 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Likelihood Reinforcement Learning
Feb 02, 2026Reinforcement learning is the method of choice to train models in sampling-based setups with binary outcome feedback, such as navigation, code generation, and mathematical problem solving. In such settings, models implicitly induce a likelihood over correct rollouts. However, we observe that reinforcement learning does not maximize this likelihood, and instead optimizes only a lower-order approximation. Inspired by this observation, we introduce Maximum Likelihood Reinforcement Learning (MaxRL), a sampling-based framework to approximate maximum likelihood using reinforcement learning techniques. MaxRL addresses the challenges of non-differentiable sampling by defining a compute-indexed family of sample-based objectives that interpolate between standard reinforcement learning and exact maximum likelihood as additional sampling compute is allocated. The resulting objectives admit a simple, unbiased policy-gradient estimator and converge to maximum likelihood optimization in the infinite-compute limit. Empirically, we show that MaxRL Pareto-dominates existing methods in all models and tasks we tested, achieving up to 20x test-time scaling efficiency gains compared to its GRPO-trained counterpart. We also observe MaxRL to scale better with additional data and compute. Our results suggest MaxRL is a promising framework for scaling RL training in correctness based settings.
From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
Jan 06, 2026Can we learn more from data than existed in the generating process itself? Can new and useful information be constructed from merely applying deterministic transformations to existing data? Can the learnable content in data be evaluated without considering a downstream task? On these questions, Shannon information and Kolmogorov complexity come up nearly empty-handed, in part because they assume observers with unlimited computational capacity and fail to target the useful information content. In this work, we identify and exemplify three seeming paradoxes in information theory: (1) information cannot be increased by deterministic transformations; (2) information is independent of the order of data; (3) likelihood modeling is merely distribution matching. To shed light on the tension between these results and modern practice, and to quantify the value of data, we introduce epiplexity, a formalization of information capturing what computationally bounded observers can learn from data. Epiplexity captures the structural content in data while excluding time-bounded entropy, the random unpredictable content exemplified by pseudorandom number generators and chaotic dynamical systems. With these concepts, we demonstrate how information can be created with computation, how it depends on the ordering of the data, and how likelihood modeling can produce more complex programs than present in the data generating process itself. We also present practical procedures to estimate epiplexity which we show capture differences across data sources, track with downstream performance, and highlight dataset interventions that improve out-of-distribution generalization. In contrast to principles of model selection, epiplexity provides a theoretical foundation for data selection, guiding how to select, generate, or transform data for learning systems.
Safety Pretraining: Toward the Next Generation of Safe AI
Apr 23, 2025As large language models (LLMs) are increasingly deployed in high-stakes settings, the risk of generating harmful or toxic content remains a central challenge. Post-hoc alignment methods are brittle: once unsafe patterns are learned during pretraining, they are hard to remove. We present a data-centric pretraining framework that builds safety into the model from the start. Our contributions include: (i) a safety classifier trained on 10,000 GPT-4 labeled examples, used to filter 600B tokens; (ii) the largest synthetic safety dataset to date (100B tokens) generated via recontextualization of harmful web data; (iii) RefuseWeb and Moral Education datasets that convert harmful prompts into refusal dialogues and web-style educational material; (iv) Harmfulness-Tag annotations injected during pretraining to flag unsafe content and steer away inference from harmful generations; and (v) safety evaluations measuring base model behavior before instruction tuning. Our safety-pretrained models reduce attack success rates from 38.8% to 8.4% with no performance degradation on standard LLM safety benchmarks.
Looking beyond the next token
Apr 15, 2025The structure of causal language model training assumes that each token can be accurately predicted from the previous context. This contrasts with humans' natural writing and reasoning process, where goals are typically known before the exact argument or phrasings. While this mismatch has been well studied in the literature, the working assumption has been that architectural changes are needed to address this mismatch. We argue that rearranging and processing the training data sequences can allow models to more accurately imitate the true data-generating process, and does not require any other changes to the architecture or training infrastructure. We demonstrate that this technique, Trelawney, and the inference algorithms derived from it allow us to improve performance on several key benchmarks that span planning, algorithmic reasoning, and story generation tasks. Finally, our method naturally enables the generation of long-term goals at no additional cost. We investigate how using the model's goal-generation capability can further improve planning and reasoning. Additionally, we believe Trelawney could potentially open doors to new capabilities beyond the current language modeling paradigm.
