 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Music Generation with Non-Differentiable Rule Guided Diffusion
Feb 23, 2024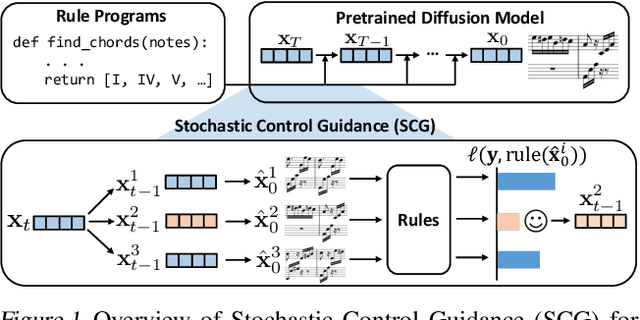



We study the problem of symbolic music generation (e.g., generating piano rolls), with a technical focus on non-differentiable rule guidance. Musical rules are often expressed in symbolic form on note characteristics, such as note density or chord progression, many of which are non-differentiable which pose a challenge when using them for guided diffusion. We propose Stochastic Control Guidance (SCG), a novel guidance method that only requires forward evaluation of rule functions that can work with pre-trained diffusion models in a plug-and-play way, thus achieving training-free guidance for non-differentiable rules for the first time. Additionally, we introduce a latent diffusion architecture for symbolic music generation with high time resolution, which can be composed with SCG in a plug-and-play fashion. Compared to standard strong baselines in symbolic music generation, this framework demonstrates marked advancements in music quality and rule-based controllability, outperforming current state-of-the-art generators in a variety of settings. For detailed demonstrations, code and model checkpoints, please visit our project website: https://scg-rule-guided-music.github.io/.
FI-ODE: Certified and Robust Forward Invariance in Neural ODEs
Oct 30, 2022We study how to certifiably enforce forward invariance properties in neural ODEs. Forward invariance implies that the hidden states of the ODE will stay in a ``good'' region, and a robust version would hold even under adversarial perturbations to the input. Such properties can be used to certify desirable behaviors such as adversarial robustness (the hidden states stay in the region that generates accurate classification even under input perturbations) and safety in continuous control (the system never leaves some safe set). We develop a general approach using tools from non-linear control theory and sampling-based verification. Our approach empirically produces the strongest adversarial robustness guarantees compared to prior work on certifiably robust ODE-based models (including implicit-depth models).
Diffusion Models for Adversarial Purification
May 16, 2022
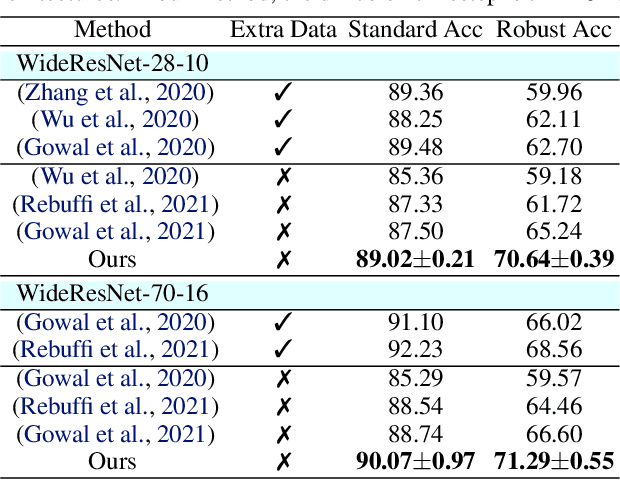

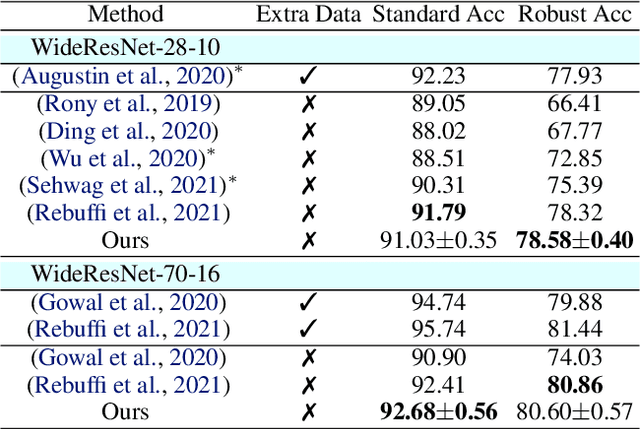
Adversarial purification refers to a class of defense methods that remove adversarial perturbations using a generative model. These methods do not make assumptions on the form of attack and the classification model, and thus can defend pre-existing classifiers against unseen threats. However, their performance currently falls behind adversarial training methods. In this work, we propose DiffPure that uses diffusion models for adversarial purification: Given an adversarial example, we first diffuse it with a small amount of noise following a forward diffusion process, and then recover the clean image through a reverse generative process. To evaluate our method against strong adaptive attacks in an efficient and scalable way, we propose to use the adjoint method to compute full gradients of the reverse generative process. Extensive experiments on three image datasets including CIFAR-10, ImageNet and CelebA-HQ with three classifier architectures including ResNet, WideResNet and ViT demonstrate that our method achieves the state-of-the-art results, outperforming current adversarial training and adversarial purification methods, often by a large margin. Project page: https://diffpure.github.io.
