 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage models are weak learners
Jun 25, 2023A central notion in practical and theoretical machine learning is that of a $\textit{weak learner}$, classifiers that achieve better-than-random performance (on any given distribution over data), even by a small margin. Such weak learners form the practical basis for canonical machine learning methods such as boosting. In this work, we illustrate that prompt-based large language models can operate effectively as said weak learners. Specifically, we illustrate the use of a large language model (LLM) as a weak learner in a boosting algorithm applied to tabular data. We show that by providing (properly sampled according to the distribution of interest) text descriptions of tabular data samples, LLMs can produce a summary of the samples that serves as a template for classification and achieves the aim of acting as a weak learner on this task. We incorporate these models into a boosting approach, which in some settings can leverage the knowledge within the LLM to outperform traditional tree-based boosting. The model outperforms both few-shot learning and occasionally even more involved fine-tuning procedures, particularly for tasks involving small numbers of data points. The results illustrate the potential for prompt-based LLMs to function not just as few-shot learners themselves, but as components of larger machine learning pipelines.
Assessing Validity of Static Analysis Warnings using Ensemble Learning
Apr 21, 2021


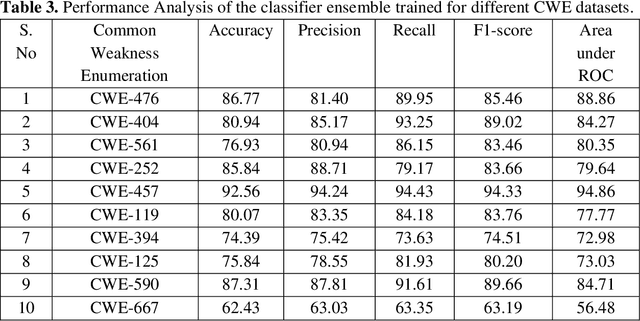
Static Analysis (SA) tools are used to identify potential weaknesses in code and fix them in advance, while the code is being developed. In legacy codebases with high complexity, these rules-based static analysis tools generally report a lot of false warnings along with the actual ones. Though the SA tools uncover many hidden bugs, they are lost in the volume of fake warnings reported. The developers expend large hours of time and effort in identifying the true warnings. Other than impacting the developer productivity, true bugs are also missed out due to this challenge. To address this problem, we propose a Machine Learning (ML)-based learning process that uses source codes, historic commit data, and classifier-ensembles to prioritize the True warnings from the given list of warnings. This tool is integrated into the development workflow to filter out the false warnings and prioritize actual bugs. We evaluated our approach on the networking C codes, from a large data pool of static analysis warnings reported by the tools. Time-to-time these warnings are addressed by the developers, labelling them as authentic bugs or fake alerts. The ML model is trained with full supervision over the code features. Our results confirm that applying deep learning over the traditional static analysis reports is an assuring approach for drastically reducing the false positive rates.
Multi-context Attention Fusion Neural Network for Software Vulnerability Identification
Apr 19, 2021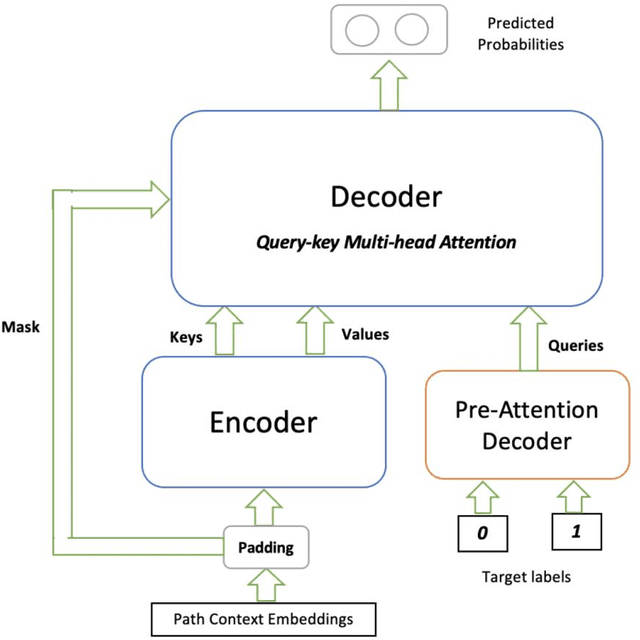


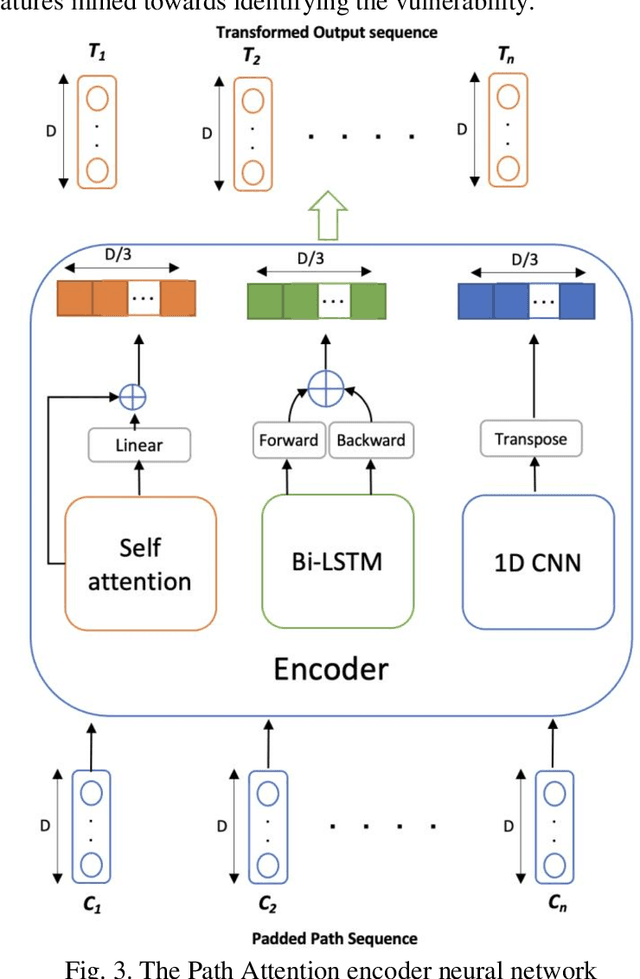
Security issues in shipped code can lead to unforeseen device malfunction, system crashes or malicious exploitation by crackers, post-deployment. These vulnerabilities incur a cost of repair and foremost risk the credibility of the company. It is rewarding when these issues are detected and fixed well ahead of time, before release. Common Weakness Estimation (CWE) is a nomenclature describing general vulnerability patterns observed in C code. In this work, we propose a deep learning model that learns to detect some of the common categories of security vulnerabilities in source code efficiently. The AI architecture is an Attention Fusion model, that combines the effectiveness of recurrent, convolutional and self-attention networks towards decoding the vulnerability hotspots in code. Utilizing the code AST structure, our model builds an accurate understanding of code semantics with a lot less learnable parameters. Besides a novel way of efficiently detecting code vulnerability, an additional novelty in this model is to exactly point to the code sections, which were deemed vulnerable by the model. Thus helping a developer to quickly focus on the vulnerable code sections; and this becomes the "explainable" part of the vulnerability detection. The proposed AI achieves 98.40% F1-score on specific CWEs from the benchmarked NIST SARD dataset and compares well with state of the art.