Training a Generally Curious Agent
Feb 24, 2025



Efficient exploration is essential for intelligent systems interacting with their environment, but existing language models often fall short in scenarios that require strategic information gathering. In this paper, we present PAPRIKA, a fine-tuning approach that enables language models to develop general decision-making capabilities that are not confined to particular environments. By training on synthetic interaction data from different tasks that require diverse strategies, PAPRIKA teaches models to explore and adapt their behavior on a new task based on environment feedback in-context without more gradient updates. Experimental results show that models fine-tuned with PAPRIKA can effectively transfer their learned decision-making capabilities to entirely unseen tasks without additional training. Unlike traditional training, our approach's primary bottleneck lies in sampling useful interaction data instead of model updates. To improve sample efficiency, we propose a curriculum learning strategy that prioritizes sampling trajectories from tasks with high learning potential. These results suggest a promising path towards AI systems that can autonomously solve novel sequential decision-making problems that require interactions with the external world.
Adaptive Data Optimization: Dynamic Sample Selection with Scaling Laws
Oct 15, 2024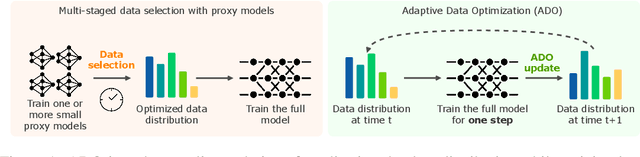
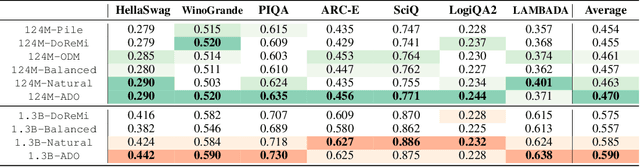
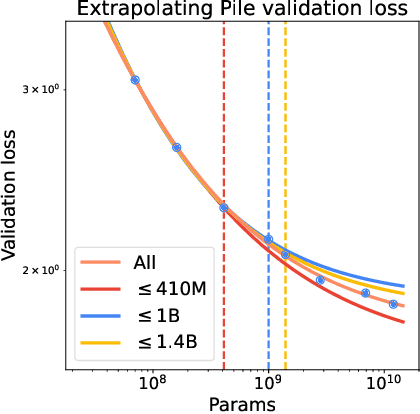
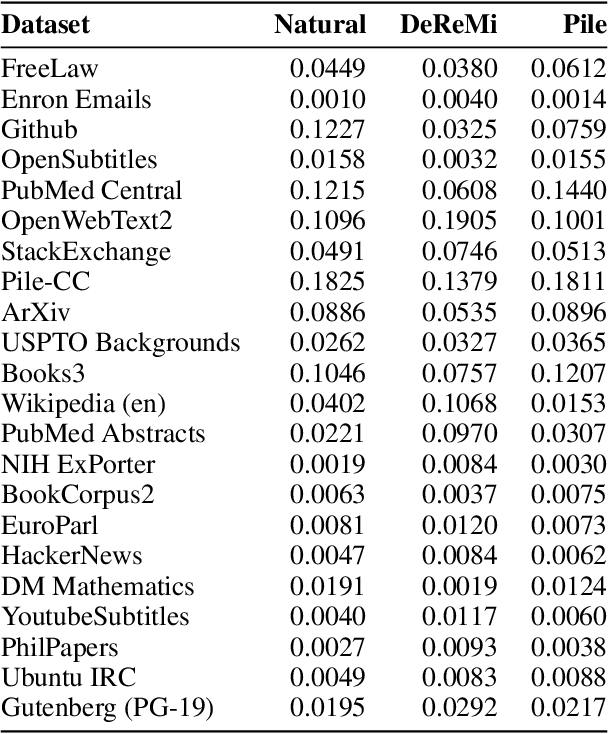
The composition of pretraining data is a key determinant of foundation models' performance, but there is no standard guideline for allocating a limited computational budget across different data sources. Most current approaches either rely on extensive experiments with smaller models or dynamic data adjustments that also require proxy models, both of which significantly increase the workflow complexity and computational overhead. In this paper, we introduce Adaptive Data Optimization (ADO), an algorithm that optimizes data distributions in an online fashion, concurrent with model training. Unlike existing techniques, ADO does not require external knowledge, proxy models, or modifications to the model update. Instead, ADO uses per-domain scaling laws to estimate the learning potential of each domain during training and adjusts the data mixture accordingly, making it more scalable and easier to integrate. Experiments demonstrate that ADO can achieve comparable or better performance than prior methods while maintaining computational efficiency across different computation scales, offering a practical solution for dynamically adjusting data distribution without sacrificing flexibility or increasing costs. Beyond its practical benefits, ADO also provides a new perspective on data collection strategies via scaling laws.
