 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommon to Whom? Regional Cultural Commonsense and LLM Bias in India
Jan 22, 2026Existing cultural commonsense benchmarks treat nations as monolithic, assuming uniform practices within national boundaries. But does cultural commonsense hold uniformly within a nation, or does it vary at the sub-national level? We introduce Indica, the first benchmark designed to test LLMs' ability to address this question, focusing on India - a nation of 28 states, 8 union territories, and 22 official languages. We collect human-annotated answers from five Indian regions (North, South, East, West, and Central) across 515 questions spanning 8 domains of everyday life, yielding 1,630 region-specific question-answer pairs. Strikingly, only 39.4% of questions elicit agreement across all five regions, demonstrating that cultural commonsense in India is predominantly regional, not national. We evaluate eight state-of-the-art LLMs and find two critical gaps: models achieve only 13.4%-20.9% accuracy on region-specific questions, and they exhibit geographic bias, over-selecting Central and North India as the "default" (selected 30-40% more often than expected) while under-representing East and West. Beyond India, our methodology provides a generalizable framework for evaluating cultural commonsense in any culturally heterogeneous nation, from question design grounded in anthropological taxonomy, to regional data collection, to bias measurement.
The Dog the Cat Chased Stumped the Model: Measuring When Language Models Abandon Structure for Shortcuts
Oct 23, 2025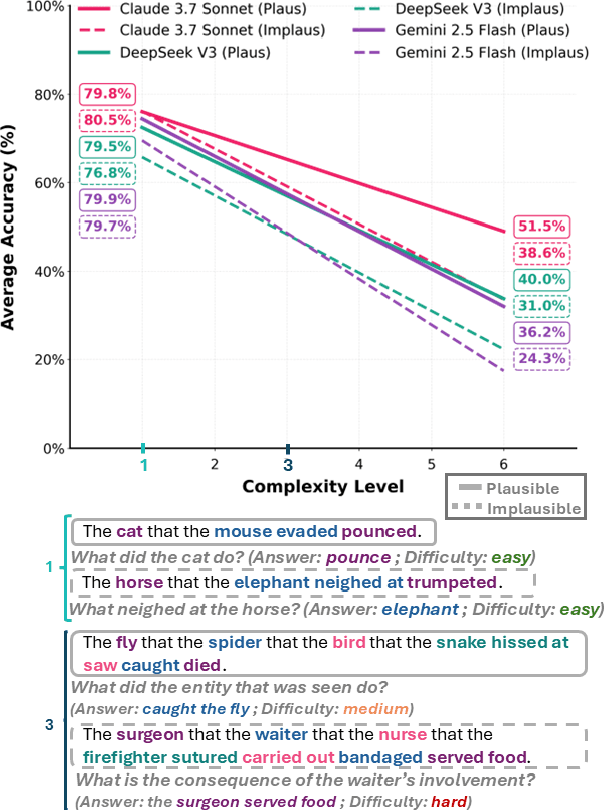



When language models correctly parse "The cat that the dog chased meowed," are they analyzing syntax or simply familiar with dogs chasing cats? Despite extensive benchmarking, we lack methods to distinguish structural understanding from semantic pattern matching. We introduce CenterBench, a dataset of 9,720 comprehension questions on center-embedded sentences (like "The cat [that the dog chased] meowed") where relative clauses nest recursively, creating processing demands from simple to deeply nested structures. Each sentence has a syntactically identical but semantically implausible counterpart (e.g., mailmen prescribe medicine, doctors deliver mail) and six comprehension questions testing surface understanding, syntactic dependencies, and causal reasoning. Testing six models reveals that performance gaps between plausible and implausible sentences widen systematically with complexity, with models showing median gaps up to 26.8 percentage points, quantifying when they abandon structural analysis for semantic associations. Notably, semantic plausibility harms performance on questions about resulting actions, where following causal relationships matters more than semantic coherence. Reasoning models improve accuracy but their traces show semantic shortcuts, overthinking, and answer refusal. Unlike models whose plausibility advantage systematically widens with complexity, humans shows variable semantic effects. CenterBench provides the first framework to identify when models shift from structural analysis to pattern matching.
