 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity of Generative VLMs to Semantically and Lexically Altered Prompts
Oct 16, 2024

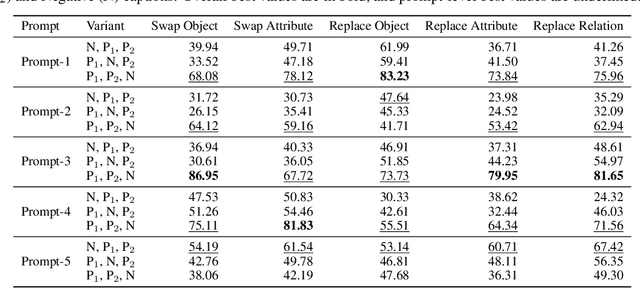
Despite the significant influx of prompt-tuning techniques for generative vision-language models (VLMs), it remains unclear how sensitive these models are to lexical and semantic alterations in prompts. In this paper, we evaluate the ability of generative VLMs to understand lexical and semantic changes in text using the SugarCrepe++ dataset. We analyze the sensitivity of VLMs to lexical alterations in prompts without corresponding semantic changes. Our findings demonstrate that generative VLMs are highly sensitive to such alterations. Additionally, we show that this vulnerability affects the performance of techniques aimed at achieving consistency in their outputs.
SUGARCREPE++ Dataset: Vision-Language Model Sensitivity to Semantic and Lexical Alterations
Jun 17, 2024

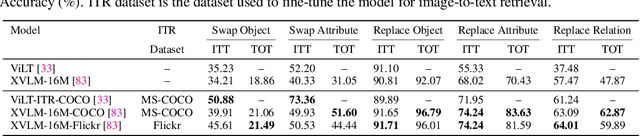

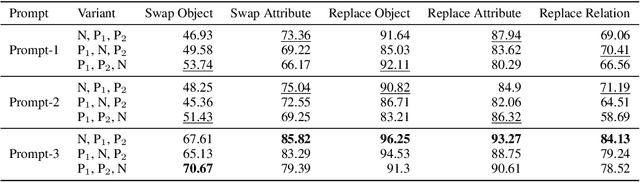
Despite their remarkable successes, state-of-the-art large language models (LLMs), including vision-and-language models (VLMs) and unimodal language models (ULMs), fail to understand precise semantics. For example, semantically equivalent sentences expressed using different lexical compositions elicit diverging representations. The degree of this divergence and its impact on encoded semantics is not very well understood. In this paper, we introduce the SUGARCREPE++ dataset to analyze the sensitivity of VLMs and ULMs to lexical and semantic alterations. Each sample in SUGARCREPE++ dataset consists of an image and a corresponding triplet of captions: a pair of semantically equivalent but lexically different positive captions and one hard negative caption. This poses a 3-way semantic (in)equivalence problem to the language models. We comprehensively evaluate VLMs and ULMs that differ in architecture, pre-training objectives and datasets to benchmark the performance of SUGARCREPE++ dataset. Experimental results highlight the difficulties of VLMs in distinguishing between lexical and semantic variations, particularly in object attributes and spatial relations. Although VLMs with larger pre-training datasets, model sizes, and multiple pre-training objectives achieve better performance on SUGARCREPE++, there is a significant opportunity for improvement. We show that all the models which achieve better performance on compositionality datasets need not perform equally well on SUGARCREPE++, signifying that compositionality alone may not be sufficient for understanding semantic and lexical alterations. Given the importance of the property that the SUGARCREPE++ dataset targets, it serves as a new challenge to the vision-and-language community.
VISLA Benchmark: Evaluating Embedding Sensitivity to Semantic and Lexical Alterations
Apr 25, 2024