Improving Generalization on the ProcGen Benchmark with Simple Architectural Changes and Scale
Oct 13, 2024
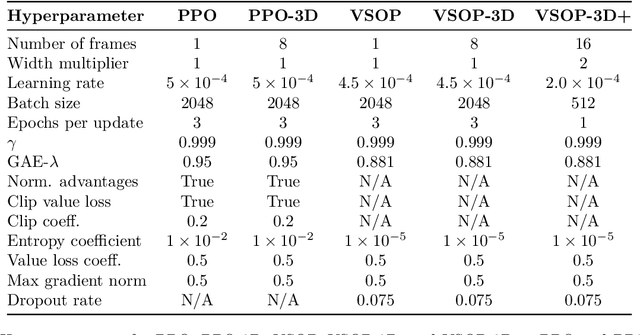

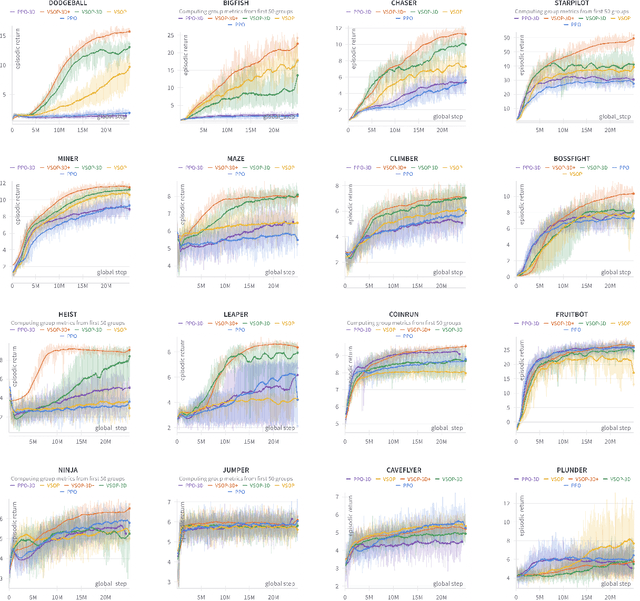
We demonstrate that recent advances in reinforcement learning (RL) combined with simple architectural changes significantly improves generalization on the ProcGen benchmark. These changes are frame stacking, replacing 2D convolutional layers with 3D convolutional layers, and scaling up the number of convolutional kernels per layer. Experimental results using a single set of hyperparameters across all environments show a 37.9\% reduction in the optimality gap compared to the baseline (from 0.58 to 0.36). This performance matches or exceeds current state-of-the-art methods. The proposed changes are largely orthogonal and therefore complementary to the existing approaches for improving generalization in RL, and our results suggest that further exploration in this direction could yield substantial improvements in addressing generalization challenges in deep reinforcement learning.
Automated Black-box Prompt Engineering for Personalized Text-to-Image Generation
Mar 28, 2024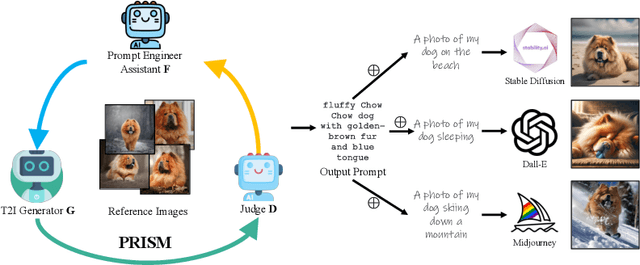
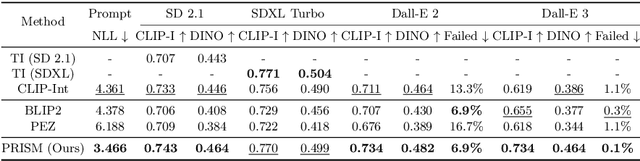
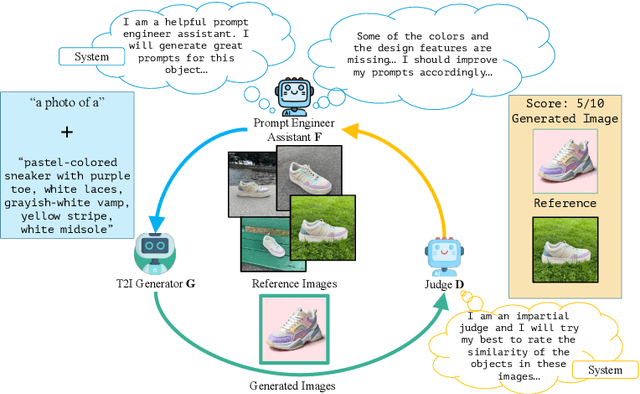
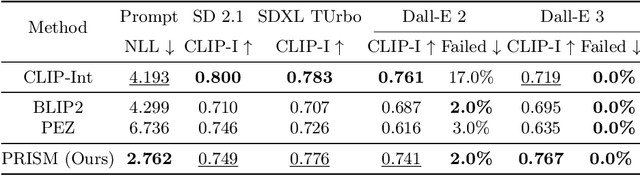
Prompt engineering is effective for controlling the output of text-to-image (T2I) generative models, but it is also laborious due to the need for manually crafted prompts. This challenge has spurred the development of algorithms for automated prompt generation. However, these methods often struggle with transferability across T2I models, require white-box access to the underlying model, and produce non-intuitive prompts. In this work, we introduce PRISM, an algorithm that automatically identifies human-interpretable and transferable prompts that can effectively generate desired concepts given only black-box access to T2I models. Inspired by large language model (LLM) jailbreaking, PRISM leverages the in-context learning ability of LLMs to iteratively refine the candidate prompts distribution for given reference images. Our experiments demonstrate the versatility and effectiveness of PRISM in generating accurate prompts for objects, styles and images across multiple T2I models, including Stable Diffusion, DALL-E, and Midjourney.
