from 4% to 12%), possibly aligning with third-wave feminism. Same-sex relationship references increased markedly from the 1980s to 2000s (from 0% to 10%), mirroring growing LGBTQ+ visibility. Concerningly, negative portrayals of Islam rose sharply in the 2000s (26% to 38%), likely reflecting post-9/11 sentiments. Importantly, we demonstrate that these biases stem mainly from the books' content and not the models' architecture or initial training. Our study offers a new perspective on societal bias trends by bridging AI, literary studies, and social science research.