Despite their remarkable successes, state-of-the-art language models face challenges in grasping certain important semantic details. This paper introduces the VISLA (Variance and Invariance to Semantic and Lexical Alterations) benchmark, designed to evaluate the semantic and lexical understanding of language models. VISLA presents a 3-way semantic (in)equivalence task with a triplet of sentences associated with an image, to evaluate both vision-language models (VLMs) and unimodal language models (ULMs). An evaluation involving 34 VLMs and 20 ULMs reveals surprising difficulties in distinguishing between lexical and semantic variations. Spatial semantics encoded by language models also appear to be highly sensitive to lexical information. Notably, text encoders of VLMs demonstrate greater sensitivity to semantic and lexical variations than unimodal text encoders. Our contributions include the unification of image-to-text and text-to-text retrieval tasks, an off-the-shelf evaluation without fine-tuning, and assessing LMs' semantic (in)variance in the presence of lexical alterations. The results highlight strengths and weaknesses across diverse vision and unimodal language models, contributing to a deeper understanding of their capabilities. % VISLA enables a rigorous evaluation, shedding light on language models' capabilities in handling semantic and lexical nuances. Data and code will be made available at https://github.com/Sri-Harsha/visla_benchmark.
Test-Time Training for Speech
Sep 28, 2023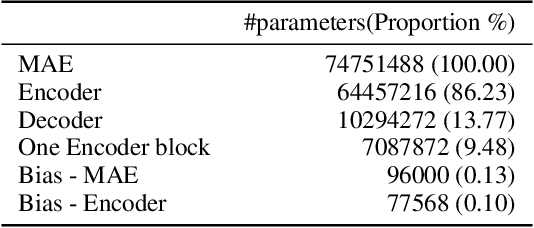
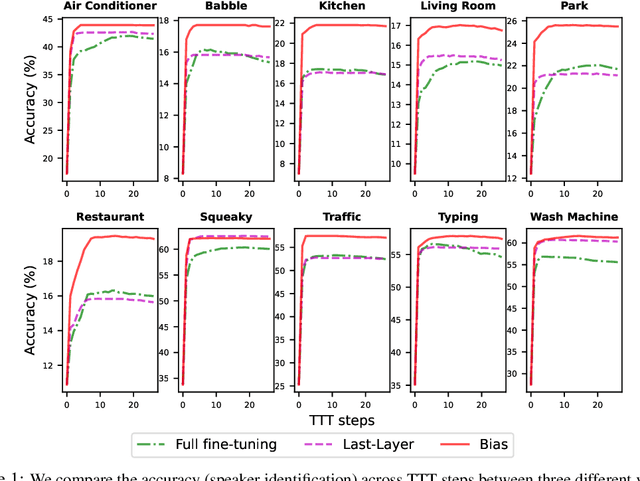
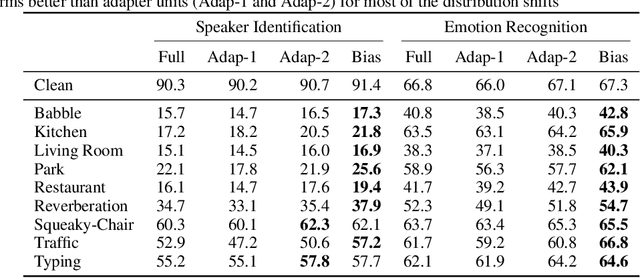
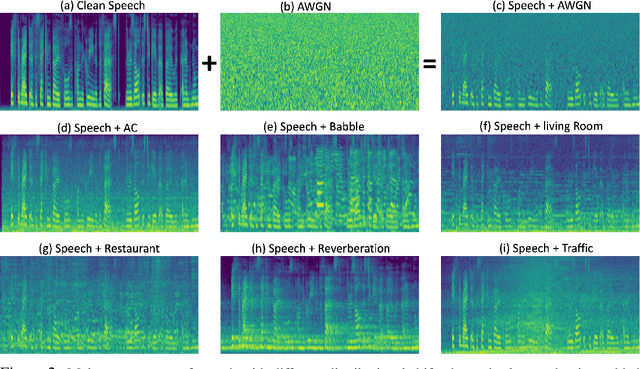
In this paper, we study the application of Test-Time Training (TTT) as a solution to handling distribution shifts in speech applications. In particular, we introduce distribution-shifts to the test datasets of standard speech-classification tasks -- for example, speaker-identification and emotion-detection -- and explore how Test-Time Training (TTT) can help adjust to the distribution-shift. In our experiments that include distribution shifts due to background noise and natural variations in speech such as gender and age, we identify some key-challenges with TTT including sensitivity to optimization hyperparameters (e.g., number of optimization steps and subset of parameters chosen for TTT) and scalability (e.g., as each example gets its own set of parameters, TTT is not scalable). Finally, we propose using BitFit -- a parameter-efficient fine-tuning algorithm proposed for text applications that only considers the bias parameters for fine-tuning -- as a solution to the aforementioned challenges and demonstrate that it is consistently more stable than fine-tuning all the parameters of the model.
Training Diffusion Classifiers with Denoising Assistance
Jun 15, 2023
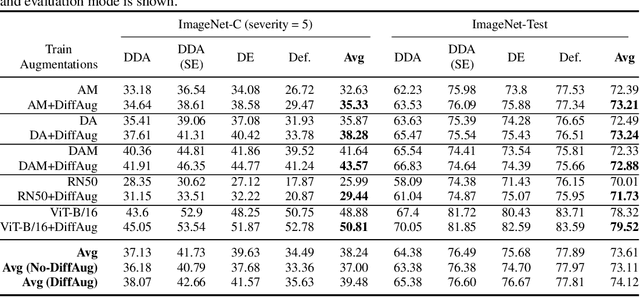
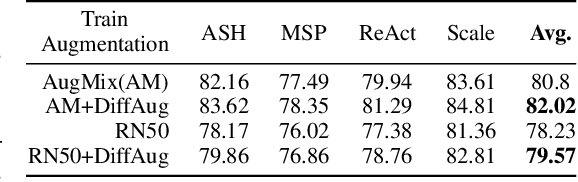
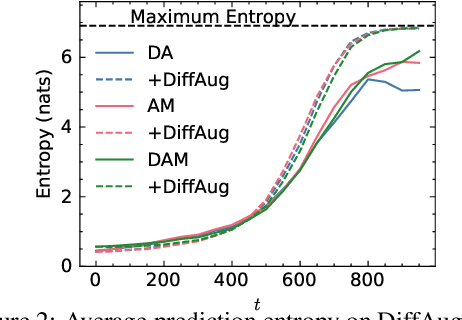
Score-matching and diffusion models have emerged as state-of-the-art generative models for both conditional and unconditional generation. Classifier-guided diffusion models are created by training a classifier on samples obtained from the forward-diffusion process (i.e., from data to noise). In this paper, we propose denoising-assisted (DA) classifiers wherein the diffusion classifier is trained using both noisy and denoised examples as simultaneous inputs to the model. We differentiate between denoising-assisted (DA) classifiers and noisy classifiers, which are diffusion classifiers that are only trained on noisy examples. Our experiments on Cifar10 and Imagenet show that DA-classifiers improve over noisy classifiers both quantitatively in terms of generalization to test data and qualitatively in terms of perceptually-aligned classifier-gradients and generative modeling metrics. Finally, we describe a semi-supervised framework for training diffusion classifiers and our experiments, that also include positive-unlabeled settings, demonstrate improved generalization of DA-classifiers over noisy classifiers.