Training Certifiably Robust Neural Networks with Efficient Local Lipschitz Bounds
Nov 02, 2021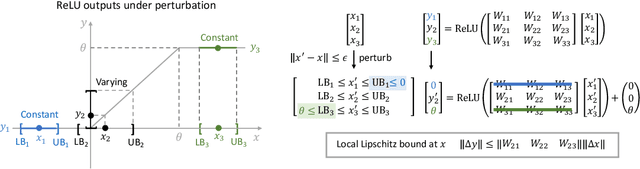
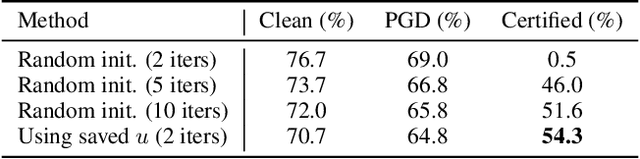
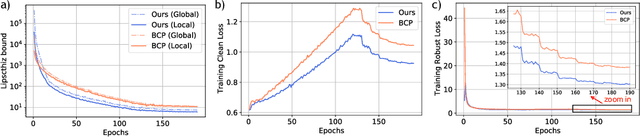
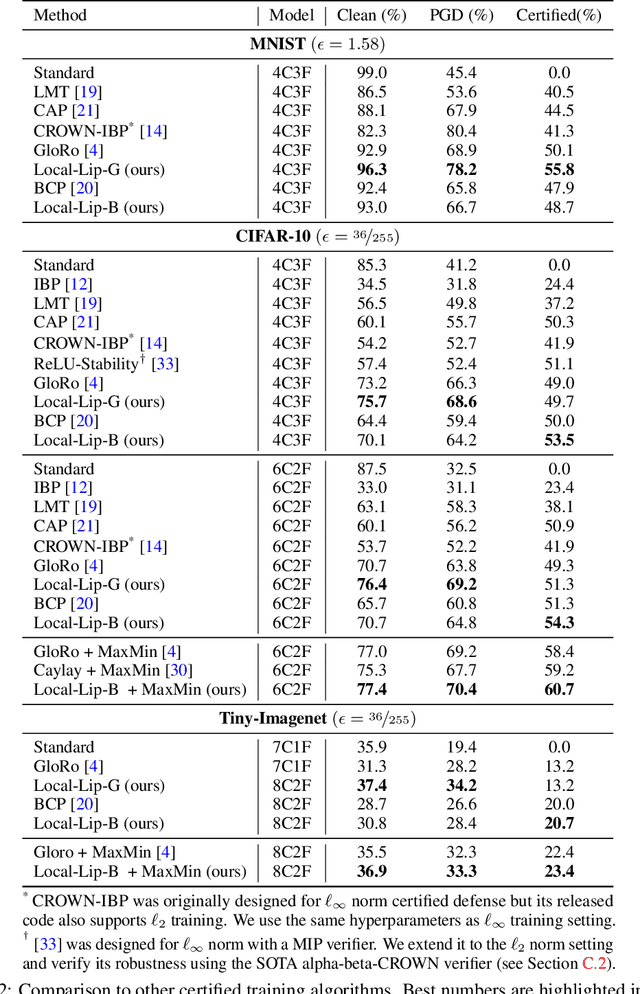
Certified robustness is a desirable property for deep neural networks in safety-critical applications, and popular training algorithms can certify robustness of a neural network by computing a global bound on its Lipschitz constant. However, such a bound is often loose: it tends to over-regularize the neural network and degrade its natural accuracy. A tighter Lipschitz bound may provide a better tradeoff between natural and certified accuracy, but is generally hard to compute exactly due to non-convexity of the network. In this work, we propose an efficient and trainable \emph{local} Lipschitz upper bound by considering the interactions between activation functions (e.g. ReLU) and weight matrices. Specifically, when computing the induced norm of a weight matrix, we eliminate the corresponding rows and columns where the activation function is guaranteed to be a constant in the neighborhood of each given data point, which provides a provably tighter bound than the global Lipschitz constant of the neural network. Our method can be used as a plug-in module to tighten the Lipschitz bound in many certifiable training algorithms. Furthermore, we propose to clip activation functions (e.g., ReLU and MaxMin) with a learnable upper threshold and a sparsity loss to assist the network to achieve an even tighter local Lipschitz bound. Experimentally, we show that our method consistently outperforms state-of-the-art methods in both clean and certified accuracy on MNIST, CIFAR-10 and TinyImageNet datasets with various network architectures.
