 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Parametric Design (GPD): A framework for real-time geometry generation and on-the-fly multiparametric approximation
Dec 12, 2025This paper presents a novel paradigm in simulation-based engineering sciences by introducing a new framework called Generative Parametric Design (GPD). The GPD framework enables the generation of new designs along with their corresponding parametric solutions given as a reduced basis. To achieve this, two Rank Reduction Autoencoders (RRAEs) are employed, one for encoding and generating the design or geometry, and the other for encoding the sparse Proper Generalized Decomposition (sPGD) mode solutions. These models are linked in the latent space using regression techniques, allowing efficient transitions between design and their associated sPGD modes. By empowering design exploration and optimization, this framework also advances digital and hybrid twin development, enhancing predictive modeling and real-time decision-making in engineering applications. The developed framework is demonstrated on two-phase microstructures, in which the multiparametric solutions account for variations in two key material parameters.
RRAEDy: Adaptive Latent Linearization of Nonlinear Dynamical Systems
Dec 08, 2025Most existing latent-space models for dynamical systems require fixing the latent dimension in advance, they rely on complex loss balancing to approximate linear dynamics, and they don't regularize the latent variables. We introduce RRAEDy, a model that removes these limitations by discovering the appropriate latent dimension, while enforcing both regularized and linearized dynamics in the latent space. Built upon Rank-Reduction Autoencoders (RRAEs), RRAEDy automatically rank and prune latent variables through their singular values while learning a latent Dynamic Mode Decomposition (DMD) operator that governs their temporal progression. This structure-free yet linearly constrained formulation enables the model to learn stable and low-dimensional dynamics without auxiliary losses or manual tuning. We provide theoretical analysis demonstrating the stability of the learned operator and showcase the generality of our model by proposing an extension that handles parametric ODEs. Experiments on canonical benchmarks, including the Van der Pol oscillator, Burgers' equation, 2D Navier-Stokes, and Rotating Gaussians, show that RRAEDy achieves accurate and robust predictions. Our code is open-source and available at https://github.com/JadM133/RRAEDy. We also provide a video summarizing the main results at https://youtu.be/ox70mSSMGrM.
Predicting Individual Depression Symptoms from Acoustic Features During Speech
Jun 23, 2024Current automatic depression detection systems provide predictions directly without relying on the individual symptoms/items of depression as denoted in the clinical depression rating scales. In contrast, clinicians assess each item in the depression rating scale in a clinical setting, thus implicitly providing a more detailed rationale for a depression diagnosis. In this work, we make a first step towards using the acoustic features of speech to predict individual items of the depression rating scale before obtaining the final depression prediction. For this, we use convolutional (CNN) and recurrent (long short-term memory (LSTM)) neural networks. We consider different approaches to learning the temporal context of speech. Further, we analyze two variants of voting schemes for individual item prediction and depression detection. We also include an animated visualization that shows an example of item prediction over time as the speech progresses.
Rank Reduction Autoencoders -- Enhancing interpolation on nonlinear manifolds
May 22, 2024The efficiency of classical Autoencoders (AEs) is limited in many practical situations. When the latent space is reduced through autoencoders, feature extraction becomes possible. However, overfitting is a common issue, leading to ``holes'' in AEs' interpolation capabilities. On the other hand, increasing the latent dimension results in a better approximation with fewer non-linearly coupled features (e.g., Koopman theory or kPCA), but it doesn't necessarily lead to dimensionality reduction, which makes feature extraction problematic. As a result, interpolating using Autoencoders gets harder. In this work, we introduce the Rank Reduction Autoencoder (RRAE), an autoencoder with an enlarged latent space, which is constrained to have a small pre-specified number of dominant singular values (i.e., low-rank). The latent space of RRAEs is large enough to enable accurate predictions while enabling feature extraction. As a result, the proposed autoencoder features a minimal rank linear latent space. To achieve what's proposed, two formulations are presented, a strong and a weak one, that build a reduced basis accurately representing the latent space. The first formulation consists of a truncated SVD in the latent space, while the second one adds a penalty term to the loss function. We show the efficiency of our formulations by using them for interpolation tasks and comparing the results to other autoencoders on both synthetic data and MNIST.
Significance of Speaker Embeddings and Temporal Context for Depression Detection
Jul 24, 2021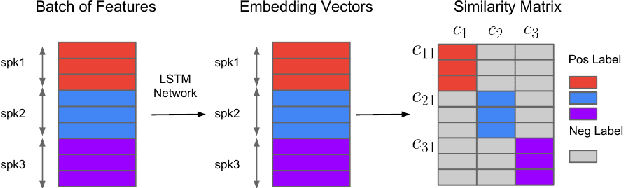
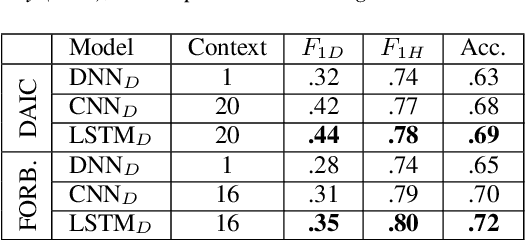
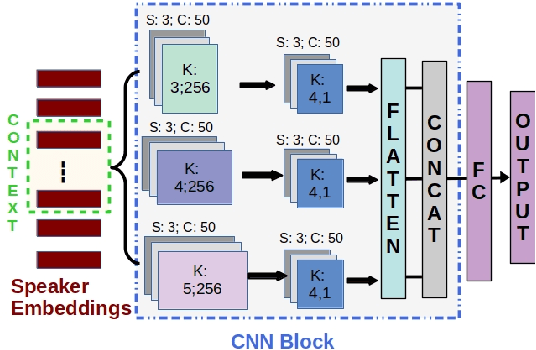
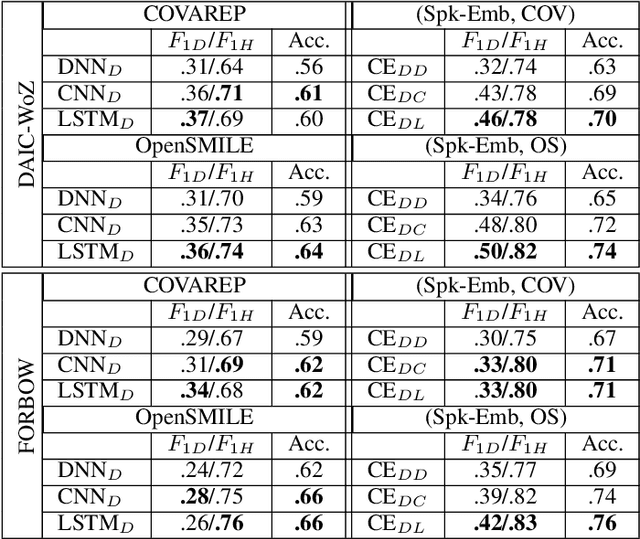
Depression detection from speech has attracted a lot of attention in recent years. However, the significance of speaker-specific information in depression detection has not yet been explored. In this work, we analyze the significance of speaker embeddings for the task of depression detection from speech. Experimental results show that the speaker embeddings provide important cues to achieve state-of-the-art performance in depression detection. We also show that combining conventional OpenSMILE and COVAREP features, which carry complementary information, with speaker embeddings further improves the depression detection performance. The significance of temporal context in the training of deep learning models for depression detection is also analyzed in this paper.