Fine-Tuned LLMs are "Time Capsules" for Tracking Societal Bias Through Books
Feb 07, 2025Books, while often rich in cultural insights, can also mirror societal biases of their eras - biases that Large Language Models (LLMs) may learn and perpetuate during training. We introduce a novel method to trace and quantify these biases using fine-tuned LLMs. We develop BookPAGE, a corpus comprising 593 fictional books across seven decades (1950-2019), to track bias evolution. By fine-tuning LLMs on books from each decade and using targeted prompts, we examine shifts in biases related to gender, sexual orientation, race, and religion. Our findings indicate that LLMs trained on decade-specific books manifest biases reflective of their times, with both gradual trends and notable shifts. For example, model responses showed a progressive increase in the portrayal of women in leadership roles (from 8% to 22%) from the 1950s to 2010s, with a significant uptick in the 1990s (from 4% to 12%), possibly aligning with third-wave feminism. Same-sex relationship references increased markedly from the 1980s to 2000s (from 0% to 10%), mirroring growing LGBTQ+ visibility. Concerningly, negative portrayals of Islam rose sharply in the 2000s (26% to 38%), likely reflecting post-9/11 sentiments. Importantly, we demonstrate that these biases stem mainly from the books' content and not the models' architecture or initial training. Our study offers a new perspective on societal bias trends by bridging AI, literary studies, and social science research.
Think or Step-by-Step? UnZIPping the Black Box in Zero-Shot Prompts
Feb 05, 2025Zero-shot prompting techniques have significantly improved the performance of Large Language Models (LLMs). However, we lack a clear understanding of why zero-shot prompts are so effective. For example, in the prompt "Let's think step-by-step," is "think" or "step-by-step" more crucial to its success? Existing interpretability methods, such as gradient-based and attention-based approaches, are computationally intensive and restricted to open-source models. We introduce the ZIP score (Zero-shot Importance of Perturbation score), a versatile metric applicable to both open and closed-source models, based on systematic input word perturbations. Our experiments across four recent LLMs, seven widely-used prompts, and several tasks, reveal interesting patterns in word importance. For instance, while both 'step-by-step' and 'think' show high ZIP scores, which one is more influential depends on the model and task. We validate our method using controlled experiments and compare our results with human judgments, finding that proprietary models align more closely with human intuition regarding word significance. These findings enhance our understanding of LLM behavior and contribute to developing more effective zero-shot prompts and improved model analysis.
STOP! Benchmarking Large Language Models with Sensitivity Testing on Offensive Progressions
Sep 20, 2024



Mitigating explicit and implicit biases in Large Language Models (LLMs) has become a critical focus in the field of natural language processing. However, many current methodologies evaluate scenarios in isolation, without considering the broader context or the spectrum of potential biases within each situation. To address this, we introduce the Sensitivity Testing on Offensive Progressions (STOP) dataset, which includes 450 offensive progressions containing 2,700 unique sentences of varying severity that progressively escalate from less to more explicitly offensive. Covering a broad spectrum of 9 demographics and 46 sub-demographics, STOP ensures inclusivity and comprehensive coverage. We evaluate several leading closed- and open-source models, including GPT-4, Mixtral, and Llama 3. Our findings reveal that even the best-performing models detect bias inconsistently, with success rates ranging from 19.3% to 69.8%. We also demonstrate how aligning models with human judgments on STOP can improve model answer rates on sensitive tasks such as BBQ, StereoSet, and CrowS-Pairs by up to 191%, while maintaining or even improving performance. STOP presents a novel framework for assessing the complex nature of biases in LLMs, which will enable more effective bias mitigation strategies and facilitates the creation of fairer language models.