Neural Networks with Recurrent Generative Feedback
Jul 17, 2020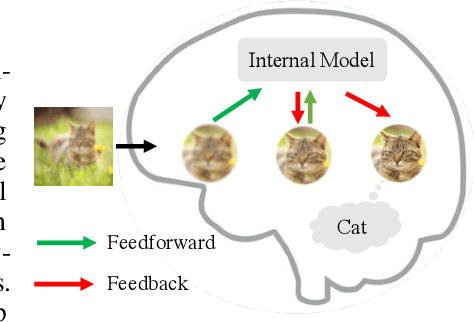

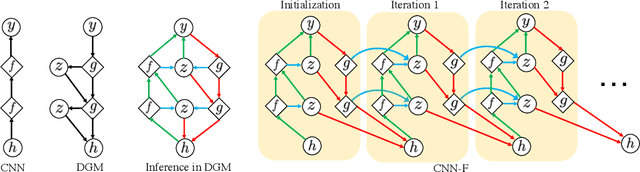
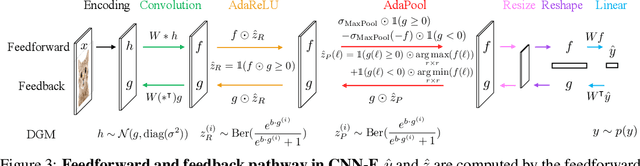
Neural networks are vulnerable to input perturbations such as additive noise and adversarial attacks. In contrast, human perception is much more robust to such perturbations. The Bayesian brain hypothesis states that human brains use an internal generative model to update the posterior beliefs of the sensory input. This mechanism can be interpreted as a form of self-consistency between the maximum a posteriori (MAP) estimation of the internal generative model and the external environmental. Inspired by this, we enforce consistency in neural networks by incorporating generative recurrent feedback. We instantiate it on convolutional neural networks (CNNs). The proposed framework, termed Convolutional Neural Networks with Feedback (CNN-F), introduces a generative feedback with latent variables into existing CNN architectures, making consistent predictions via alternating MAP inference under a Bayesian framework. CNN-F shows considerably better adversarial robustness over regular feedforward CNNs on standard benchmarks. In addition, With higher V4 and IT neural predictivity, CNN-F produces object representations closer to primate vision than conventional CNNs.
Out-of-Distribution Detection Using Neural Rendering Generative Models
Jul 10, 2019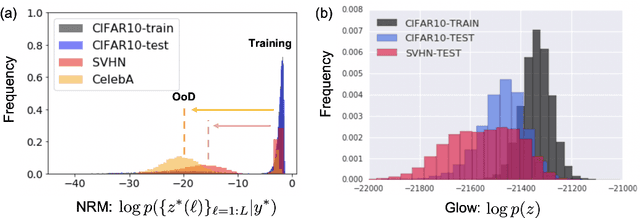

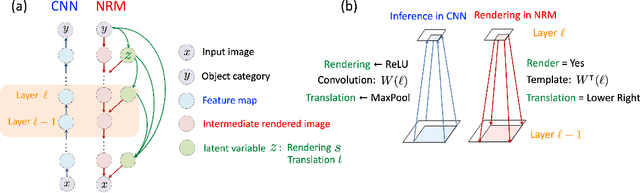
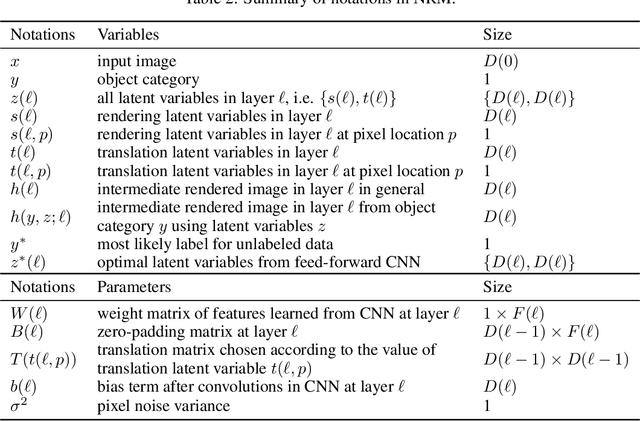
Out-of-distribution (OoD) detection is a natural downstream task for deep generative models, due to their ability to learn the input probability distribution. There are mainly two classes of approaches for OoD detection using deep generative models, viz., based on likelihood measure and the reconstruction loss. However, both approaches are unable to carry out OoD detection effectively, especially when the OoD samples have smaller variance than the training samples. For instance, both flow based and VAE models assign higher likelihood to images from SVHN when trained on CIFAR-10 images. We use a recently proposed generative model known as neural rendering model (NRM) and derive metrics for OoD. We show that NRM unifies both approaches since it provides a likelihood estimate and also carries out reconstruction in each layer of the neural network. Among various measures, we found the joint likelihood of latent variables to be the most effective one for OoD detection. Our results show that when trained on CIFAR-10, lower likelihood (of latent variables) is assigned to SVHN images. Additionally, we show that this metric is consistent across other OoD datasets. To the best of our knowledge, this is the first work to show consistently lower likelihood for OoD data with smaller variance with deep generative models.