Understanding prompt engineering may not require rethinking generalization
Oct 06, 2023
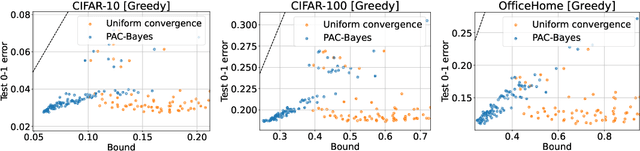
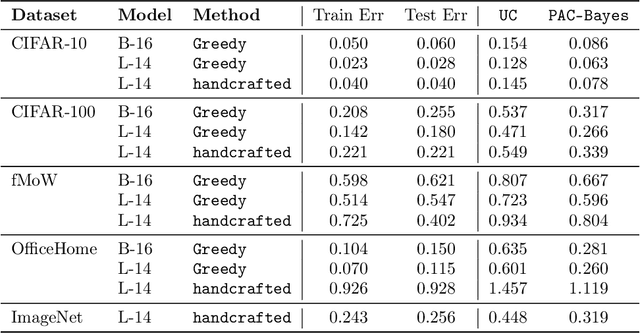
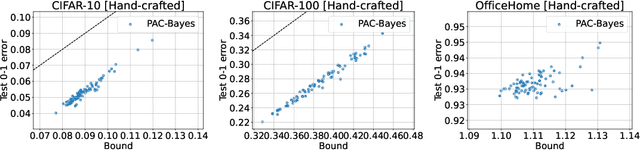
Zero-shot learning in prompted vision-language models, the practice of crafting prompts to build classifiers without an explicit training process, has achieved impressive performance in many settings. This success presents a seemingly surprising observation: these methods suffer relatively little from overfitting, i.e., when a prompt is manually engineered to achieve low error on a given training set (thus rendering the method no longer actually zero-shot), the approach still performs well on held-out test data. In this paper, we show that we can explain such performance well via recourse to classical PAC-Bayes bounds. Specifically, we show that the discrete nature of prompts, combined with a PAC-Bayes prior given by a language model, results in generalization bounds that are remarkably tight by the standards of the literature: for instance, the generalization bound of an ImageNet classifier is often within a few percentage points of the true test error. We demonstrate empirically that this holds for existing handcrafted prompts and prompts generated through simple greedy search. Furthermore, the resulting bound is well-suited for model selection: the models with the best bound typically also have the best test performance. This work thus provides a possible justification for the widespread practice of prompt engineering, even if it seems that such methods could potentially overfit the training data.
Language models are weak learners
Jun 25, 2023A central notion in practical and theoretical machine learning is that of a $\textit{weak learner}$, classifiers that achieve better-than-random performance (on any given distribution over data), even by a small margin. Such weak learners form the practical basis for canonical machine learning methods such as boosting. In this work, we illustrate that prompt-based large language models can operate effectively as said weak learners. Specifically, we illustrate the use of a large language model (LLM) as a weak learner in a boosting algorithm applied to tabular data. We show that by providing (properly sampled according to the distribution of interest) text descriptions of tabular data samples, LLMs can produce a summary of the samples that serves as a template for classification and achieves the aim of acting as a weak learner on this task. We incorporate these models into a boosting approach, which in some settings can leverage the knowledge within the LLM to outperform traditional tree-based boosting. The model outperforms both few-shot learning and occasionally even more involved fine-tuning procedures, particularly for tasks involving small numbers of data points. The results illustrate the potential for prompt-based LLMs to function not just as few-shot learners themselves, but as components of larger machine learning pipelines.