 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHide & Seek: Transformer Symmetries Obscure Sharpness & Riemannian Geometry Finds It
May 08, 2025The concept of sharpness has been successfully applied to traditional architectures like MLPs and CNNs to predict their generalization. For transformers, however, recent work reported weak correlation between flatness and generalization. We argue that existing sharpness measures fail for transformers, because they have much richer symmetries in their attention mechanism that induce directions in parameter space along which the network or its loss remain identical. We posit that sharpness must account fully for these symmetries, and thus we redefine it on a quotient manifold that results from quotienting out the transformer symmetries, thereby removing their ambiguities. Leveraging tools from Riemannian geometry, we propose a fully general notion of sharpness, in terms of a geodesic ball on the symmetry-corrected quotient manifold. In practice, we need to resort to approximating the geodesics. Doing so up to first order yields existing adaptive sharpness measures, and we demonstrate that including higher-order terms is crucial to recover correlation with generalization. We present results on diagonal networks with synthetic data, and show that our geodesic sharpness reveals strong correlation for real-world transformers on both text and image classification tasks.
Seeing Syntax: Uncovering Syntactic Learning Limitations in Vision-Language Models
Dec 11, 2024


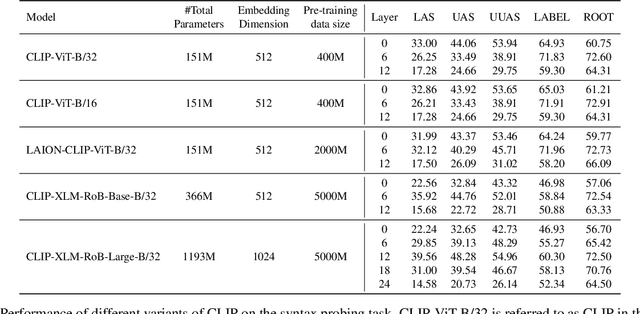
Vision-language models (VLMs), serve as foundation models for multi-modal applications such as image captioning and text-to-image generation. Recent studies have highlighted limitations in VLM text encoders, particularly in areas like compositionality and semantic understanding, though the underlying reasons for these limitations remain unclear. In this work, we aim to address this gap by analyzing the syntactic information, one of the fundamental linguistic properties, encoded by the text encoders of VLMs. We perform a thorough analysis comparing VLMs with different objective functions, parameter size and training data size, and with uni-modal language models (ULMs) in their ability to encode syntactic knowledge. Our findings suggest that ULM text encoders acquire syntactic information more effectively than those in VLMs. The syntactic information learned by VLM text encoders is shaped primarily by the pre-training objective, which plays a more crucial role than other factors such as model architecture, model size, or the volume of pre-training data. Models exhibit different layer-wise trends where CLIP performance dropped across layers while for other models, middle layers are rich in encoding syntactic knowledge.
Sensitivity of Generative VLMs to Semantically and Lexically Altered Prompts
Oct 16, 2024

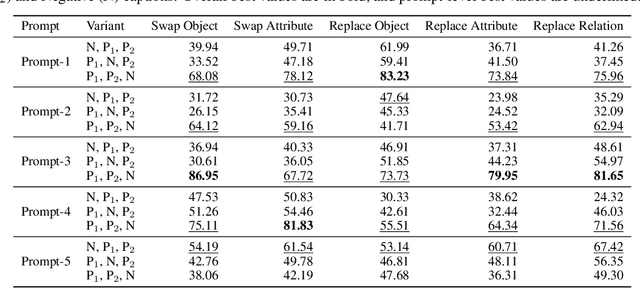
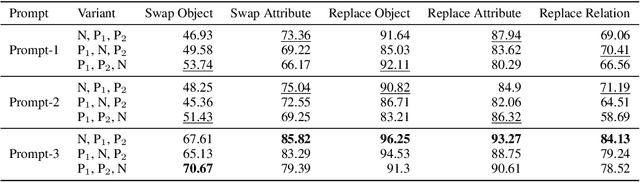
Despite the significant influx of prompt-tuning techniques for generative vision-language models (VLMs), it remains unclear how sensitive these models are to lexical and semantic alterations in prompts. In this paper, we evaluate the ability of generative VLMs to understand lexical and semantic changes in text using the SugarCrepe++ dataset. We analyze the sensitivity of VLMs to lexical alterations in prompts without corresponding semantic changes. Our findings demonstrate that generative VLMs are highly sensitive to such alterations. Additionally, we show that this vulnerability affects the performance of techniques aimed at achieving consistency in their outputs.
Self-Supervised Embeddings for Detecting Individual Symptoms of Depression
Jun 25, 2024