Semantic-driven Generation of Hyperlapse from $360^\circ$ Video
Oct 10, 2017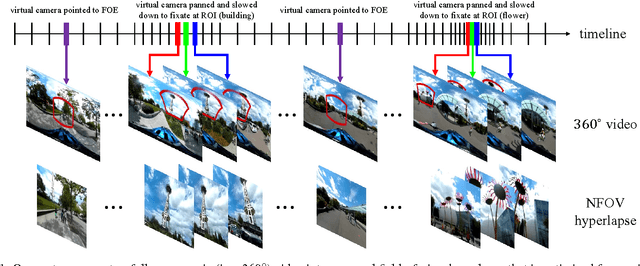

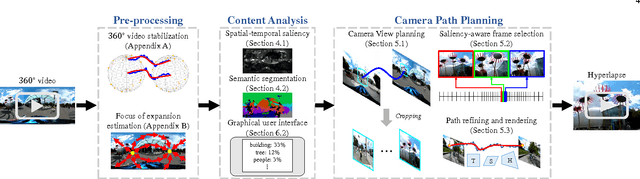
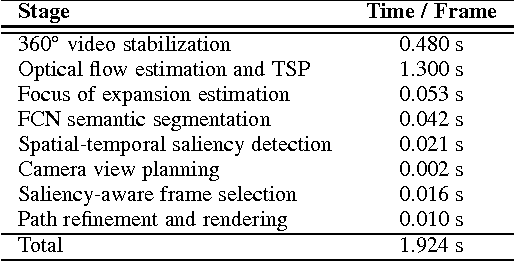
We present a system for converting a fully panoramic ($360^\circ$) video into a normal field-of-view (NFOV) hyperlapse for an optimal viewing experience. Our system exploits visual saliency and semantics to non-uniformly sample in space and time for generating hyperlapses. In addition, users can optionally choose objects of interest for customizing the hyperlapses. We first stabilize an input $360^\circ$ video by smoothing the rotation between adjacent frames and then compute regions of interest and saliency scores. An initial hyperlapse is generated by optimizing the saliency and motion smoothness followed by the saliency-aware frame selection. We further smooth the result using an efficient 2D video stabilization approach that adaptively selects the motion model to generate the final hyperlapse. We validate the design of our system by showing results for a variety of scenes and comparing against the state-of-the-art method through a user study.
Pose Invariant Embedding for Deep Person Re-identification
Jan 26, 2017
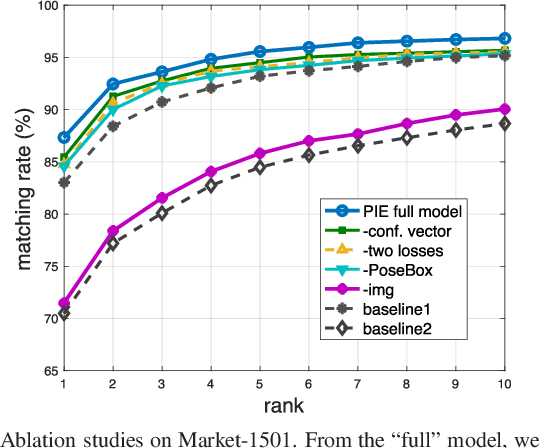


Pedestrian misalignment, which mainly arises from detector errors and pose variations, is a critical problem for a robust person re-identification (re-ID) system. With bad alignment, the background noise will significantly compromise the feature learning and matching process. To address this problem, this paper introduces the pose invariant embedding (PIE) as a pedestrian descriptor. First, in order to align pedestrians to a standard pose, the PoseBox structure is introduced, which is generated through pose estimation followed by affine transformations. Second, to reduce the impact of pose estimation errors and information loss during PoseBox construction, we design a PoseBox fusion (PBF) CNN architecture that takes the original image, the PoseBox, and the pose estimation confidence as input. The proposed PIE descriptor is thus defined as the fully connected layer of the PBF network for the retrieval task. Experiments are conducted on the Market-1501, CUHK03, and VIPeR datasets. We show that PoseBox alone yields decent re-ID accuracy and that when integrated in the PBF network, the learned PIE descriptor produces competitive performance compared with the state-of-the-art approaches.