 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Validity of Static Analysis Warnings using Ensemble Learning
Paper and Code
Apr 21, 2021


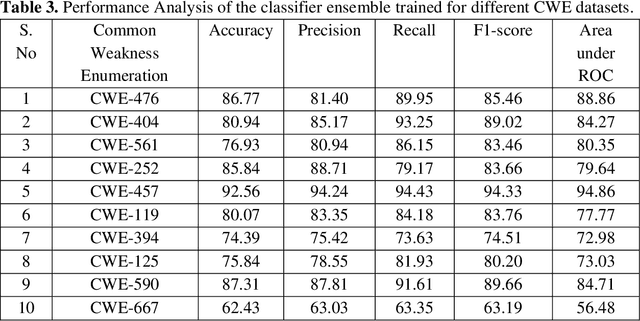
Static Analysis (SA) tools are used to identify potential weaknesses in code and fix them in advance, while the code is being developed. In legacy codebases with high complexity, these rules-based static analysis tools generally report a lot of false warnings along with the actual ones. Though the SA tools uncover many hidden bugs, they are lost in the volume of fake warnings reported. The developers expend large hours of time and effort in identifying the true warnings. Other than impacting the developer productivity, true bugs are also missed out due to this challenge. To address this problem, we propose a Machine Learning (ML)-based learning process that uses source codes, historic commit data, and classifier-ensembles to prioritize the True warnings from the given list of warnings. This tool is integrated into the development workflow to filter out the false warnings and prioritize actual bugs. We evaluated our approach on the networking C codes, from a large data pool of static analysis warnings reported by the tools. Time-to-time these warnings are addressed by the developers, labelling them as authentic bugs or fake alerts. The ML model is trained with full supervision over the code features. Our results confirm that applying deep learning over the traditional static analysis reports is an assuring approach for drastically reducing the false positive rates.