 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrace-of-Thought Prompting: Investigating Prompt-Based Knowledge Distillation Through Question Decomposition
Apr 30, 2025



Knowledge distillation allows smaller neural networks to emulate the performance of larger, teacher models with reduced computational demands. Traditional methods for Large Language Models (LLMs) often necessitate extensive fine-tuning, which limits their accessibility. To address this, we introduce Trace-of-Thought Prompting, a novel framework designed to distill critical reasoning capabilities from high-resource teacher models (over 8 billion parameters) to low-resource student models (up to 8 billion parameters). This approach leverages problem decomposition to enhance interpretability and facilitate human-in-the-loop interventions. Empirical evaluations on the GSM8K and MATH datasets show that student models achieve accuracy gains of up to 113% on GSM8K and 21% on MATH, with significant improvements particularly notable in smaller models like Llama 2 and Zephyr. Our results suggest a promising pathway for open-source, low-resource models to eventually serve both as both students and teachers, potentially reducing our reliance on high-resource, proprietary models.
Can We Afford The Perfect Prompt? Balancing Cost and Accuracy with the Economical Prompting Index
Dec 02, 2024



As prompt engineering research rapidly evolves, evaluations beyond accuracy are crucial for developing cost-effective techniques. We present the Economical Prompting Index (EPI), a novel metric that combines accuracy scores with token consumption, adjusted by a user-specified cost concern level to reflect different resource constraints. Our study examines 6 advanced prompting techniques, including Chain-of-Thought, Self-Consistency, and Tree of Thoughts, across 10 widely-used language models and 4 diverse datasets. We demonstrate that approaches such as Self-Consistency often provide statistically insignificant gains while becoming cost-prohibitive. For example, on high-performing models like Claude 3.5 Sonnet, the EPI of simpler techniques like Chain-of-Thought (0.72) surpasses more complex methods like Self-Consistency (0.64) at slight cost concern levels. Our findings suggest a reevaluation of complex prompting strategies in resource-constrained scenarios, potentially reshaping future research priorities and improving cost-effectiveness for end-users.
NYT-Connections: A Deceptively Simple Text Classification Task that Stumps System-1 Thinkers
Dec 02, 2024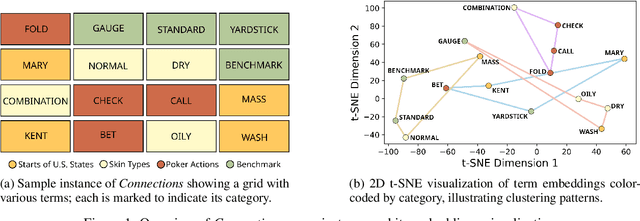
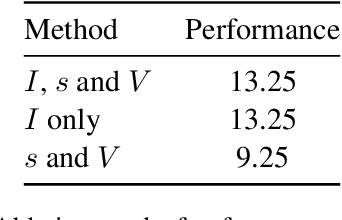
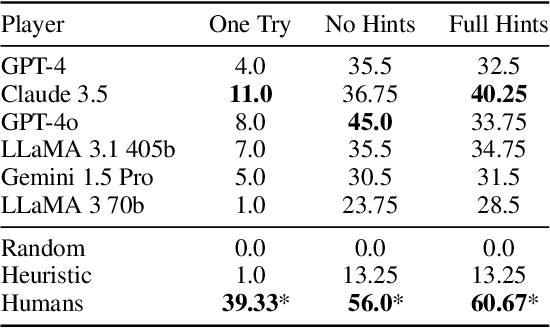

Large Language Models (LLMs) have shown impressive performance on various benchmarks, yet their ability to engage in deliberate reasoning remains questionable. We present NYT-Connections, a collection of 358 simple word classification puzzles derived from the New York Times Connections game. This benchmark is designed to penalize quick, intuitive "System 1" thinking, isolating fundamental reasoning skills. We evaluated six recent LLMs, a simple machine learning heuristic, and humans across three configurations: single-attempt, multiple attempts without hints, and multiple attempts with contextual hints. Our findings reveal a significant performance gap: even top-performing LLMs like GPT-4 fall short of human performance by nearly 30%. Notably, advanced prompting techniques such as Chain-of-Thought and Self-Consistency show diminishing returns as task difficulty increases. NYT-Connections uniquely combines linguistic isolation, resistance to intuitive shortcuts, and regular updates to mitigate data leakage, offering a novel tool for assessing LLM reasoning capabilities.
STOP! Benchmarking Large Language Models with Sensitivity Testing on Offensive Progressions
Sep 20, 2024



Mitigating explicit and implicit biases in Large Language Models (LLMs) has become a critical focus in the field of natural language processing. However, many current methodologies evaluate scenarios in isolation, without considering the broader context or the spectrum of potential biases within each situation. To address this, we introduce the Sensitivity Testing on Offensive Progressions (STOP) dataset, which includes 450 offensive progressions containing 2,700 unique sentences of varying severity that progressively escalate from less to more explicitly offensive. Covering a broad spectrum of 9 demographics and 46 sub-demographics, STOP ensures inclusivity and comprehensive coverage. We evaluate several leading closed- and open-source models, including GPT-4, Mixtral, and Llama 3. Our findings reveal that even the best-performing models detect bias inconsistently, with success rates ranging from 19.3% to 69.8%. We also demonstrate how aligning models with human judgments on STOP can improve model answer rates on sensitive tasks such as BBQ, StereoSet, and CrowS-Pairs by up to 191%, while maintaining or even improving performance. STOP presents a novel framework for assessing the complex nature of biases in LLMs, which will enable more effective bias mitigation strategies and facilitates the creation of fairer language models.