Depression, a prevalent mental health disorder impacting millions globally, demands reliable assessment systems. Unlike previous studies that focus solely on either detecting depression or predicting its severity, our work identifies individual symptoms of depression while also predicting its severity using speech input. We leverage self-supervised learning (SSL)-based speech models to better utilize the small-sized datasets that are frequently encountered in this task. Our study demonstrates notable performance improvements by utilizing SSL embeddings compared to conventional speech features. We compare various types of SSL pretrained models to elucidate the type of speech information (semantic, speaker, or prosodic) that contributes the most in identifying different symptoms. Additionally, we evaluate the impact of combining multiple SSL embeddings on performance. Furthermore, we show the significance of multi-task learning for identifying depressive symptoms effectively.
Predicting Individual Depression Symptoms from Acoustic Features During Speech
Jun 23, 2024Current automatic depression detection systems provide predictions directly without relying on the individual symptoms/items of depression as denoted in the clinical depression rating scales. In contrast, clinicians assess each item in the depression rating scale in a clinical setting, thus implicitly providing a more detailed rationale for a depression diagnosis. In this work, we make a first step towards using the acoustic features of speech to predict individual items of the depression rating scale before obtaining the final depression prediction. For this, we use convolutional (CNN) and recurrent (long short-term memory (LSTM)) neural networks. We consider different approaches to learning the temporal context of speech. Further, we analyze two variants of voting schemes for individual item prediction and depression detection. We also include an animated visualization that shows an example of item prediction over time as the speech progresses.
SUGARCREPE++ Dataset: Vision-Language Model Sensitivity to Semantic and Lexical Alterations
Jun 17, 2024Despite their remarkable successes, state-of-the-art large language models (LLMs), including vision-and-language models (VLMs) and unimodal language models (ULMs), fail to understand precise semantics. For example, semantically equivalent sentences expressed using different lexical compositions elicit diverging representations. The degree of this divergence and its impact on encoded semantics is not very well understood. In this paper, we introduce the SUGARCREPE++ dataset to analyze the sensitivity of VLMs and ULMs to lexical and semantic alterations. Each sample in SUGARCREPE++ dataset consists of an image and a corresponding triplet of captions: a pair of semantically equivalent but lexically different positive captions and one hard negative caption. This poses a 3-way semantic (in)equivalence problem to the language models. We comprehensively evaluate VLMs and ULMs that differ in architecture, pre-training objectives and datasets to benchmark the performance of SUGARCREPE++ dataset. Experimental results highlight the difficulties of VLMs in distinguishing between lexical and semantic variations, particularly in object attributes and spatial relations. Although VLMs with larger pre-training datasets, model sizes, and multiple pre-training objectives achieve better performance on SUGARCREPE++, there is a significant opportunity for improvement. We show that all the models which achieve better performance on compositionality datasets need not perform equally well on SUGARCREPE++, signifying that compositionality alone may not be sufficient for understanding semantic and lexical alterations. Given the importance of the property that the SUGARCREPE++ dataset targets, it serves as a new challenge to the vision-and-language community.
An Empirical Study into Clustering of Unseen Datasets with Self-Supervised Encoders
Jun 04, 2024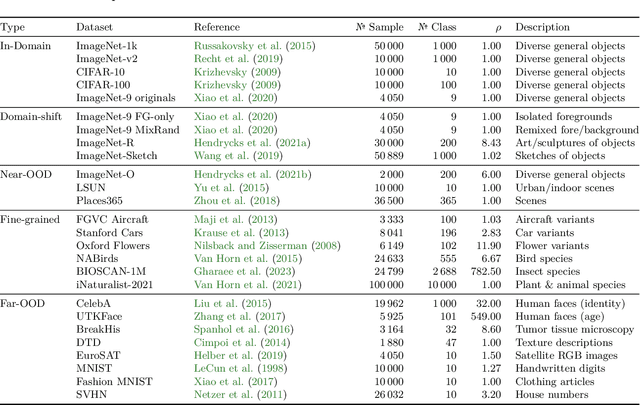
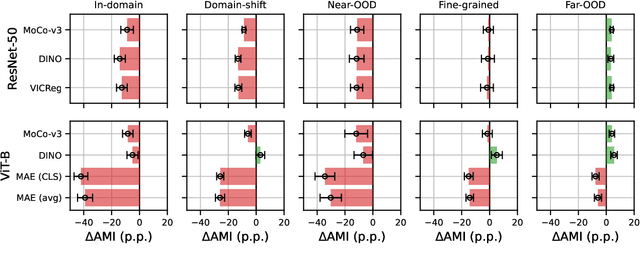
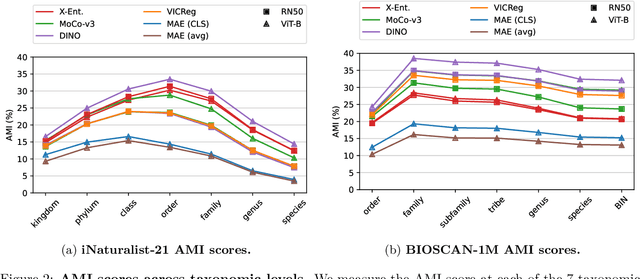
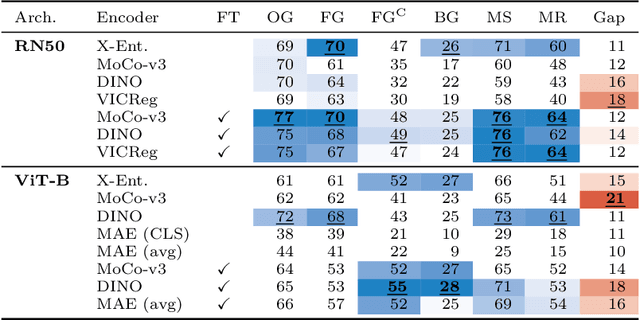
Can pretrained models generalize to new datasets without any retraining? We deploy pretrained image models on datasets they were not trained for, and investigate whether their embeddings form meaningful clusters. Our suite of benchmarking experiments use encoders pretrained solely on ImageNet-1k with either supervised or self-supervised training techniques, deployed on image datasets that were not seen during training, and clustered with conventional clustering algorithms. This evaluation provides new insights into the embeddings of self-supervised models, which prioritize different features to supervised models. Supervised encoders typically offer more utility than SSL encoders within the training domain, and vice-versa far outside of it, however, fine-tuned encoders demonstrate the opposite trend. Clustering provides a way to evaluate the utility of self-supervised learned representations orthogonal to existing methods such as kNN. Additionally, we find the silhouette score when measured in a UMAP-reduced space is highly correlated with clustering performance, and can therefore be used as a proxy for clustering performance on data with no ground truth labels. Our code implementation is available at \url{https://github.com/scottclowe/zs-ssl-clustering/}.
VISLA Benchmark: Evaluating Embedding Sensitivity to Semantic and Lexical Alterations
Apr 25, 2024



