 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Embeddings for Detecting Individual Symptoms of Depression
Jun 25, 2024



Depression, a prevalent mental health disorder impacting millions globally, demands reliable assessment systems. Unlike previous studies that focus solely on either detecting depression or predicting its severity, our work identifies individual symptoms of depression while also predicting its severity using speech input. We leverage self-supervised learning (SSL)-based speech models to better utilize the small-sized datasets that are frequently encountered in this task. Our study demonstrates notable performance improvements by utilizing SSL embeddings compared to conventional speech features. We compare various types of SSL pretrained models to elucidate the type of speech information (semantic, speaker, or prosodic) that contributes the most in identifying different symptoms. Additionally, we evaluate the impact of combining multiple SSL embeddings on performance. Furthermore, we show the significance of multi-task learning for identifying depressive symptoms effectively.
Representational Rényi heterogeneity
Dec 13, 2019
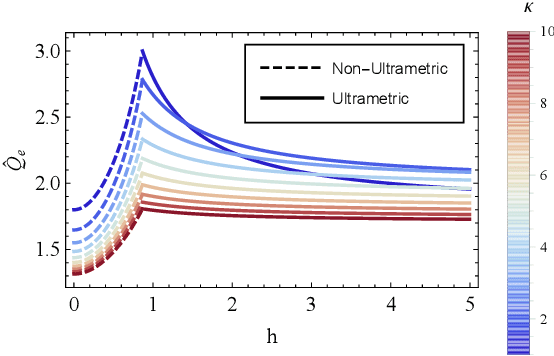


A discrete system's heterogeneity is measured by the R\'enyi heterogeneity family of indices (also known as Hill numbers or Hannah-Kay indices), whose units are known as the numbers equivalent, and whose scaling properties are consistent and intuitive. Unfortunately, numbers equivalent heterogeneity measures for non-categorical data require a priori (A) categorical partitioning and (B) pairwise distance measurement on the space of observable data. This precludes their application to problems in disciplines where categories are ill-defined or where semantically relevant features must be learned as abstractions from some data. We thus introduce representational R\'enyi heterogeneity (RRH), which transforms an observable domain onto a latent space upon which the R\'enyi heterogeneity is both tractable and semantically relevant. This method does not require a priori binning nor definition of a distance function on the observable space. Compared with existing state-of-the-art indices on a beta-mixture distribution, we show that RRH more accurately detects the number of distinct mixture components. We also show that RRH can measure heterogeneity in natural images whose semantically relevant features must be abstracted using deep generative models. We further show that RRH can uniquely capture heterogeneity caused by distinct components in mixture distributions. Our novel approach will enable measurement of heterogeneity in disciplines where a priori categorical partitions of observable data are not possible, or where semantically relevant features must be inferred using latent variable models.
The Importance of Constraint Smoothness for Parameter Estimation in Computational Cognitive Modeling
Mar 24, 2018


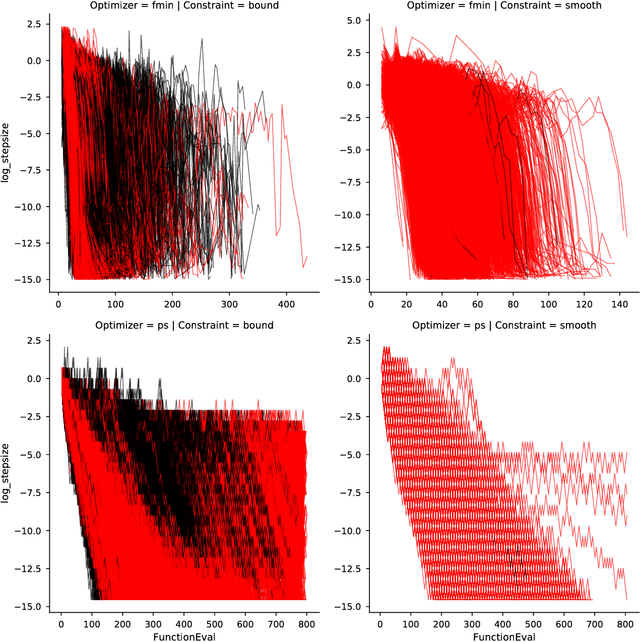
Psychiatric neuroscience is increasingly aware of the need to define psychopathology in terms of abnormal neural computation. The central tool in this endeavour is the fitting of computational models to behavioural data. The most prominent example of this procedure is fitting reinforcement learning (RL) models to decision-making data collected from mentally ill and healthy subject populations. These models are generative models of the decision-making data themselves, and the parameters we seek to infer can be psychologically and neurobiologically meaningful. Currently, the gold standard approach to this inference procedure involves Monte-Carlo sampling, which is robust but computationally intensive---rendering additional procedures, such as cross-validation, impractical. Searching for point estimates of model parameters using optimization procedures remains a popular and interesting option. On a novel testbed simulating parameter estimation from a common RL task, we investigated the effects of smooth vs. boundary constraints on parameter estimation using interior point and deterministic direct search algorithms for optimization. Ultimately, we show that the use of boundary constraints can lead to substantial truncation effects. Our results discourage the use of boundary constraints for these applications.