 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining a Generally Curious Agent
Feb 24, 2025



Efficient exploration is essential for intelligent systems interacting with their environment, but existing language models often fall short in scenarios that require strategic information gathering. In this paper, we present PAPRIKA, a fine-tuning approach that enables language models to develop general decision-making capabilities that are not confined to particular environments. By training on synthetic interaction data from different tasks that require diverse strategies, PAPRIKA teaches models to explore and adapt their behavior on a new task based on environment feedback in-context without more gradient updates. Experimental results show that models fine-tuned with PAPRIKA can effectively transfer their learned decision-making capabilities to entirely unseen tasks without additional training. Unlike traditional training, our approach's primary bottleneck lies in sampling useful interaction data instead of model updates. To improve sample efficiency, we propose a curriculum learning strategy that prioritizes sampling trajectories from tasks with high learning potential. These results suggest a promising path towards AI systems that can autonomously solve novel sequential decision-making problems that require interactions with the external world.
Language models are weak learners
Jun 25, 2023A central notion in practical and theoretical machine learning is that of a $\textit{weak learner}$, classifiers that achieve better-than-random performance (on any given distribution over data), even by a small margin. Such weak learners form the practical basis for canonical machine learning methods such as boosting. In this work, we illustrate that prompt-based large language models can operate effectively as said weak learners. Specifically, we illustrate the use of a large language model (LLM) as a weak learner in a boosting algorithm applied to tabular data. We show that by providing (properly sampled according to the distribution of interest) text descriptions of tabular data samples, LLMs can produce a summary of the samples that serves as a template for classification and achieves the aim of acting as a weak learner on this task. We incorporate these models into a boosting approach, which in some settings can leverage the knowledge within the LLM to outperform traditional tree-based boosting. The model outperforms both few-shot learning and occasionally even more involved fine-tuning procedures, particularly for tasks involving small numbers of data points. The results illustrate the potential for prompt-based LLMs to function not just as few-shot learners themselves, but as components of larger machine learning pipelines.
Training Certifiably Robust Neural Networks with Efficient Local Lipschitz Bounds
Nov 02, 2021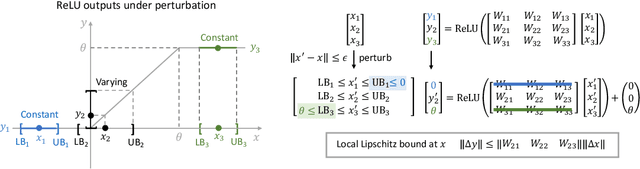
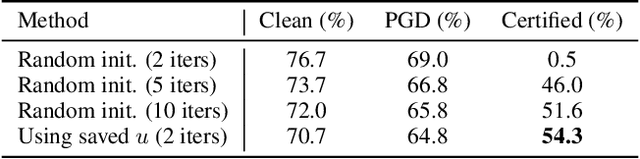
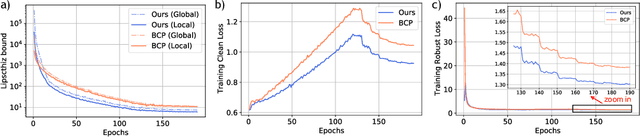
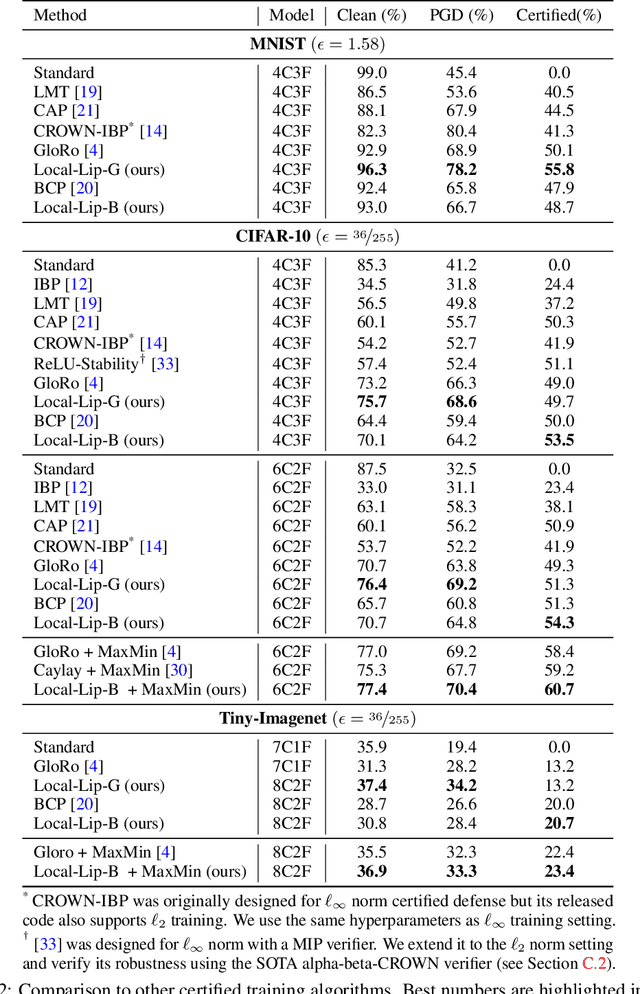
Certified robustness is a desirable property for deep neural networks in safety-critical applications, and popular training algorithms can certify robustness of a neural network by computing a global bound on its Lipschitz constant. However, such a bound is often loose: it tends to over-regularize the neural network and degrade its natural accuracy. A tighter Lipschitz bound may provide a better tradeoff between natural and certified accuracy, but is generally hard to compute exactly due to non-convexity of the network. In this work, we propose an efficient and trainable \emph{local} Lipschitz upper bound by considering the interactions between activation functions (e.g. ReLU) and weight matrices. Specifically, when computing the induced norm of a weight matrix, we eliminate the corresponding rows and columns where the activation function is guaranteed to be a constant in the neighborhood of each given data point, which provides a provably tighter bound than the global Lipschitz constant of the neural network. Our method can be used as a plug-in module to tighten the Lipschitz bound in many certifiable training algorithms. Furthermore, we propose to clip activation functions (e.g., ReLU and MaxMin) with a learnable upper threshold and a sparsity loss to assist the network to achieve an even tighter local Lipschitz bound. Experimentally, we show that our method consistently outperforms state-of-the-art methods in both clean and certified accuracy on MNIST, CIFAR-10 and TinyImageNet datasets with various network architectures.