Despite their remarkable successes, state-of-the-art language models face challenges in grasping certain important semantic details. This paper introduces the VISLA (Variance and Invariance to Semantic and Lexical Alterations) benchmark, designed to evaluate the semantic and lexical understanding of language models. VISLA presents a 3-way semantic (in)equivalence task with a triplet of sentences associated with an image, to evaluate both vision-language models (VLMs) and unimodal language models (ULMs). An evaluation involving 34 VLMs and 20 ULMs reveals surprising difficulties in distinguishing between lexical and semantic variations. Spatial semantics encoded by language models also appear to be highly sensitive to lexical information. Notably, text encoders of VLMs demonstrate greater sensitivity to semantic and lexical variations than unimodal text encoders. Our contributions include the unification of image-to-text and text-to-text retrieval tasks, an off-the-shelf evaluation without fine-tuning, and assessing LMs' semantic (in)variance in the presence of lexical alterations. The results highlight strengths and weaknesses across diverse vision and unimodal language models, contributing to a deeper understanding of their capabilities. % VISLA enables a rigorous evaluation, shedding light on language models' capabilities in handling semantic and lexical nuances. Data and code will be made available at https://github.com/Sri-Harsha/visla_benchmark.
Test-Time Training for Depression Detection
Apr 07, 2024



Previous works on depression detection use datasets collected in similar environments to train and test the models. In practice, however, the train and test distributions cannot be guaranteed to be identical. Distribution shifts can be introduced due to variations such as recording environment (e.g., background noise) and demographics (e.g., gender, age, etc). Such distributional shifts can surprisingly lead to severe performance degradation of the depression detection models. In this paper, we analyze the application of test-time training (TTT) to improve robustness of models trained for depression detection. When compared to regular testing of the models, we find TTT can significantly improve the robustness of the model under a variety of distributional shifts introduced due to: (a) background-noise, (b) gender-bias, and (c) data collection and curation procedure (i.e., train and test samples are from separate datasets).
Symbolic Music Generation with Non-Differentiable Rule Guided Diffusion
Feb 23, 2024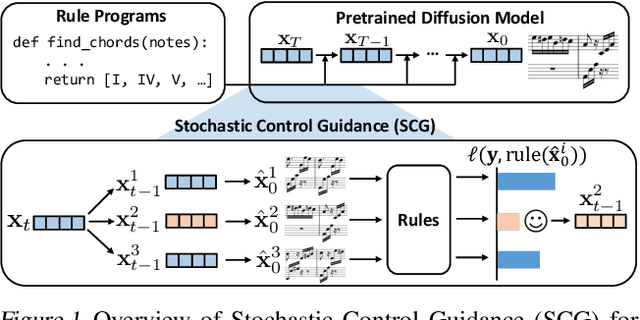



We study the problem of symbolic music generation (e.g., generating piano rolls), with a technical focus on non-differentiable rule guidance. Musical rules are often expressed in symbolic form on note characteristics, such as note density or chord progression, many of which are non-differentiable which pose a challenge when using them for guided diffusion. We propose Stochastic Control Guidance (SCG), a novel guidance method that only requires forward evaluation of rule functions that can work with pre-trained diffusion models in a plug-and-play way, thus achieving training-free guidance for non-differentiable rules for the first time. Additionally, we introduce a latent diffusion architecture for symbolic music generation with high time resolution, which can be composed with SCG in a plug-and-play fashion. Compared to standard strong baselines in symbolic music generation, this framework demonstrates marked advancements in music quality and rule-based controllability, outperforming current state-of-the-art generators in a variety of settings. For detailed demonstrations, code and model checkpoints, please visit our project website: https://scg-rule-guided-music.github.io/.